

This content has been archived, and while it was correct at time of publication, it may no longer be accurate or reflect the current situation at Microsoft.
Microsoft Digital is enhancing user experiences for Microsoft employees—such as finding information and communicating and collaborating with coworkers. Using Azure Data Factory and Azure Data lake, we built a platform to capture instrumentation—which includes data from products and services like Skype for Business and Office 365. We analyze this data, along with user feedback, using data science, machine learning, and algorithms—key phrase extraction, deep semantic similarity, and sentiment analysis—for insights to help people be productive.
Whether people use Microsoft products and services to look for information, attend meetings, or collaborate, a great experience promotes user satisfaction, improves productivity, increases adoption, and cuts support costs.
To enhance user experiences for Microsoft employees and vendors, Microsoft Digital employs instrumentation, Azure AI, data science, and machine learning algorithms. The resulting intelligence gives us insight into how people use products and services to achieve their goals, how they perceive an experience, and any issues they have.
Our scope isn’t a specific product or service, but rather five high-level—often overlapping—experiences across Microsoft products and services:
- Finding
- Meeting
- Supporting
- Communicating
- Collaborating
Let’s take a closer look at the technical details about how we set up the data platform and ingest data. After we consume and analyze data, why and how do we apply data science, machine learning, and algorithms like key phrase extraction, sentiment analysis, and deep semantic similarity? How do these approaches give us insight to help enhance the five overarching experiences?
Our overall approach
First, we look at products, services, devices, and infrastructure across Microsoft. Then we map them to one or more of the five experiences and look for areas of potential improvement. To do this, we use product and service telemetry like crash data and client device information. We also gauge sentiment with user feedback and satisfaction metrics from employee surveys and Microsoft Helpdesk support data.
The data platform we built offers a single view of the overall picture—for example, Microsoft Windows, internal business apps, devices, and network data. Although product teams collect metrics, their metrics only give us a view of the product or service that they create rather than across products and services at Microsoft. So we collaborate with product teams to learn from each other and offer comprehensive insight.
Technologies for creating this solution
We use Azure AI and other Microsoft technologies, and then we apply machine learning and algorithms to the data:
- Azure Data Factory. We use Azure Data Factory pipelines to ingest, prepare, process, and transform terabytes of structured and unstructured data and to move data into Azure Data Lake.
- Azure Data Lake . We use Azure Data Lake to store the data. Data Lake makes it easy for developers, data scientists, and analysts to store data and to process and analyze it across platforms and languages.
- SQL Server Analysis Services. We use SQL Server Analysis Services to create multidimensional cubes, so that business users who create their own reports can slice and dice data in various ways.
- Machine learning . We use machine learning to get insights from verbatim analytics. To answer business-stakeholder questions, data scientists take raw data from Data Lake and do multiple levels of analysis. For verbatim analytics, we use key phrase extraction, deep semantic similarity, and sentiment analysis.
- Microsoft Power BI . Stakeholders use Power BI to view the data in self-service reports.
Architecture of the data platform
Figure 1 shows the architecture, data sources, technologies, and steps in this solution.

Collecting data and setting up the data platform
Behind the scenes, for scenarios like improving the finding or meeting experience, our general process is:
- First, we look at what the business wants to achieve. It’s important to understand the business goals and reporting needs—and how they’ll bring overall business value—before we design the data warehouse.
- Using Data Factory pipelines, we ingest terabytes of product and service data, along with survey and support data. We preprocess and cleanse it, and do initial data quality steps. With U-SQL, a big data query language for Data Lake Analytics, we filter out what we don’t need. Our scope is enterprise data, so we filter out consumer data, and ingest only what’s applicable to Microsoft employees and vendors.
- We use Data Factory pipelines to move the data into Data Lake, where we store it.
- We build the data warehouse, which contains dimensions—like devices and apps—and facts. We build the fact list so that we can correlate the pieces—for example, we might correlate apps with devices and users. For some data streams—like device-related or Windows instrumentation—we might not have user information. Without this, we can’t correlate a device with a user. Here are examples of how we correlate:
We do this in full compliance with all company security policies, and all personally identifiable information is hashed and anonymized.
- We have device IDs and other device-related data, but any device with System Center Configuration Manager installed has both device and user info. We merge the data, making sure not to duplicate it. If there’s a match between device IDs from Windows and Configuration Manager, we build instrumentation that has both user and device info.
- For apps, we use the device ID to correlate an app with a device. Then we can connect the device with the user, apps, drivers, and app crashes.
- Incidents have a user alias, so we can get details based on user and device alias. For example, “This user or device has this number of incidents or requests associated with it.”
