
Maskinoversættelse
Hvad er maskinoversættelse?
Maskinoversættelsessystemer er programmer eller onlinetjenester, der bruger maskin lærings teknologier til at oversætte store mængder tekst fra og til et hvilket som helst af deres understøttede sprog. Tjenesten oversætter en "kilde"-tekst fra et sprog til et andet "målsprog".
Selv om begreberne bag maskin oversættelses teknologien og grænsefladerne til at bruge den er relativt enkle, er videnskaben og teknologien bag den yderst komplekse og samler flere førende teknologier, især dyb indlæring ( kunstig intelligens), Big data, lingvistik, cloudcomputing og Web API'er.
Siden begyndelsen af 2010s, en ny kunstig intelligens teknologi, dybe neurale netværk (alias dyb læring), har gjort det muligt for teknologien i talegenkendelse til at nå et kvalitetsniveau, der tillod Microsoft Translator team til at kombinere talegenkendelse med sin kernetekst oversættelsesteknologi til at lancere en ny tale oversættelsesteknologi.
Historisk set var den primære maskin indlæringsteknik, der anvendes i branchen, statistisk maskinoversættelse (SMT). SMT bruger avanceret statistisk analyse til at estimere de bedst mulige oversættelser for et ord i lyset af konteksten af et par ord. SMT har været anvendt siden midten af 2000 ' erne af alle større oversættelsestjeneste udbydere, herunder Microsoft.
Fremkomsten af Neural maskinoversættelse (NMT) forårsagede et radikalt skift i oversættelses teknologien, hvilket resulterede i meget højere kvalitet oversættelser. Denne oversættelsesteknologi begyndte at implementere for brugere og udviklere i sidste del af 2016.
Både SMT og NMT oversættelses teknologier har to elementer til fælles:
- Begge kræver store mængder af præ-menneskeligt oversat indhold (op til millioner af oversatte sætninger) til at træne systemerne.
- Hverken fungere som tosprogede ordbøger, omsætte ord baseret på en liste over mulige oversættelser, men oversat baseret på konteksten af det ord, der anvendes i en sætning.
Hvad er Translator?
Oversætter- og taletjenester, en del af Kognitive tjenester samling af API'er, er maskinoversættelsestjenester fra Microsoft.
Oversættelse af tekst
Translator har været brugt af Microsoft-grupper siden 2007 og er tilgængelig som API for kunder siden 2011. Oversætter bruges i vid udstrækning i Microsoft. Det er indarbejdet på tværs af produktlokalisering, support og online kommunikationsteams. Den samme tjeneste er også tilgængelig uden ekstra omkostninger fra velkendte Microsoft-produkter, f.eks. Bing, Cortana, Microsoft Edge, Office, Sharepoint, Skypeog Yammer.
Oversætter kan bruges i web- eller klientprogrammer på enhver hardwareplatform og med ethvert operativsystem til at udføre sprogoversættelse og andre sprogrelaterede handlinger, f.eks.
Ved at udnytte branchens standard REST-teknologi sender udvikleren kildetekst (eller lyd til tale oversættelse) til tjenesten med en parameter, der angiver målsproget, og tjenesten sender den oversatte tekst tilbage til den klient eller WebApp, der skal bruges.
Oversættertjenesten er en Azure-tjeneste, der hostes i Microsofts datacentre, og nyder godt af den sikkerhed, skalerbarhed, pålidelighed og nonstop-tilgængelighed, som andre Microsoft-skytjenester også modtager.
Tale Oversættelse
Oversætterens taleoversættelsesteknologi blev lanceret i slutningen af 2014 med start med Skype Translator og er tilgængelig som en åben API for kunder siden begyndelsen af 2016. Det er integreret i Microsoft Translator live-funktionen, Skype, Skype-mødeudsendelse og Microsoft Translator-apps til Android og iOS.
Tale oversættelse er nu tilgængelig via Microsoft Speech, som er et komplet sæt af tjenester, der kan tilpasses til talegenkendelse, tale oversættelse og talesyntese (tekst-til-tale).
Hvordan fungerer tekst Oversættelse?
