

TechWiese Blog
Installation und Betrieb eines Rook/Ceph Clusters auf Azure Kubernetes Service
23. Juli 2020

Christian Dennig
Dieser Blogbeitrag ist ein Repost und stammt im Original aus dem Know-how-Bereich von TechWiese, dessen Artikel in diesem Blog aufgegangen sind.
Einleitung
Kubernetes ist mittlerweile eine überaus beliebte Plattform, um Cloud-native Anwendungen "at scale" auszuführen. Eine gängige Empfehlung dabei ist, so viel "State" wie möglich aus dem Cluster zu halten, da die Verwaltung von zustandsbehafteten Diensten in Kubernetes keine triviale Aufgabe ist. Der Betrieb solcher Anwendungen kann unter Umständen recht schwierig sein, besonders wenn man mit Diensten zu tun hat, die häufig Disks mounten- bzw. unmounten müssen. Diese Operationen können unter Umständen fehlschlagen und natürlich werden die Benutzer der jeweiligen Anwendung darunter leiden. Es gibt jedoch Anwendungen und Situationen, wo die Verwendung von Persistent Volumes und dadurch das Management von zustandsbehafteten Workloads unumgänglich ist. Eine Lösung, die gerade im Bereich "Storage" hierbei immer beliebter wird, ist Rook in Kombination mit Ceph.
Auf der Homepage von Rook wird das Projekt wie folgt beschrieben:
Rook verwandelt verteilte Storage-Systeme in selbstverwaltende, selbstskalierende, selbstheilende Speicherdienste. Es automatisiert die Aufgaben eines Storage-Administrators: Bereitstellung, Bootstrapping, Konfiguration, Einrichtung, Skalierung, Upgrade, Migration, Disaster Recovery, Überwachung und Ressourcenverwaltung.
Rook ist ein Projekt der Cloud Native Computing Foundation und aktuell im Status “Incubating”.
Ceph wiederum ist eine OSS-Storage-Plattform, die die Speicherung auf einem Cluster implementiert und Schnittstellen für die Speicherung auf Objekt-, Block- und Dateiebene bereitstellt. Das Projekt existiert seit vielen Jahren und ist ein "battle-proof", verteiltes Speichersystem. Umfangreiche Systeme sind mit Ceph bereits implementiert worden.
Kurz gesagt ermöglicht Rook die Ausführung von Ceph-Speichersystemen auf Basis von Kubernetes unter Verwendung bestehender Konzepte und Strukturen. Die grundlegende Architektur dafür innerhalb eines Kubernetes-Clusters sieht wie folgt aus:
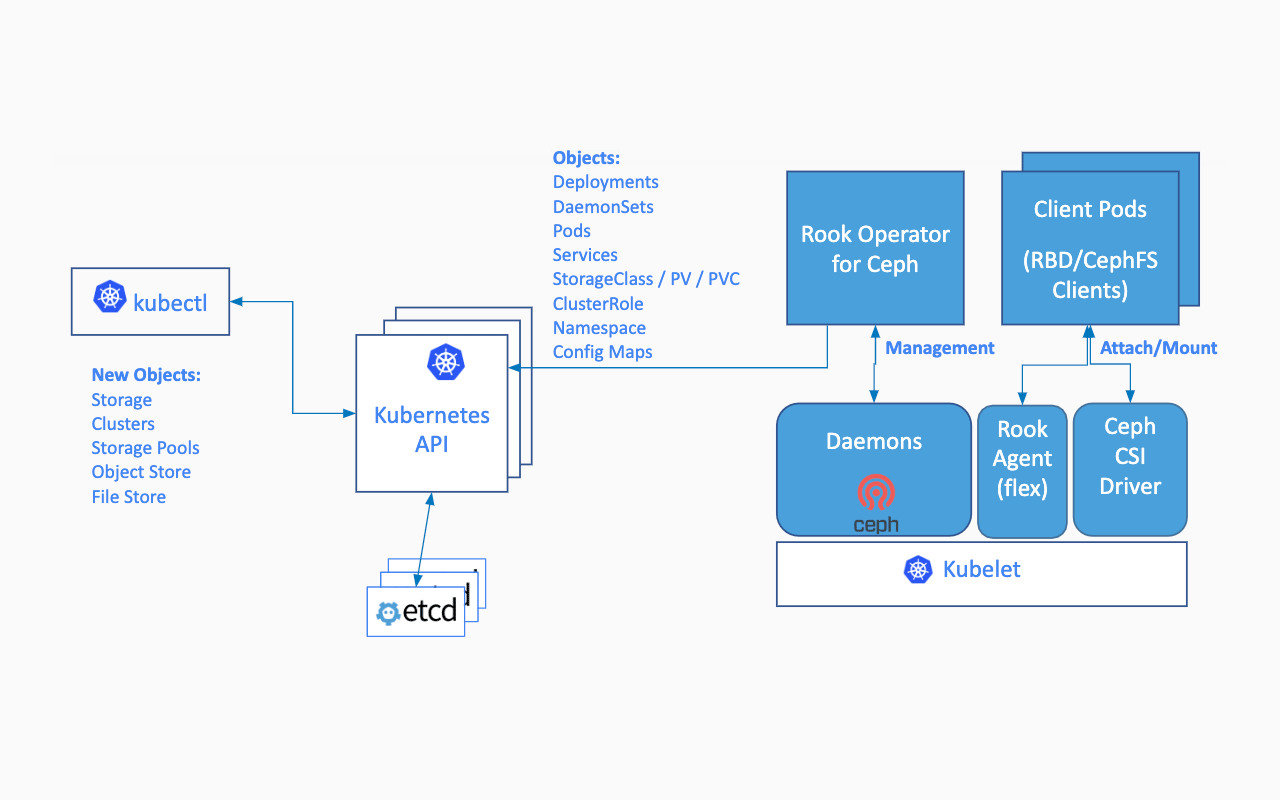