- After the data is in the data warehouse, we build online analytical processing (OLAP) cubes. OLAP cubes give others self-service reporting capabilities, where they can slice and dice for more details. In the cubes, we define metrics like device count, percentage of users, and percentage of app crashes.
- On top of this data, we’ve started building trend analytics on data subsets. For example, some executives want to know when there is a specific Windows release and see adoption rates across the company over time. Trend analytics help us connect the pieces, giving us insights and helping us see crashes across apps. We correlate this data with the number of overall deployments and whether there were any weekly product or service updates.
- It’s easy for a product team, executive, or business analyst to build dashboards and visualize the data in Power BI.
The what, why, and how of data science
After we set up the data platform, we apply data science and algorithms. At its core, data science is about using automated methods to analyze massive amounts of data and to extract knowledge or value. For this solution, because some of our data involves verbatim feedback from user satisfaction surveys, we use three algorithms to analyze the text—key phrase extraction, sentiment analysis, and deep semantic similarity. These algorithms help us:
- Answer questions from business stakeholders.
- Measure sentiment, which helps us assess the level of user satisfaction with an experience.
- See how an experience could be enhanced.
Business opportunity of handling unstructured data
When it comes to data at large, data can either be:
- Structured. This data is highly organized—like the information in a database table.
- Unstructured. This data lacks clearly defined categories, row, columns—like the content in a document.
In the case of verbatim feedback from surveys, the data is unstructured. Data science, machine learning, and algorithms help us make sense of this unstructured data and derive meaning from it. For example, processing and analyzing verbatim feedback gives us an in-depth understanding of:
- How a person feels about a subject.
- What topics are the most discussed.
- Which experiences are affected.
It also gives a complementary facet (and sometimes conflicting input) to other ways of measuring user satisfaction. It’s a more holistic picture for understanding feedback, gathering actionable insights, and creating a targeted plan.
Four-step approach to a data science project
Regardless of which data science solution we work on, we use a general, four-step approach and technologies like the Text Analytics API from Microsoft Cognitive Services , Power BI for visualization, and open-source APIs and visualization tools.
Figure 2 shows the high-level process that we follow.

Our goal is to give relevant and timely information to stakeholders to influence the changes that most users say that they want. The following steps help us reach this goal:
- We start with a structured approach and work with business stakeholders from the get-go, so that we understand their objectives. This way, we target what questions to ask the data, and use our findings as a benchmark.
- After we know what questions to ask, business users and our data scientists collaborate to identify which metrics and data sources can help answer those questions. All the data is consolidated into a single data platform.
- After the data is ingested, we prepare and analyze it, so that we can extract maximum value from it.
- Much of the value of data comes from uncovering and communicating answers and new perspectives to stakeholders. To provide a narrative and better context behind the data, we visualize the data in Power BI.
The machine learning engine
To uncover answers and new perspectives on verbatim survey responses, we use various data processing activities and machine learning algorithms, which come together in the machine learning engine. Figure 3 shows the flow, which starts with input from data that’s ingested into the data platform, and ends with output in the form of insights and visualization.
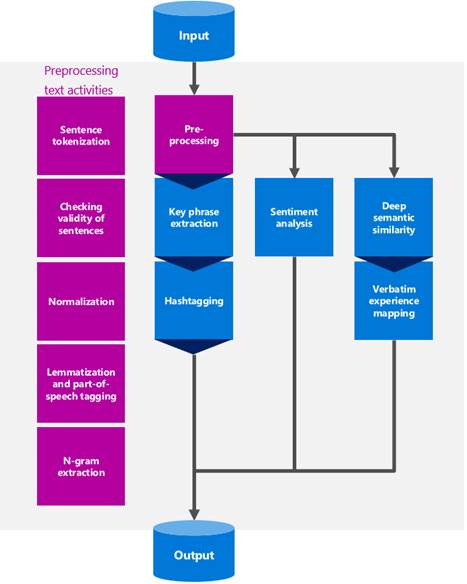
The machine learning process that we use to analyze verbatim feedback typically follows these steps:
- We start with text preprocessing. This makes it easier to extract meaningful information for a given topic and helps us do more precise sentiment analysis. As part of preprocessing, we divide the text into sentences, while also simplifying and standardizing—or normalizing—different elements in the text.
- After preprocessing, we extract key phrases, analyze sentiment, and look for deep semantic similarity. These activities can be done in parallel. Data scientists provide sentiment analysis and semantic analysis at the sentence level, and topic modeling at the entire verbatim survey level.
