

Running the allocation step of Wave processing in parallel
This blog post applies to Microsoft Dynamics AX 2012 R3 CU11 and KB 3153040.
Wave processing is used to generate work for the warehouse. The processing can be time consuming and majority of the processing time is spent in the allocation step and in the work creation step.
It is now possible to run the wave allocation step in parallel, which can improve the performance of the wave processing, and allow for a larger throughput of waves in the same warehouse.
Previously it was only possible to allocate one wave at a warehouse at a time. This constraint was enforced by using a SQL application lock that basically locked on the warehouse ID. This constraint has now been removed. A new constraint has been introduced so the locking is done on the item and dimensions that are above location in the reservation hierarchy. Dimensions above the location always include product dimensions, so if an item is configured using Color, variants for Red, Blue, and Yellow could be processed in parallel.
This means that if the same item with the same dimensions above the location is being allocated by one wave, other waves will have to wait to acquire a lock on the same item and dimensions. If the lock cannot be acquired in a timely manner, an error will be thrown and the wave processing will fail.
In order to utilize parallel processing, the wave needs to run in batch.
Performance improvements – what can be expected
It is hard to predict how much the parallel processing can improve the performance.
The performance benefits fall in two categories:
- Improved throughput: The throughput of waves should be improved even if parallel processing is not configured, especially for scenarios where there is no overlap of items within the waves.
- Improvement of the allocation for a single wave: Testing on customer data on a 4 core environment using 8 tasks, resulted in almost a 50% improvement of the overall processing for larger waves with more than 700 different items and variants. The parallel processing is done per items and dimensions above the location, so the improvements depends on how many different items a wave contains, the infrastructure available, and the duration of the allocation vs the duration of the work creation.
Configuration
Warehouse management parameters
The following values on the Warehouse management parameters form are relevant. This form is found under Warehouse management > Setup > Warehouse management parameters.:
| Field | Description |
| Wave processing batch group | This determines the batch group that the initial processing of the waves should use. The subsequence processing of allocation can be done using different batch groups. |
| Process waves in batch | This determines if the waves are processed in batch. If this is not enabled, parallel processing will not be used. |
| Create pending allocation log | This determines if logging should be done during the parallel processing of pending allocations. This should only be enabled if you need insight into the wave allocation, for example, to troubleshoot issues, since it adds an extra overhead. |
| Wait for lock (ms) | This setting determines how long the wave processing should wait to acquire a lock on the item and dimensions above location (this is the logical unit that is locked during wave processing). We recommend that you allow waits of at least a few seconds, since it allows for allocation of one logical unit to finish. The setting is in milliseconds. |
Wave process methods
The actual configuration of the parallel processing is done on the Wave process methods form found under Warehouse Management > Setup > Waves > Wave process methods.
A new button called Task configuration is enabled for the allocateWave method. This buttons opens the Wave post method task configuration form.
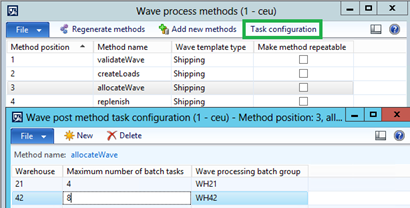
In this form you can configure how many batch tasks should be used for the allocation in a specific warehouse. If the number is set to 8, a maximum of 8 batch tasks will be used to process the allocation.
Note: The optimal number of batch tasks depends on the infrastructure available and what other batch jobs are being processed on the server. Tests done on a 4 core environment that was dedicated to wave processing showed that 8 tasks lead to good results.
Specific batch groups can be used for different warehouses in order to allow the allocation processing to scale out per warehouse.
If a configuration record does not exist for a warehouse, parallel processing will not be used.
Troubleshooting
Since the batch framework is used, errors that occur during wave processing will be captured as part of the batch jobs Infologs. The batch jobs related to a wave can be viewed using the Batch jobs button:
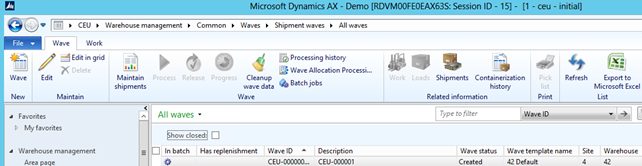
This is what a typical set of batch jobs would look like for a wave:
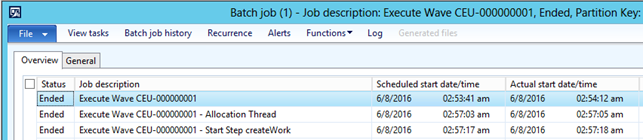
The first batch job is the one that was initially created when the wave processing began. If parallel execution is used, this job prepares data for the next job.
The second job is the one for the allocation. This job can have multiple tasks dependent on the number of batch tasks configured. The third job is for the rest of the wave processing and has information about the first step after the allocation. This is typically the createWork step or replenishment if that is enabled.
The wave processing is self-correcting so any error that’s detected during the processing should be handled gracefully and reported using the Infolog.
A typical error related to parallel processing could be that two waves try to allocate the same item at the same time and one does not complete so that the other wave is unable to acquire a lock within the specified time. If this situation occurs the batch jobs log will contain information stating that the lock for the item could not be acquired. If this occurs, the wave that failed needs to be processed again.
Since the processing is happening in parallel, data needs to be maintained in different tables to track the state of the processing. This means that the logs for the batch jobs might contain errors such as duplicate key errors. The screenshot below is an example of such errors where 8 tasks were created and all failed the allocation:
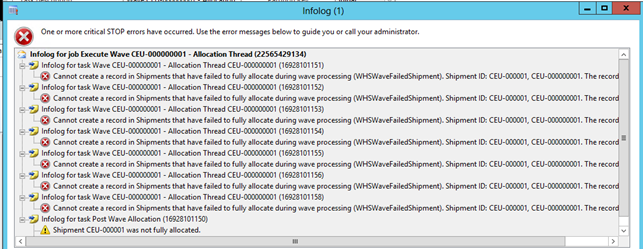
The errors from the batch tasks are also part of the batch jobs log. The most important information is typically at the bottom. In this example the log is telling us that the shipment was not fully allocated.
In rare cases, for example if the SQL connection is ended, it is possible for the wave processing to end up in an inconsistent state where the batch job appears to be running but the processing is stopped. The wave can’t handle errors like this, so an attempt to clean up failed waves is done when the next wave runs. Alternatively, you can use the Clean up wave data button to clean up the current wave if it is in an inconsistent state.
The pending allocation log
If the Pending allocation logging option is enabled data can be viewed in the Wave pending allocation log form by clicking the button. A log record is created every time allocation for an item and its dimensions begins and ends.
Logging should only be enabled if you need it, for example, during initial testing or for troubleshooting.