Rook in-cluster Architektur. Quelle: https://rook.io
Wir werden in diesem ARtikel nicht tief auf die Details von Rook / Ceph eingehen, da wir den Fokus auf die Installation und den Betrieb auf Azure Kubernetes Service in Verbindung mit Persistent Volume Claims legen wollen.
AKS Cluster
Beginnen wir mit der Erstellung eines Azure Kubernetes Clusters (AKS). Wir werden dabei verschiedene Node Pools für Storage (Node Pool: npstorage) und die eigentliche Applikation (Node Pool: npstandard) verwenden.
# Resource Group
$ az group create --name rooktest-rg --location westeurope
# Create the cluster
$ az aks create \
--resource-group rooktest-rg \
--name myrooktestclstr \
--node-count 3 \
--nodepool-name npstandard \
--generate-ssh-keys
Es dauert einige Minuten bis der Cluster erstellt ist.
Storage Node Pool hinzufügen
Nachdem der Cluster erfolgreich erzeugt wurde, legen wir den Node Pool für die Storage Nodes an. Wir fügen zusätzlich Taints hinzu, um zu verhindern, dass andere Workloads außer den Storage Pods dort landen können. Wir stellen damit sicher, dass diese Nodes ausschließlich für den Anwendungsfall "Storage" reserviert sind.
Falls Du wissen möchtest, wie Taints und Tolerations funktionieren, wirf bitte einen Blick in die offizielle Kubernetes Dokumentation an.
$ az aks nodepool add --cluster-name myrooktestclstr \
--name npstorage --resource-group rooktest-rg \
--node-count 3 \
--node-taints storage-node=true:NoSchedule
Sobald der zusätzlich Pool erstellt wurde, laden wir uns zunächst einmal die Kubernetes Credentials auf die lokale Arbeitsstation, um mit kubectl gegen den neu erstellten Cluster arbeiten zu können:
$ az aks get-credentials \
--resource-group rooktest-rg \
--name myrooktestclstr
Werfen wir nun einen Blick auf die vorhandenen Worker Nodes:
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
aks-npstandard-33852324-vmss000000 Ready agent 104m v1.16.10
aks-npstandard-33852324-vmss000001 Ready agent 104m v1.16.10
aks-npstandard-33852324-vmss000002 Ready agent 104m v1.16.10
aks-npstorage-33852324-vmss000000 Ready agent 97m v1.16.10
aks-npstorage-33852324-vmss000001 Ready agent 97m v1.16.10
aks-npstorage-33852324-vmss000002 Ready agent 97m v1.16.10
Aus einer "Infrastruktur-Perspektive" sind wir nun bereit, Rook zu installieren.
