
Машинен превод
Какво представлява машинен превод?
Системите за машинен превод са приложения или онлайн услуги, които използват технологии за машинно обучение, за да преведат големи количества текст от и на някой от поддържаните от тях езици. Услугата превежда "източник" текст от един език на друг "TARGET" език.
Въпреки че концепциите зад технологията за машинен превод и интерфейсите за използването му са относително прости, науката и технологиите зад нея са изключително сложни и обединяват няколко водещи технологии, по-специално дълбоко обучение ( данни, лингвистиката, изчисленията в облак и уеб API.
От началото на 2010 г. новата технология за изкуствен интелект, дълбоките невронни мрежи (известна още като дълбоко обучение), позволи на технологията за разпознаване на реч да достигне ниво на качество, което позволява на екипа на Microsoft преводач да комбинира разпознаването на реч със своите технология за превод на основен текст, за да започне нова технология за превод на реч.
В исторически план, техниката за основно машинно обучение, използвана в индустрията, е статистически машинен превод (SMT). SMT използва усъвършенстван статистически анализ за оценка на най-добрите възможни преводи за една дума, като се има предвид контекстът на няколко думи. SMT се използва от средата на 2000-те години на всички големи доставчици на преводачески услуги, включително Microsoft.
Появата на неврална машина Превод (NMT) предизвика радикална промяна в преводаческа технология, което води до много по-високо качество преводи. Тази технология за превод започна разполагането на потребители и разработчици в Последната част от 2016.
И технологиите за превод SMT и NMT имат два общи елемента:
- И двете изискват големи количества предварително преведени съдържание (до милиони преведени изречения) за обучение на системите.
- Нито действат като двуезични речници, превеждайки думи въз основа на списък с потенциални преводи, а превеждат въз основа на контекста на думата, която се използва в изречението.
Какво е преводач?
услуги за преводач и реч, част от Когнитивни услуги събиране на API, са услуги за машинен превод от Microsoft.
Превод на текст
Преводач се използва от групи на Microsoft от 2007 г. и се предлага като API за клиенти от 2011 г. насам. Преводачът се използва широко в рамките на Microsoft. Тя е включена в различни продуктови локализация, поддръжка и онлайн комуникационни екипи. Същата тази услуга също е достъпна, без допълнителни разходи, от рамките на познати продукти на Microsoft като Бинг, Cortana, Microsoft Edge, Офис, Sharepoint, Skypeи Yammer.
Преводачът може да се използва в уеб или клиентски приложения на всяка хардуерна платформа и с всяка операционна система, за да извършва езиков превод и други езикови операции като откриване на език, текст в реч или речник.
Привличане на индустрията Стандартна REST технология, разработчик изпраща изходен текст (или аудио за говор превод) на услугата с параметър показва целевия език, и услугата изпраща обратно преведен текст за клиента или уеб приложението да се използва.
Услугата за преводач е Azure услуга, хоствана в центрове за данни на Microsoft и се ползва от защитата, мащабируемостта, надеждността и безпрекъсване на достъпността, които други услуги в облака на Microsoft също получават.
Превод на реч
Технологията за превод на речта е стартирана в края на 2014 г. и започва с преводача на Skype, и е достъпна като отворен API за клиентите от началото на 2016 г. Той е интегриран в функцията на Microsoft Translator live, Skype, Skype събрание излъчване и приложенията на Microsoft Преводач за Android и iOS.
Преводът на реч вече е достъпен чрез речта на Microsoft, набор от край до край на напълно адаптивни услуги за разпознаване на реч, превод на реч и синтез на реч (текст към реч).
Как работи преводът на текст?
Има две основни технологии, използвани за превод на текст: стари, статистически машинен превод (SMT), и по-нова генерация един, превод на невронни машина (NMT).
Статистически машинен превод
Внедряването на статистическия машинен превод на преводача (SMT) се основава на повече от десетилетие естествени езикови изследвания в Microsoft. Вместо да пишат ръчно изработени правила за превод между езиците, съвременните системи за превод подхождат към превода като проблем за изучаване на трансформирането на текст между езиците от съществуващите човешки преводи и да се използва съвременният напредък в приложната статистика и машинното обучение.
Така наречените "паралелни корпуси" действат като модерен Розетен Камък в масивни пропорции, като предоставят слово, фраза и идиоматични преводи в контекст за много езикови двойки и области. Техниките за статистическо моделиране и ефективните алгоритми помагат на компютъра да се справи с проблема с дешифрирането (откриване на кореспонденцията между изходния и целевия език в данните за обучението) и декодиране (намиране на най-добрия превод на ново входно изречение). Преводачобединява силата на статистическите методи с езикова информация, за да създаде модели, които обобщават по-добре и водят до по-разбираеми преводи.
Поради този подход, който не разчита на речници или граматични правила, той осигурява най-добрите преводи на фрази, където може да се използва контекстът около дадена дума срещу опит за извършване на една дума преводи. За преводи на единични думи Двуезичният речник е разработен и е достъпен чрез www.Bing.com/Translator.