Der er to vigtigste teknologier, der anvendes til oversættelse af tekst: den arv, statistisk maskinoversættelse (SMT), og den nyere generation en, Neural maskinoversættelse (NMT).
Statistisk maskinoversættelse
Translator's implementering af Statistical Machine Translation (SMT) bygger på mere end et årti ser på natursprogsforskning hos Microsoft. I stedet for at skrive håndlavede regler for at oversætte mellem sprog, tilgang moderne oversættelsessystemer oversættelse som et problem med at lære omdannelsen af tekst mellem sprog fra eksisterende menneskelige oversættelser og udnytte de seneste fremskridt inden for anvendt statistik og maskinlæring.
Såkaldte "parallel corpora" fungere som en moderne Rosetta Stone i massive proportioner, der giver ord, sætning og idiomatiske oversættelser i sammenhæng for mange sprogpar og domæner. Statistiske modelleringsteknikker og effektive algoritmer hjælper computeren med at løse problemet med dechifrering (påvisning af korrespondancer mellem kilde- og målsprog i træningsdataene) og afkodning (finde den bedste oversættelse af en ny inputsætning). Oversætter forener de statistiske metoders evne til at udvikle sproglige oplysninger for at producere modeller, der generaliserer bedre og fører til mere forståelige oversættelser.
På grund af denne fremgangsmåde, som ikke er baseret på ordbøger eller grammatiske regler, giver den de bedste oversættelser af sætninger, hvor den kan bruge konteksten omkring et givent ord versus at forsøge at udføre enkelte ord oversættelser. For enkelt ord oversættelser blev den tosprogede ordbog udviklet og er tilgængelig gennem www.Bing.com/Translator.
Neural maskinoversættelse
Løbende forbedringer af oversættelsen er vigtige. Men, forbedringer af ydeevnen har plateaued med SMT-teknologi siden midten af 2010'erne. Ved at udnytte omfanget og styrken af Microsofts AI supercomputer, specielt Microsoft Cognitive Toolkit, Translator tilbyder nu neurale netværk (LSTM) baseret oversættelse, der muliggør et nyt årti af oversættelseskvalitet forbedring.
Disse neurale netværksmodeller er tilgængelige for alle talesprog via Taletjenesten på Azure og via tekst-API'en ved hjælp af kategori-id'et 'generalnn'.
Neurale netværk oversættelser fundamentalt adskiller sig i, hvordan de udføres i forhold til de traditionelle SMT dem.
Følgende animation skildrer de forskellige trin neurale netværk oversættelser gå igennem for at oversætte en sætning. På grund af denne tilgang, vil oversættelsen tage i sammenhæng den fulde sætning, versus kun et par ord glidende vindue, at SMT teknologi bruger og vil producere mere flydende og menneske-oversat udseende oversættelser.
Baseret på neurale netværk uddannelse, er hvert ord kodet langs en 500-dimensioner vektor (a) repræsenterer sine unikke egenskaber inden for et bestemt sprogpar (f. eks engelsk og kinesisk). Baseret på de sprogpar, der bruges til træning, vil det neurale netværk selv definere, hvad disse dimensioner skal være. De kunne kode simple begreber som køn (feminin, maskulin, neutral), høflighed niveau (slang, afslappet, skriftlig, formel, osv.), type ord (udsagnsord, substantiv, osv.), men også alle andre ikke-indlysende egenskaber, som stammer fra uddannelsesdata.
Trinene neurale netværk oversættelser gå igennem, er følgende:
- Hvert ord, eller mere specifikt den 500-dimension vektor, der repræsenterer det, går gennem et første lag af "neuroner", der vil indkode det i en 1000-dimension vektor (b), der repræsenterer ordet inden for rammerne af de andre ord i sætningen.
- Når alle ord er blevet kodet en gang ind i disse 1000-dimension vektorer, processen gentages flere gange, hvert lag giver bedre finjustering af denne 1000-dimension repræsentation af ordet inden for rammerne af den fulde sætning (i modsætning til SMT teknologi, der kun kan tage hensyn til en 3 til 5 ord vindue)
- Den endelige output matrix bruges derefter af opmærksomheds laget (dvs. en software algoritme), der vil bruge både denne endelige output matrix og outputtet af tidligere oversatte ord til at definere, hvilket ord, fra kilde sætningen, skal oversættes næste. Det vil også bruge disse beregninger til potentielt droppe unødvendige ord på målsproget.
