
Einführung von AI-Übersetzungen auf Edge-Geräte mit Microsoft Translator
Im November 2016 brachte Microsoft den Nutzen der KI-basierten maschinellen Übersetzung, auch bekannt als Neural Machine Translation (NMT), sowohl für Entwickler als auch für Endanwender. Letzte Woche, Microsoft hat die NMT-Fähigkeit an den Rand der Cloud gebracht. durch die Nutzung der NPU, einem AI-eigenen Prozessor, der in den Partner 10Huawei's neuestes Flaggschiff-Handy. Der neue Chip macht KI-gestützte Übersetzungen auch ohne Internetzugang auf dem Gerät verfügbar und ermöglicht es dem System, Übersetzungen zu erstellen, deren Qualität mit dem des Online-Systems vergleichbar ist.
Um diesen Durchbruch zu erzielen, arbeiteten Forscher und Ingenieure von Microsoft und Huawei zusammen, um die neuronale Übersetzung an diese neue Computerumgebung anzupassen.
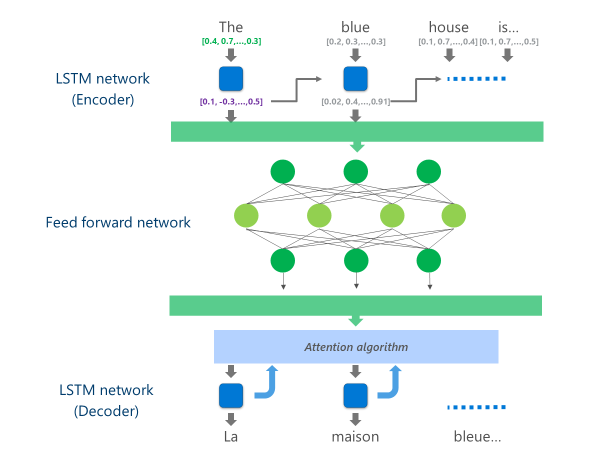
Die fortschrittlichsten NMT-Systeme, die sich derzeit in Produktion befinden (d.h. im Maßstab in der Cloud von Unternehmen und Anwendungen verwendet werden), verwenden eine neuronale Netzwerkarchitektur, die mehrere Schichten von LSTM-Netze, einen Aufmerksamkeitsalgorithmus und eine Translationsschicht (Decoder).
Die folgende Animation erklärt in vereinfachter Form, wie dieses mehrschichtige neuronale Netzwerk funktioniert. Weitere Informationen finden Sie in der "was ist eine maschinelle Übersetzungsseite?"auf der Microsoft Translator-Website.

In dieser Cloud NMT-Implementierung verbrauchen diese mittleren LSTM-Schichten einen großen Teil der Rechenleistung. Um die vollständige NMT auf einem mobilen Gerät ausführen zu können, war es notwendig, einen Mechanismus zu finden, der diese Rechenkosten senken und gleichzeitig die Übersetzungsqualität so weit wie möglich erhalten konnte.
Hier kommt Huawei's Neural Processing Unit (NPU) ins Spiel. Microsoft-Forscher und -Ingenieure nutzten die NPU, die speziell für Low-Latency-KI-Berechnungen entwickelt wurde, um Operationen zu entlasten, die auf der Haupt-CPU unannehmbar langsam verarbeitet worden wären.
Implementierung
Die jetzt in der Microsoft Translator App für den Huawei Mate 10 verfügbare Implementierung optimiert die Übersetzung, indem sie die rechenintensivsten Aufgaben an die NPU auslagert.
Konkret ersetzt diese Implementierung diese mittleren LSTM-Netzwerkebenen durch ein tiefes feed-forward neuronales netzwerk. Tiefe Feed-Forward-Neuronale Netze sind leistungsfähig, erfordern aber aufgrund der hohen Konnektivität zwischen den Neuronen sehr große Rechenaufwände.
Neuronale Netze basieren in erster Linie auf Matrix-Multiplikationen, eine Operation, die aus mathematischer Sicht nicht komplex, aber sehr teuer ist, wenn sie in der für ein so tiefes neuronales Netzwerk erforderlichen Größenordnung durchgeführt wird. Der Huawei NPU zeichnet sich dadurch aus, dass er diese Matrixmultiplikationen massiv parallel durchführt. Es ist auch aus Sicht des Stromverbrauchs recht effizient, eine wichtige Eigenschaft bei batteriebetriebenen Geräten.
Auf jeder Schicht dieses Feed-Forward-Netzwerks berechnet die NPU sowohl die Rohneuronenausgabe als auch die nachfolgende Neuronenausgabe. ReLu Aktivierungsfunktion effizient und mit sehr geringer Latenzzeit. Durch die Nutzung des großen Hochgeschwindigkeitsspeichers auf der NPU führt sie diese Berechnungen parallel durch, ohne die Kosten für die Datenübertragung (d.h. die Verlangsamung der Leistung) zwischen CPU und NPU bezahlen zu müssen.
Sobald die letzte Schicht dieses tiefen Feed-Forward-Netzwerks berechnet ist, verfügt das System über eine umfangreiche Darstellung des Quellsprachensatzes. Diese Darstellung wird dann durch einen LSTM "Decoder" von links nach rechts geleitet, um jedes Wort der Zielsprache zu erzeugen, mit dem gleichen Aufmerksamkeitsalgorithmus, der in der Online-Version des NMT verwendet wird.
Als Anthony Aueerklärt ein Principal Software Development Engineer im Microsoft Translator-Team: “ein System, das auf leistungsstarken Cloud-Servern in einem Rechenzentrum läuft, unverändert auf einem Mobiltelefon zu betreiben, ist keine praktikable Option. Mobile Geräte haben Einschränkungen in Bezug auf Rechenleistung, Speicher und Stromverbrauch, die Cloud-Lösungen nicht haben. Der Zugang zur NPU, zusammen mit einigen anderen architektonischen Optimierungen, ermöglichte es uns, viele dieser Einschränkungen zu umgehen und ein System zu entwerfen, das schnell und effizient auf dem Gerät ausgeführt werden kann, ohne die Übersetzungsqualität beeinträchtigen zu müssen..”

Die Implementierung dieser Übersetzungsmodelle auf dem innovativen NPU-Chipsatz ermöglichte es Microsoft und Huawei, neuronale Übersetzungen auf dem Gerät in einer Qualität anzubieten, die mit der von Cloud-basierten Systemen vergleichbar ist, selbst wenn Sie nicht im Netz sind.