Превод на невронни машини
Важни са непрекъснатите подобрения в превода. Въпреки това, подобренията в производителността са платуени с SMT технологията от средата на 2010 г. насам. Чрез привличане на мащаба и силата на суперкомпютъра на Microsoft AI, по-специално Microsoft Познавателен инструментариум, Преводач сега предлага невронна мрежа ("ЛСПМ") превод, който дава възможност за ново десетилетие на подобряване на качеството на превода.
Тези невронни мрежови модели са достъпни за всички езици за говор чрез услугата за говор на Azure и чрез API на текст с помощта на "generalnn" категория ИД.
Невралната мрежа преводи фундаментално се различават по начина, по който те се извършват в сравнение с традиционните SMT такива.
Следната анимация изобразява различни стъпки невронни мрежови преводи преминават към превод на изречение. Поради този подход, преводът ще вземе в контекста на пълното изречение, срещу само няколко думи плъзгащи прозорец, че SMT технология използва и ще произвежда повече течности и човешки преведени търси преводи.
Въз основа на обучението на невронната мрежа, всяка дума се кодира по вектор 500-размери (а) представляващ уникалните му характеристики в рамките на определена езикова двойка (напр. английски и китайски). Въз основа на езиковите двойки, използвани за обучение, невронната мрежа ще се самодефинира какво трябва да бъдат тези измерения. Те могат да кодират прости понятия като Пол (женствен, мъжки, неутрален), ниво на учтивост (жаргон, случаен, писмен, формален и т. н.), вид на думата (глагол, съществително и т. н.), но и всякакви други неочевидни характеристики, извлечени от данните за обучение.
Стъпките невронни мрежови преводи преминават са следните:
- Всяка дума, или по-специално 500-размерният вектор, който го представлява, преминава през първия слой от "неврони", който ще го кодира в 1000-размерен вектор (б) представляващ думата в контекста на другите думи в изречението.
- След като всички думи са кодирани един път в тези 1000-размерни векторите, процесът се повтаря няколко пъти, всеки слой позволява по-добра фина настройка на това 1000-измерение на думата в контекста на пълното изречение (противно на SMT технология, която може да вземе предвид само един прозорец от 3 до 5 думи)
- След това крайната изходна матрица се използва от слоя на вниманието (т. е. софтуерен алгоритъм), който ще използва както тази крайна изходна матрица, така и готовата продукция от предварително преведени думи, за да определи коя дума от изречението източник трябва да бъде преведена следваща. Той също така ще използва тези изчисления, за да може да хвърли ненужни думи на целевия език.
- Слой на декодер (превод), превежда избраната дума (или по-специално 1000-измерение вектор, представляващ тази дума в контекста на пълното изречение) в своя най-подходящия целеви език еквивалент. След това изходът на последния слой (c) се връща обратно в слоя на вниманието, за да се изчисли коя следваща дума от изречението източник трябва да бъде преведена.

В примера, изобразен в анимацията, контекстът с 1000-размерност модел на "на"ще кодира, че съществителното (Къща) е женска дума на френски език (La Maison). Това ще даде възможност за подходящ превод за "на"да бъде"La"а не"Le"(единствено за мъже) или"Les"(множествено число), след като достигне слоя на декодера (превода).
Алгоритъмът за внимание също ще изчисли, въз основа на думата (и), преведени преди това (в този случай "на"), че следващата дума, която трябва да бъде преведена, следва да бъде предмет ("Къща"), а не прилагателно ("Синьо"). В това може да се постигне това, защото системата научил, че английски и френски обръщане на реда на тези думи в изречения. Тя също така би изчислила, че ако прилагателното е "Голям"вместо цвят, че не трябва да ги Инвертиране ("голямата къща"= >"La Grande Maison").
Благодарение на този подход, в повечето случаи крайният резултат е по-добре и по-близо до човешки превод, отколкото може да е бил всеки превод, основан на SMT.
Как работи преводът на реч?
Преводачът също е способен да превежда реч. Тази технология е изложена в функцията на преводач live (http://translate.it), приложения преводач, преводач на Skype и също така първоначално се предоставя само чрез функцията за преводач на Skype и в приложенията на Microsoft преводач на iOS и Android, тази функционалност вече е достъпна за разработчиците с най-новата версия на отворения Базиран на REST API, наличен на портала на Azure.
Въпреки че може да изглежда като директен процес на пръв поглед за изграждане на технология за превод на реч от съществуващите технологични тухли, тя изисква много повече работа, отколкото просто включване на съществуващо "традиционно" разпознаване на реч от човек към машина към съществуващия текстов превод един.
За да преведат правилно речта "източник" от един език на различен "целеви" език, системата преминава през четиристъпковият процес.
- Разпознаване на реч, конвертиране на аудио в текст
- TrueText: технология на Microsoft, която нормализира текста, за да го направи по-подходящ за превод
- Превод чрез машината за превод на текст, описана по-горе, но на модели за превод, специално разработени за истински житейски разговори
- Текст-към-реч, когато е необходимо, за да се произведе Преведено аудио.