Installation von Rook
Zunächst einmal klonen wir das Rook Repository von GitHub:
$ git clone https://github.com/rook/rook.git
Nachdem der Download auf die lokale Maschine beendet ist, werden wir die folgenden drei Schritte durchführen, um Rook auf unserem Kubernetes Cluster zu installieren:
- Hinzufügen der Rook Custom Resource Definitions (CRDs), des Namespace, allgemeiner Ressourcen etc.
- Hinzufügen und konfigurieren des Rook Operators
- Hinzufügen des Rook Clusters
Alle nachfolgenden Schritte werden im Verzeichnis cluster/examples/kubernetes/ceph des gerade geklonten Rook Repos durchgeführt.
1. Custom Resource Definitions (CRDs), Namespace, allgemeine Ressourcen
Das File common.yaml beinhaltet den Namespace rook-ceph, ClusterRoles, Bindings, Service Accounts etc. und einige CRDs, die benötigt werden. Diese werden wie folgt installiert:
$ kubectl apply -f common.yaml
namespace/rook-ceph created
customresourcedefinition.apiextensions.k8s.io/cephclusters.ceph.rook.io created
customresourcedefinition.apiextensions.k8s.io/cephclients.ceph.rook.io created
[...]
[...]
clusterrolebinding.rbac.authorization.k8s.io/rook-csi-rbd-provisioner-sa-psp created
clusterrolebinding.rbac.authorization.k8s.io/rbd-csi-nodeplugin created
clusterrolebinding.rbac.authorization.k8s.io/rbd-csi-provisioner-role created
2. Hinzufügen des Rook Operators
Der Rook Operator ist für das Management der Rook Ressourcen zuständig und muss für die Azure Kubernetes Service Umgebung angepasst werden. Zur Verwaltung von Flex Volumes verwendet der AKS ein Verzeichnis, das sich vom "Standardverzeichnis" unterscheidet. Wir müssen also dem Operator zunächst mitteilen, welches Verzeichnis auf den Clusterknoten verwendet werden soll.
Außerdem müssen wir die Einstellungen für das Container Storage Interface (CSI) Plugin anpassen, um die entsprechenden Rook DaemonSets auf den Storage Nodes auszuführen zu können (zur Erinnerung: wir haben den Knoten Taints hinzugefügt. Standardmäßig werden die Pods der Rook DaemonSets, deshalb nicht auf unseren Storage Nodes geschedulet - wir müssen dies "tolerieren").
Das operator.yaml File besteht aus einer ConfigMap und einem Deployment. In beiden Bereichen müssen für die oben genannten Konfigurationen Anpassungen vorgenommen werden.
Für die ConfigMap:
[...]
[...]
CSI_PROVISIONER_TOLERATIONS: |
- effect: NoSchedule
key: storage-node
operator: Exists
[...]
[...]
CSI_PLUGIN_TOLERATIONS: |
- effect: NoSchedule
key: storage-node
operator: Exists
[...]
[...]
Für das Deployment:
[...]
[...]
- name: FLEXVOLUME_DIR_PATH
value: "/etc/kubernetes/volumeplugins"
[...]
[...]
- name: DISCOVER_TOLERATIONS
value: |
- effect: NoSchedule
key: storage-node
operator: Exists
[...]
[...]
Sind die Anpassungen durchgeführt, wird das operator.yaml Manifest eingespielt:
$ kubectl apply -f operator.yaml
3. Rook Cluster Ressource installieren
Die Rook Cluster Ressource einzuspielen ist genau so einfach wie die Installation des Rook Operators.
Da wir unseren Cluster mit AKS betreiben, wollen wir unseren Storage Nodes keine Disks manuell hinzufügen. Auch wollen wir kein Verzeichnis auf der OS Disk des jeweiligen Knotens verwenden, da dieses gelöscht würde, sobald der Knoten auf eine neue Kubernetes-Version aktualisiert wird.
In diesem Beispiel wollen wir Persistent Volumes / Persistent Volume Claims nutzen, die verwendet werden, um Azure Managed Disks zu provisionieren, die wiederum dynamisch an unsere Storage Nodes angehängt werden. Während der Installation unseres Kubernetes Clusters wurde bereits eine entsprechende Kubernetes Storage Classmanaged-premium für die Verwendung von Premium-SSDs von Azure erstellt.