- Dekoderen (oversættelse) lag, oversætter det valgte ord (eller mere specifikt den 1000-dimension vektor, der repræsenterer dette ord inden for rammerne af den fulde sætning) i sit mest passende målsprog tilsvarende. Outputtet af dette sidste lag (c) bliver derefter fodret tilbage i opmærksomheds laget for at beregne, hvilket næste ord fra kilde sætningen skal oversættes.

I eksemplet, der er afbildet i animationen, er den kontekstbevidste 1000-dimensions model "den"vil indkode, at navneord (House) er et feminint ord på fransk (La Maison). Dette vil give mulighed for en passende oversættelse til "den"at være"La"og ikke"Le"(ental, mandlig) eller"Les"(flertal), når den når dekoderen (oversættelse) lag.
Den opmærksomhed algoritme vil også beregne, baseret på de ord (r) tidligere oversat (i dette tilfælde "den"), at det næste ord, der skal oversættes, skal være emnet ("House") og ikke et adjektiv ("Blå"). I kan opnå dette, fordi systemet lærte, at engelsk og fransk inverterer rækkefølgen af disse ord i sætninger. Det ville også have beregnet, at hvis adjektivet skulle være "Store"i stedet for en farve, at det ikke bør invertere dem ("det store hus"= >"La Grande Maison").
Takket være denne fremgangsmåde er det endelige output i de fleste tilfælde mere flydende og tættere på en menneskelig oversættelse end en SMT-baseret oversættelse kunne nogensinde have været.
Hvordan fungerer tale Oversættelse?
Oversætter er også i stand til at oversætte tale. Denne teknologi er eksponeret i Translator live-funktionen (http://translate.it), oversætteren apps, Skype Translator og er også oprindeligt gjort tilgængelig via Skype Translator funktion og i Microsoft Translator apps på iOS og Android, denne funktionalitet er nu tilgængelig for udviklere med den nyeste version af den åbne REST-baseret API, der er tilgængelig på Azure-portalen.
Selv om det kan virke som en ligetil proces ved første øjekast at opbygge en tale oversættelsesteknologi fra de eksisterende teknologi mursten, det krævede meget mere arbejde end blot at tilslutte en eksisterende "traditionelle" menneske-til-maskine talegenkendelse til den eksisterende tekst Oversættelse.
For korrekt at oversætte "kilde" tale fra et sprog til et andet "target" sprog, systemet går gennem en fire-trins proces.
- Talegenkendelse til at konvertere lyd til tekst
- TrueText: en Microsoft-teknologi, der normaliserer teksten for at gøre den mere velegnet til oversættelse
- Oversættelse gennem tekst oversættelses programmet beskrevet ovenfor, men på oversættelses modeller, der er specielt udviklet til samtaler i det virkelige liv
- Tekst-til-tale, når det er nødvendigt, for at producere den oversatte lyd.

Automatisk talegenkendelse (ASR)
Automatisk talegenkendelse (ASR) udføres ved hjælp af et system til neurale netværk (NN), der er trænet i at analysere tusindvis af timers indgående lydtale. Denne model er uddannet på menneske-til-menneske-interaktioner snarere end menneske-til-maskine kommandoer, der producerer talegenkendelse, der er optimeret til normale samtaler. For at opnå dette er der behov for langt flere data og en større DNN end traditionelle humane-til-maskine-Asr'er.
Læs mere om Microsofts tale til teksttjenester.
