





This content has been archived, and while it was correct at time of publication, it may no longer be accurate or reflect the current situation at Microsoft.
Moving the company’s revenue reporting platform to Microsoft Azure is giving Microsoft Digital the opportunity to redesign the platform’s infrastructure and functionality. With the major components in Azure, we’ve already seen how Spark Streaming and Azure Data Factory have made dramatic improvements in the platform’s performance and scalability. As our journey to host this solution in Azure continues, we’re finding new ways to improve it with Azure capabilities.
Microsoft Digital has moved the company’s revenue reporting platform, MS Sales, from on-premises datacenters to the cloud and Microsoft Azure. This is more than just a move to the cloud—it’s an opportunity to reimagine and redesign the way MS Sales infrastructure functions. To prepare for the migration, we examined several options for hosting MS Sales in Azure and came away with a clear direction for transition design, planning, and deployment.
MS Sales for revenue and sales data
MS Sales manages Microsoft product and service revenue data. Transaction data is conformed, aggregated, and enriched by MS Sales to provide accurate revenue reporting and analysis. MS Sales gives a consistent view of Microsoft businesses and production revenue, and it enables better, faster strategic decisions. People can query purchase, sales, budget, and forecast data and drill down to see more transaction details.
The MS Sales environment includes the following:
- Many thousands of users at Microsoft, which includes people in finance, sales, marketing, and executives.
- Large collection of internal and external data sources.
- Many years of sales data, depending on the reporting pivot.
- Millions of daily transactions.
MS Sales publishes data that’s aligned with the Microsoft financial calendar. The publishing processes include daily, weekly, and—the most critical—fiscal month-end (FME) data for restatement, forecasting, and budgeting. The restatement includes the attribution of past revenue into current business structures and product lines. The system needed more processing capacity to keep pace with the expanding number of revenue records and details.
We had been experiencing several challenges with the on-premises MS Sales environment, including limited scalability and agility, a complex ecosystem, cumbersome data-processing models, and increasing costs. The transition of Microsoft’s business model to services has created an exponential curve in the number of transactions. With the legacy design, we would reach the limit of processing to meet our service-level agreements (SLAs) to users. The goal in migrating MS Sales to Azure was to address these challenges and position MS Sales for success well into the future.
MS Sales previously
The MS Sales system was built 20 years ago to report Microsoft revenue. It’s the company’s standard revenue reporting system, and it is pivotal to strategic business, management, and financial decisions. Timely, accurate sales data is crucial to assessing Microsoft performance and maintaining a competitive position.
The original solution for MS Sales was hosted in on-premises datacenters and included:
- Fifty-three servers
- Thirty Microsoft SQL Server databases
- Approximately 35 TB of data storage
MS Sales components and functionality
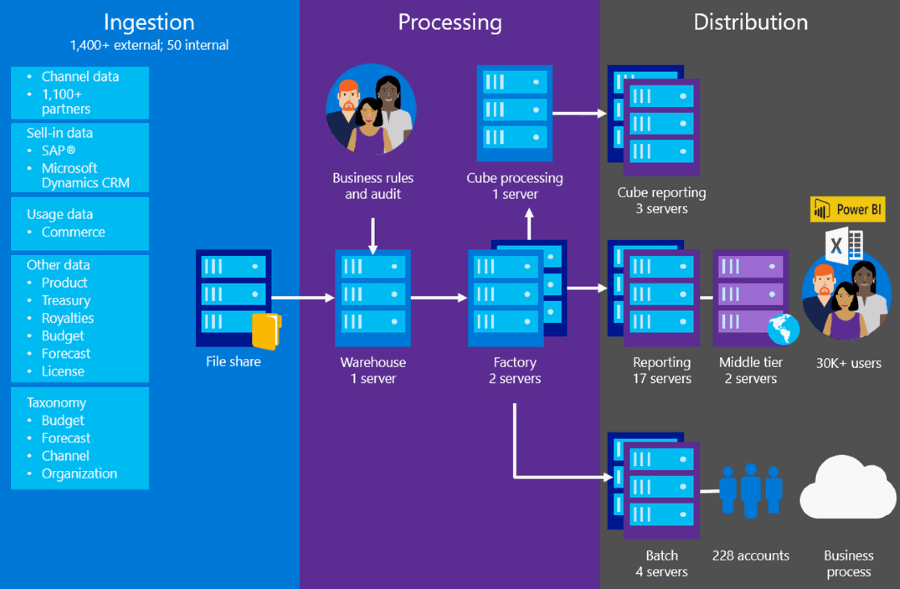
The original MS Sales architecture ingested data, processed and transformed significant data, created star schema data marts, and distributed these marts for querying and consumption by other systems. Querying was primarily via Microsoft Reporting Analytics (MSRA), an Excel add-in that generates and executes SQL queries based on the user’s definitions. The architecture supported five major functions:
- Ingestion. MS Sales ingests data from more than one thousand sources. Most of the sources are external partners, such as manufacturers, distributors, and retailers. With the original MS Sales, data was ingested through a process that was supported by SQL jobs, and Windows services data was batch loaded into the MS Sales Warehouse (a SQL database). One of our focus points in the next phase was to stream partner and customer data for ingestion.