$ kubectl get storageclass
NAME PROVISIONER AGE
azurefile kubernetes.io/azure-file 19h
azurefile-premium kubernetes.io/azure-file 19h
default (default) kubernetes.io/azure-disk 19h
managed-premium kubernetes.io/azure-disk 19h
Um diese Storage Class verwenden zu können, müssen wir das File cluster-on-pvc.yaml (welches den Rook Cluster schlussendlich erstellt) anpassen. Zudem müssen wir die entsprechenden Tolerations und die Node-Affinity Settings anpassen, damit die jeweiligen Pods auf den gewünschten Storage Nodes ausgeführt werden.
apiVersion: ceph.rook.io/v1
kind: CephCluster
metadata:
name: rook-ceph
namespace: rook-ceph
spec:
dataDirHostPath: /var/lib/rook
mon:
count: 3
allowMultiplePerNode: false
volumeClaimTemplate:
spec:
storageClassName: managed-premium
resources:
requests:
storage: 100Gi
cephVersion:
image: ceph/ceph:v15.2.4
allowUnsupported: false
skipUpgradeChecks: false
continueUpgradeAfterChecksEvenIfNotHealthy: false
mgr:
modules:
- name: pg_autoscaler
enabled: true
dashboard:
enabled: true
ssl: true
crashCollector:
disable: false
storage:
storageClassDeviceSets:
- name: set1
count: 3
portable: true
tuneDeviceClass: true
placement:
tolerations:
- key: storage-node
operator: Exists
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: agentpool
operator: In
values:
- npstorage
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- rook-ceph-osd
- key: app
operator: Invalues:
- rook-ceph-osd-prepare
topologyKey: kubernetes.io/hostname
topologySpreadConstraints:
- maxSkew: 1
topologyKey: kubernetes.io/hostname
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- rook-ceph-osd
- rook-ceph-osd-prepare
resources:
volumeClaimTemplates:
- metadata:
name: data
spec:
resources:
requests:
storage: 100Gi
storageClassName: managed-premium
volumeMode: Block
accessModes:
- ReadWriteOnce
disruptionManagement:
managePodBudgets: false
osdMaintenanceTimeout: 30
manageMachineDisruptionBudgets: false
machineDisruptionBudgetNamespace: openshift-machine-apiWas wurde nun dem File hinzugefügt, was wurde geändert? Hier ein kurzer Blick auf die Anpassungen:
- die Storage Class Namen (Property: storageClassName) wurden auf managed-premium geändert
- unterhalb von spec/storage/storageClassDeviceSets/set1 wurden die Bereiche tolerations und nodeAffinity eingefügt
Nun kann die Cluster Definition eingespielt werden:
$ kubectl apply -f cluster-on-pvc.yaml
cephcluster.ceph.rook.io/rook-ceph created
Rook beginnt nun die komplette Cluster Infrastruktur zu erstellen und durchläuft dabei verschiedene Phasen in denen Pods gestartet und auch wieder gelöscht werden. Dieser Vorgang dauert mehrere Minuten, je nachdem wie schnell die Disks provisioniert werden können.
Bevor wir mit dem Setup jedoch fortfahren können, müssen die sogenannten "Object Storage Daemons" (OSDs) vollständig initialisiert und vorhanden sein - in unserem Fall müssen schlussendlich drei OSDs ausgeführt werden.
$ kubectl get pods -n rook-ceph
NAME READY STATUS RESTARTS AGE
[...]
[...]
rook-ceph-osd-0-dfb6d754b-fbhsl 1/1 Running 0 28m
rook-ceph-osd-1-7b897886bb-54pbb 1/1 Running 0 27m
rook-ceph-osd-2-f94ffbfd8-qwbmh 1/1 Running 0 27m
[...]
[...]