Автоматично разпознаване на реч (ASR)
Автоматичното разпознаване на реч (ASR) се извършва с помощта на система от невронни мрежи (NN), обучена да анализира хилядите часове входяща аудио реч. Този модел е обучен за човешки взаимодействия, а не за човешки команди, създавайки разпознаване на реч, което е оптимизирано за нормални разговори. За да се постигне това, са необходими много повече данни, както и по-голяма DNN от традиционните ASRs.
Научете повече за Реч на Microsoft за текстови услуги.
Раб.
Когато хората разговарят с други хора, ние не говорим перфектно, ясно или спретнато, както често мислим, че правим. С технологията TrueText Буквалният текст се трансформира, за да отразява по-добре намеренията на потребителите, като премахва дефластиите на говора (думите за пълнене), като "UM" s, "Ah" s, "и" s, "като" s, заеква и повторения. Текстът също така се прави по-четлив и преведящ чрез добавяне на прекъсвания на изречения, правилна пунктуация и главни букви. За да постигнем тези резултати, използвахме десетилетия работа по езикови технологии, разработихме от преводач за създаване на TrueText. Следната диаграма изобразява чрез истински пример различните трансформации на TrueText работи за нормализиране на този буквален текст.
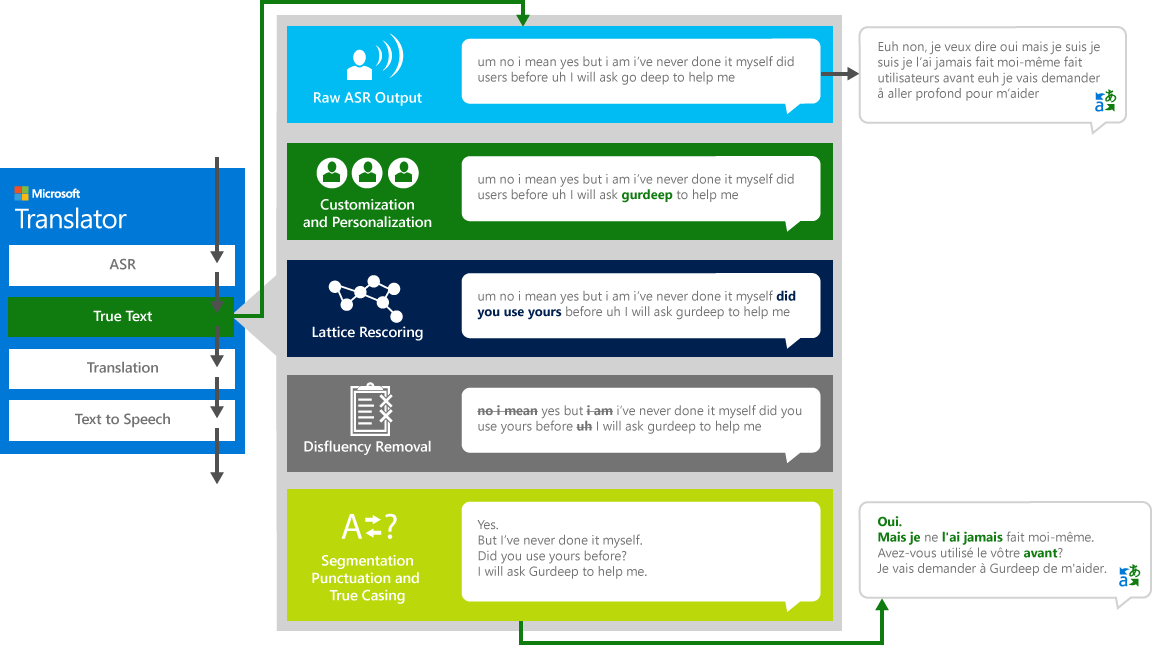
Превод
След това текстът се превежда в езици и диалекти поддържана от Преводач.
Преводите, използващи API за превод на реч (като разработчик) или в приложение или услуга за транслиране на реч, се захранват с най-новия базиран на невронни мрежа превод за всички поддържани езици за говор (вж. тук за пълния списък). Тези модели също са изградени чрез разширяване на текущите, най-вече написани-текст обучени модели за превод, с по-говорни-текстови групи, за да се изгради по-добър модел за говорни видове разговори на преводи. Тези модели са достъпни и чрез Стандартна категория "реч" на традиционния API за превод на текст.
За всички езици, които не се поддържат от неврален превод, се извършва традиционен превод на SMT.
Текст в реч
Ако целевият език е един от 18-те поддържани Езици, а случаят на използване изисква аудио изход, текстът се преобразува в говор изход чрез синтез на реч. Този етап е пропуснат в сценариите за превод "реч към текст".
Научете повече за Текст на Microsoft в услугите за говор.
Изследвания
Преглед на най-новите изследователски документи от екипа на Microsoft преводач.