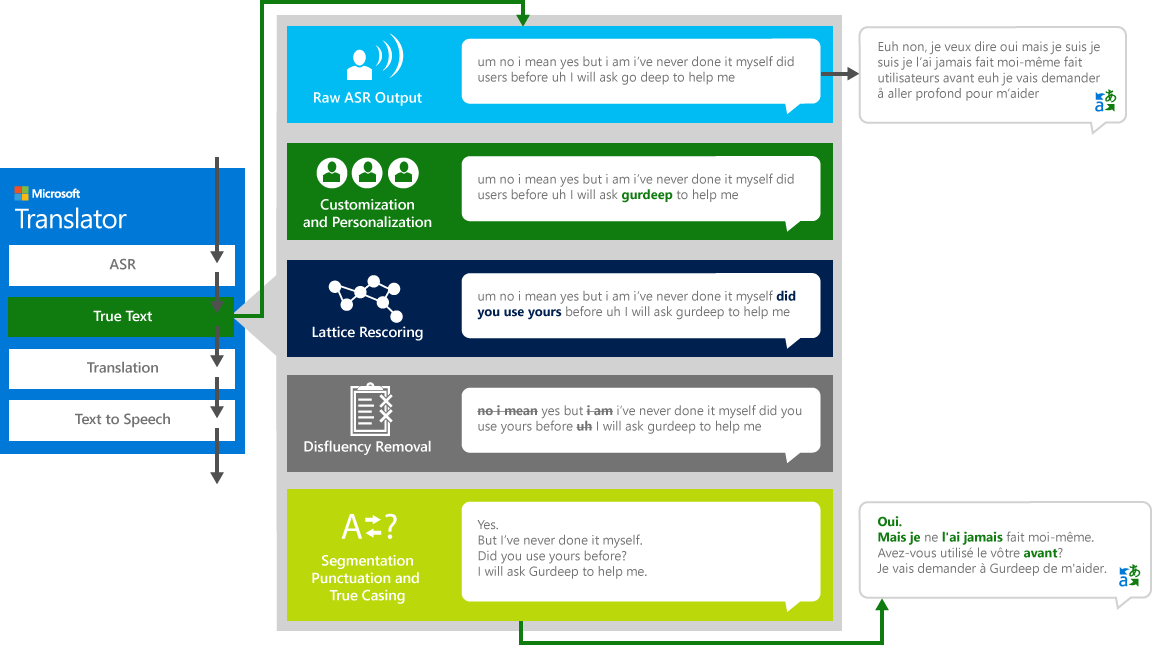
True
Som mennesker konversere med andre mennesker, taler vi ikke så perfekt, klart eller pænt, som vi ofte tror, vi gør. Med TrueText-teknologien omdannes den bogstavelige tekst til mere nøjagtigt at afspejle bruger hensigter ved at fjerne taleforstyrrelser (fyld ord), såsom "UM" s, "Ah" s "og" s "," Like "s, hakker og gentagelser. Teksten er også gjort mere læsbar og kan oversættes ved at tilføje sætning pauser, korrekt tegnsætning, og kapitalisering. For at opnå disse resultater brugte vi årtiers arbejde på sprogteknologier, vi udviklede fra Translator til at skabe TrueText. Det følgende diagram viser gennem et virkeligt eksempel, den forskellige transformation TrueText fungerer for at normalisere denne bogstavelige tekst.
Oversættelse
Teksten oversættes derefter til en af de sprog og dialekter understøttet af Translator.
Oversættelser, der bruger tale oversættelses-API'EN (som udvikler) eller i en tale oversættelses-app eller-tjeneste, drives med de nyeste neurale netværksbaserede oversættelser for alle sprog, der understøttes af taleinput (Se Her for den fuldstændige liste). Disse modeller blev også bygget ved at udvide den nuværende, for det meste skrevet tekst-uddannede oversættelses modeller, med mere udtalt tekst corpora at opbygge en bedre model for talte samtaletyper af oversættelser. Disse modeller er også tilgængelige via "tale" standardkategori af den traditionelle tekst oversættelses-API.
For alle sprog, der ikke understøttes af neurale oversættelse, er traditionel SMT oversættelse udført.
Tekst til tale
Hvis målsproget er et af de 18 understøttede tekst-til-tale- Sprog, og brugstilfældet kræver et lydudgang, konverteres teksten derefter til Taleoutput ved hjælp af talesyntese. Dette stadie er udeladt i tale til tekst-oversættelses scenarier.
Læs mere om Microsofts tekst til taletjenester.
Forskning
Se de seneste forskningsdokumenter fra Microsoft Translator-teamet.