Zusätzlich müssen die Persistent Volumes / Persistent Volume Claims erstellt und gebunden sein:
$ kubectl get pvc -n rook-ceph -o wide
NAME STATUS VOLUME CAPACITY ACCESMODE STORAGECLASS AGE VOLUMEMODE
rook-ceph-mon-a Bound pvc-3aad7793-629c-49f2-a72f-b9d12a1324dd 100Gi RW managed-premium 66m Filesystem
rook-ceph-mon-b Bound pvc-0f424dea-003b-4231-ad84-7956e10858b5 100Gi RW managed-premium 66m Filesystem
rook-ceph-mon-c Bound pvc-06457c44-0e04-485e-8c91-fcbdfe238523 100Gi RW managed-premium 66m Filesystem
set1-data-0-cn7ss Bound pvc-ab3abd61-b2f9-4587-a5c5-3eaec82a21a1 100Gi RW managed-premium 64m Block
set1-data-1-lnkkp Bound pvc-e54dc99f-b18e-4725-afee-6808044462cb 100Gi RW managed-premium 64m Block
set1-data-2-8lr2v Bound pvc-fa69b73e-9657-4944-a1f4-33c7acd1df50 100Gi RW managed-premium 64m Block
Soweit ist nun alles korrekt eingerichtet und wir können damit beginnen, Ceph Block Pools zu erstellen und diese als Storage Class im Kubernetes Cluster bekannt zu machen.
Storage konfigurieren
Bevor man über Rook nun für die eigene Workload Persistent Volumes bereitstellen kann, sollte entweder ein "File System" oder ein "Storage Pool" konfiguriert werden. Ein solcher Pool stellt die Quelle für zu erstellende Volumes dar. In unserem Beispiel wird wie bereits erwähnt ein Ceph Block Pool verwendet:
apiVersion: ceph.rook.io/v1
kind: CephBlockPool
metadata:
name: replicapool
namespace: rook-ceph
spec:
failureDomain: host
replicated:
size: 3Als nächstes benötigen wir auch eine Kubernetes Storage Class, die den Rook-Cluster/den gerade angelegten Storage Pool verwendet. In unserem Beispiel verwenden wir hierbei nicht Flex Volume (was ebenfalls möglich wäre), sondern eine Storage Class in Verbindung mit dem Container Storage Interface (CSI).
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: rook-ceph-block
provisioner: rook-ceph.rbd.csi.ceph.com
parameters:
clusterID: rook-ceph
pool: replicapool
imageFormat: "2"
imageFeatures: layering
csi.storage.k8s.io/provisioner-secret-name: rook-csi-rbd-provisioner
csi.storage.k8s.io/provisioner-secret-namespace: rook-ceph
csi.storage.k8s.io/node-stage-secret-name: rook-csi-rbd-node
csi.storage.k8s.io/node-stage-secret-namespace: rook-ceph
csi.storage.k8s.io/fstype: ext4
reclaimPolicy: DeleteSobald beide Manifeste in den Cluster eingespielt wurden, sind alle Voraussetzungen erfüllt, um mit eigenen Deployments/Pods den Rook Storage Pool zu benutzen.
Test der Umgebung
Sowohl Rook, Ceph also auch Kubernetes (mit dem Erstellen der StorageClass Definition) sind nun vollständig konfiguriert, um unseren Storage Cluster in eigenen Containern/Pods zu verwenden. Starten wir mit einem kurzen Test, der folgendes beinhaltet:
- Anlage eines Persistent Volume Claims, der auf die Rook/Ceph Storage Class verweist
- Verwenden des Claims in einem Deployment/Pod
Beginnen wir mit der Anlage des PVCs:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: ceph-pv-claim
spec:
storageClassName: rook-ceph-block
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi...und im Nachgang mit der Erstellung eines einfachen NGINX Pods, der das zuvor kreierte PVC unter dem Pfad /usr/share/nginx/html einhängt.
apiVersion: v1
kind: Pod
metadata:
name: ceph-pv-pod
spec:
volumes:
- name: ceph-pv-claim
persistentVolumeClaim:
claimName: ceph-pv-claim
containers:
- name: task-pv-container
image: nginx
ports:
- containerPort: 80
name: "http-server"
volumeMounts:
- mountPath: "/usr/share/nginx/html"
name: ceph-pv-claimSchaut man sich das Resultat der beiden angewendeten Manifeste an, so sieht man, dass alles wie gewünscht erstellt und gemountet wurde:
$ kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
ceph-pv-claim Bound pvc-8f59b2b9-ffd8-4d1d-82eb-d4ac15ed5b56 10Gi RWO rook-ceph-block 6s
$ kubectl describe ceph-pv-pod
Name: ceph-pv-pod
Namespace: default
Priority: 0
Node: aks-npstandard-33852324-vmss000002/10.240.0.6
Start Time: Fri, 17 Jul 2020 13:46:57 +0200
Labels: <none>
Annotations: Status: Running
IP: 10.244.1.10
IPs:
IP: 10.244.1.10
Containers:
task-pv-container:
[...]