- As the verbatim feedback is analyzed, it’s mapped to one of the five experiences. The business stakeholders who define the experiences also identify the associated tools. For example, for collaborating, you could have OneNote and Skype for Business (although Skype for Business also aligns with the meeting experience). This information guides the machine learning in understanding whether the feedback is tied to a specific experience.
Importance of data quality and text preprocessing activities
When we build any automated procedure for text analysis, we need to ensure that the text data is good quality. This is because the quality of input data directly affects the machine learning results. Because most data quality checks are done during data ingestion, they’re outside the scope of data science. But verbatim data—ingested for analytics—can have a subset of values that aren’t valid, like question marks, “no comment,” “none,” “na,” and others. We need to recognize this kind of data and disqualify it from analysis.
After the data quality check, the verbatim data is prepared for machine learning algorithms. This is the preprocessing stage and is done in the machine learning engine. Text preprocessing involves:
- Tokenize and validate sentences.
- Normalize acronyms and abbreviations.
- Lemmatize words, tag parts of speech, and extract n-grams.
Tokenize and validate sentences
WHAT: Sentence tokenization ensures that each sentence from verbatim data goes through sentiment analysis. It separates sentences and attaches a unique sentence ID to each. Tokenized sentences are evaluated for quality to make sure that they have valuable information for further analysis.
WHY: Sentiment analysis can’t separate sentences, so if there are two sentences in a verbatim response where one is positive and the other is negative, it can’t provide a single sentiment score and polarity—whether an opinion is positive, negative, or neutral . If the first sentence is very positive and the second sentence is equally negative, analyzing both sentences together results in a neutral polarity and sentiment score, which is incorrect. If sentences are analyzed separately, the polarity score is more accurate.
HOW: There are many open-source, rule-based algorithms that tokenize English grammar. The rule-based algorithms can’t guarantee 100 percent accuracy, but they do a good job of recognizing end-of-sentence punctuation and separating sentences.
Normalize acronyms and abbreviations
WHAT: Normalization maps acronyms and abbreviations to a corresponding word list. For example, many users might refer to Skype for Business as SFB or S4B. To ensure that abbreviations are recognized by text-analysis algorithms, each tokenized sentence is normalized.
WHY: Normalization can improve the accuracy of many text-analysis algorithms. For example, what if a group of verbatim responses has 10 records for Skype for Business, 10 records for SFB, and 15 records for Surface? If terms aren’t normalized, the text-mining algorithms might consider Surface as the most frequently mentioned product in the verbatim responses. Normalization would recognize 20 records for Skype for Business.
HOW: Currently, text is normalized by using a glossary of words and abbreviations. Acronyms and abbreviations are manually identified to ensure that normalization is as accurate as possible.
Lemmatize words, tag parts of speech, and extract n-grams
WHAT: The last step of preprocessing is preparing input for key phrase extraction and hashtagging. Lemmatization returns the base or dictionary form—the lemma—of a word. It changes plural words to singular, changes past tense verbs to present tense, and so on. For example, the lemma of “kids” is “kid,” “children” is “child,” and “held” is “hold.” Part-of-speech tagging identifies nouns, verbs, adjectives, and adverbs, which helps extract information from sentences.
In very simple terms, an n-gram is a collection of letters, words, and syllables. Extracted n-grams are used as input for hashtagging.
WHY: Lemmatization ensures that words are converted to their base, or dictionary, forms. Like normalization, it can improve the accuracy of text-mining algorithms that use word count. Parts of speech and n-grams are used as input to the machine learning engine.
HOW: There are many open-source libraries that lemmatize, tag parts of speech, and extract n-grams.
The machine learning algorithms we use, why, and how
Given all the available algorithms, why did we choose to use key phrase extraction, sentiment analysis, and deep semantic similarity for this solution? Based on the type of data that we get—which includes unstructured data from feedback in survey responses—each algorithm helps us make sense of the text in different ways:
- Algorithm 1: Key phrase extraction
- Algorithm 2: Sentiment analysis
- Algorithm 3: Deep semantic similarity
Algorithm 1: Key phrase extraction
WHAT: Key phrase extraction involves extracting structured information from unstructured text. The structured information consists of important topical words and phrases from verbatim survey responses. Key phrases concisely describe survey verbatim content, and are useful for categorizing, clustering, indexing, searching, and summarizing. Key phrases are then scored/ranked.
As part of key phrase extraction, we add labels or metadata tags—hashtags—usually on social network and blog services, which makes it easier for people to find specific themes or content. Hashtagging is a process of creating a meaningful label or combination of labels to best represent a verbatim survey response.
WHY: The key phrases, hashtags, and associated score/rank are used to interpret the survey language. For example, they help us find positive and negative phrases, and trending or popular topics.