Environment: <none>
Mounts:
/usr/share/nginx/html from ceph-pv-claim (rw)
/var/run/secrets/kubernetes.io/serviceaccount from default-token-s74ww (ro)
[...]
Volumes:
ceph-pv-claim:
Type: PersistentVolumeClaim (a reference to a PersistentVolumeClaim in the same namespace)
ClaimName: ceph-pv-claim
ReadOnly: false
[...]
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 26s default-scheduler Successfully assigned default/ceph-pv-pod to aks-npstandard-33852324vmss000002
Normal SuccessfulAttachVolume 26s attachdetach-controller AttachVolume.Attach succeeded for volume"pvc-8f59b2b9-ffd8-4d1d-82eb-d4ac15ed5b56"
Normal Pulling 16s kubelet, aks-npstandard-33852324-vmss000002 Pulling image "nginx"
Normal Pulled 12s kubelet, aks-npstandard-33852324-vmss000002 Successfully pulled image "nginx"
Normal Created 7s kubelet, aks-npstandard-33852324-vmss000002 Created container task-pv-container
Normal Started 7s kubelet, aks-npstandard-33852324-vmss000002 Started container task-pv-container
Rook Toolbox
Um Rook zu überwachen, gibt es verschiedene Wege. Man kann das mitgelieferte Dashboard oder auch die vorhandene Prometheus Integration verwenden. Um einen schnellen Blick auf den Cluster zu werfen, hilft allerdings auch die Rook Toolbox. Auf der Homepage findet sich ein entsprechend vorkonfiguriertes Manifest, das man direkt verwenden kann, um die "Toolbox" zu installieren. Hat man dies getan und sich erfolgreich in den Pod verbunden, ist man in der Lage verschiedenste Operationen gegen den Rook/Ceph Cluster auszuführen, hier einige Beispiele:
Status abfragen
$ ceph status
cluster:
id: 922faf21-26bb-4461-9321-8d2d72395f90
health: HEALTH_OK
services:
mon: 3 daemons, quorum a,b,c (age 5h)
mgr: a(active, since 5h)
osd: 3 osds: 3 up (since 5h), 3 in (since 5h)
data:
pools: 2 pools, 33 pgs
objects: 23 objects, 19 MiB
usage: 3.0 GiB used, 297 GiB / 300 GiB avail
pgs: 33 active+clean
OSD Status abfragen
$ ceph osd status
ID HOST USED AVAIL WR OPS WR DATA RD OPS RD DATA STATE
0 aks-npstorage-33852324-vmss000002 1032M 98.9G 0 0 0 0 exists,up
1 aks-npstorage-33852324-vmss000000 1032M 98.9G 0 0 0 0 exists,up
2 aks-npstorage-33852324-vmss000000 1032M 98.9G 0 0 0 0 exists,up
Belegung des Cluster abfragen
$ ceph df
--- RAW STORAGE ---
CLASS SIZE AVAIL USED RAW USED %RAW USED
hdd 300 GiB 297 GiB 26 MiB 3.0 GiB 1.01
TOTAL 300 GiB 297 GiB 26 MiB 3.0 GiB 1.01
--- POOLS ---
POOL ID STORED OBJECTS USED %USED MAX AVAIL
device_health_metrics 1 0 B 0 0 B 0 94 GiB
replicapool 2 4.3 MiB 23 16 MiB 0 94 GiB
Zusammenfassung
Was genau haben wir nun mit dieser Lösung erreicht? Wir haben einen Ceph-Storage Cluster auf einem mit AKS gemanageten Kubernetes Cluster erstellt, der Persistent Volume Claims zur Speicherverwaltung verwendet. Dies ist besonders für Applikationen und Plattformen interessant, die stabile Lösungen benötigen und spezielle Anforderungen im Management von Storage und Disks haben. Zudem haben wir die "attach" und "detach" Operationen von Azure Managed Disks reduziert, da wir uns mit der geschaffenen Lösung aus einem bereits vorhandenen Storage Pool bedienen können, der widerum per Azure Managed Disks zur Verfügung gestellt wurde. Die Verwendung von Volume-Mounts in eigenen Kubernetes Workloads mit Ceph ist jetzt extrem perfomant und "rock-solid"!