HOW: Key phrase extraction has two steps. First, a set of words and phrases that convey the content of a document is identified. Second, these candidates are scored/ranked and the best ones are selected as a document’s key phrases. We use key phrase extraction application programming interfaces (APIs)—both from Microsoft and open source.
Hashtagging is also a two-step process. First, we normalize the input survey responses and remove non-essential words. Second, the labels are scored, based on how often they appear in other survey responses.
Algorithm 2: Sentiment analysis
WHAT: Sentiment analysis is an automated method of determining if text—like verbatim feedback from surveys—is positive, neutral, or negative, and to what degree. Sentiment analysis and text analytics reveal people’s opinions about Microsoft products and services.
WHY: Sentiment analysis helps us detect what users like and dislike about products and services. It’s not enough to know the main topics that people are concerned about. We need to know how strongly they feel—whether positively or negatively. Sentiment analysis uncovers these feelings and helps us group survey responses into corresponding polarities—positive, negative, or neutral—for deeper text analysis.
HOW: Sentiment analysis is usually done with classification modeling. “Trained” data with positive, neutral, and negative labels is fed into different classification algorithms. After model training and selection, we run the final model on new verbatim data. The trained model determines the polarity and sentiment score of each piece of writing. We use the Text Analytics API in Cognitive Services for sentiment polarity and scoring.
Algorithm 3: Deep semantic similarity
WHAT: Semantic similarity is a metric that’s defined for a set of documents or terms, where the similarity score is based on similarity of meaning. It identifies whether verbatim sentences have common characteristics. For example, one person might use the word “issue,” whereas another person uses “problem.” But the net result is a negative sentiment.
WHY: Deep semantic similarity is key for mapping survey responses into the five overarching experiences. It helps us understand how one experience influences the satisfaction of other experiences. It’s more accurate than clustering and categorizing because it’s based on meaning—unlike other methods, which are based on similarity of format, number of letters, or words in common.
Before a survey goes out, the business stakeholders tag each survey question based on the experience it’s related to—for example, the meeting experience. However, when someone answers a survey question, the response that a person gives could be related to the finding experience more than the meeting experience. In other words, survey respondents might express high or low satisfaction about a different experience than how something was initially tagged. Having this information helps pinpoint which experiences to enhance. Deep semantic similarity allows us to uncover and share these types of discoveries with stakeholders.
HOW: Semantic similarity is measured based on the semantic distance between two terms. Semantic distance refers to how similar in meaning the terms are. First, all terms are converted into their lowest vocabulary form (for example, “searching” to “search”), and then the distance between their semantic scores is measured.
Advanced visualization techniques
We choose visualization techniques that best represent the results and give the most insights. For this solution, we use Power BI dashboards and open-source visualization tools. For example, we use Power BI dashboards to show whether sentiment tied to survey questions and responses about a user experience was positive, neutral, or negative.
Ability to operationalize and repeat
Much of the business value of data science lies in:
- The ability to make insights widely available and to repeat an end-to-end machine learning process as close as possible to the time when unstructured data is produced (after each survey, for example).
- The ability to connect insights. For example, to predict what the user feedback will be, we can connect survey insights that we get from verbatim analysis combined with Helpdesk insights that we get from Helpdesk tickets.
Having a robust data platform in place and a team of data engineers is key to enabling us to incorporate an end-to-end, repeatable machine learning process into our operations, so that we get the maximum business value.
Best practices
Along the way, we’ve learned some valuable lessons that help make our data collection and analysis run smoothly:
- Have a methodical, clearly defined strategy. A core part of our strategy is understanding the business context and questions that we need to answer. To chart our course, we always align with the five high-level experiences.
- Ensure variety. A good team needs diverse skill sets. Different perspectives and expertise yields deeper, richer insights. Typical skills required include machine learning, Data Lake, R and Python, and U-SQL.
- Fail fast/learn fast. We’re always iterating based on what has and hasn’t worked well.
- Reduce scope. We don’t want to overwhelm teams and executives with thousands of insights at one time. We focus on smaller, actionable, valuable pieces—like sentiment analysis.
- Use Power BI for self-service reporting. Power BI makes data visualization and reporting capabilities easy and widely available. Anyone can generate a report without having to wait on other people.
Summary
To enhance user experience across Microsoft products and services, we gather, process, and analyze data to learn where we can improve. We study products and services instrumentation. Also, we determine user sentiment by looking at data from user surveys that we distribute to employees and from Microsoft Helpdesk support data. We analyze text by using key phrase extraction, sentiment analysis, and deep semantic similarity algorithms. These methods and processes help us answer stakeholder questions, rank user satisfaction, and discover how an experience can be enhanced.