- Warehouse. Ingested data ended up in the MS Sales Warehouse SQL Server database. Data from other sources—such as forecasting, budgeting, and planning data—and SAP were directly loaded here. The warehouse held approximately 5 TB of data.
- Factory. Data from the warehouse was log-shipped to the factory server, where all major business data was processed, and the final MS Sales database produced for reporting. Total factory data was about 4.5 TB of uncompressed data. Jobs were scheduled via NT Batch, and 15 complex stored procedures were executed. The factory server required a high level of processing capability. For example, in a continuing push to adopt hardware that could support MS Sales functionality, we moved the factory to a two-server architecture, using two 72-core servers with 2 TB of RAM to run factory processes in parallel.
- Distribution. As the MS Sales database was created, it was cloned to 18 reporting servers. Each reporting server hosted slightly more than 500 GB of compressed data. MS Sales data was copied to more than 220 other environments, where it was merged with other data for various reporting needs.
- User experience. The MSRA tool offers ad hoc query definition in a pivot table. Users could immediately schedule or execute queries. MSRA generates Transact-SQL (T-SQL) based on source-specific metadata. The T‑SQL is executed by a middle-tier server, and results are stored or retrieved immediately. Results are presented in an Excel PivotTable, where users can take full advantage of Excel capabilities. We have many thousands of MSRA users who can run ad hoc queries against MS Sales. Approximately three million queries were run in the past fiscal year.
Figure 1 illustrates the MS Sales on-premises infrastructure.
Redesigning MS Sales in the cloud
Our MS Sales cloud-based solution is based on several key goals:
- Scale and agility. We wanted an Azure-based solution that can scale to meet future data growth and changing business models.
- Speed. We wanted to increase the speed for MS Sales to ingest and generate data and process transactions.
- Complexity. We wanted to reduce the behavioral complexity of MS Sales and make the infrastructure and logical layout less complicated and easier to run.
- Combinability. We wanted to modernize the infrastructure to open new capabilities. We want to combine big data (such as marketing and usage) with core financials and use machine learning to give deeper insights into our sales.
MS Sales architecture in Azure
Azure allowed us to rethink data distribution and consumption in MS Sales and redefine what the data flow looks like. We are using many Azure-native and big data solutions for data processing, so we can generate more granular processing and reporting components. This greater level of granularity and native support for data manipulation leads to more parallel processes and quicker data delivery. The data flow components in the cloud include the following:
- Azure HDInsight and Apache Spark processing
- Azure Virtual Machines SQL Server 2016
- Azure Blob Storage
- Azure Data Factory
Incremental delivery
When we began the engineering program, we developed a programmatic approach to accomplish the redesign and migration. We first started with a thin slice of data that included several data sources. Our goal was to prove end-to-end functionality. However, this approach proved to be highly resource intensive. It would require 18 months for implementation of the entire system and risked missing SLAs as data volumes continued to grow.
We changed direction and decided to focus on the processing engine and distribution for the entire dataset. This approach allowed us to complete the project in 12 months, addressing the highest priority issues with the old system. To accomplish this, we needed to reduce scope and leave the ingestion and warehousing components operating in the legacy system, on-premises as depicted in Fig 2.
To ensure data parity and a completely reliable and manageable service, we operated the new Azure-based process in parallel with the legacy SQL processing in production for eight months.

Current data movement
For our interim hybrid solution, the data is batch loaded into Azure from the on-premises components each day. We use Azure Data Factory to lift data from the on-premises systems. We added event triggers into our on-premises SQL 2016 servers to transfer the data into blob storage as Parquet files. We separated the hot and cold data prior to implementing this function, transferring only current unprocessed transactions. Despite the streamlining, this approach creates a speed penalty, requiring around two hours to transfer the data.
Data ingestion future state
As we progress incrementally, we will use Azure Event Hubs as the primary method for data ingestion in MS Sales. Event Hubs makes it possible for us to process transactions from multiple sources and scale to handle transaction input. After pulling transactions, we will use Data Validation Services to ensure that the data coming into MS Sales corresponds with what we expect from our data providers. Data is compared to templates that we receive from our data providers and send through to Event Hubs if the data is valid.
Pipeline processing
We use Apache Spark to drive our big data processing tasks in MS Sales, most of our performance gains have come from converting our data pipeline.
Apache Spark processing
Processing scheduling is designed around business processes and optimized to save processing cost. Apache Spark processes the entire MS Sales dataset each week, this includes five terabytes of historical data, current and future projections. The restatement process requires reprocessing past revenue to map to current organizations and product lines. We initiate eight Spark clusters as batch data is transferred from the on-premises warehouse with 80 nodes each. We then begin processing 10 serial steps. This requires approximately 10 hours of Spark processing time.
Each day, the current month, previous month, and all future projections are processed, which requires two clusters of 40 nodes. This consumes approximately five hours of Spark processing time.
One of the primary success criteria for the new system was absolute parity between the on-premises processing and the Spark processing. This required granular data comparisons at each of the 10 steps through processing as well as additional engineering to create synthetic steps that didn’t exist in the on-premises factory. This allowed us to isolate issues into specific areas of the processing phase. Testing also required storage throttling because of the large volume of data transfer, which exceeded I/O capacity for some services. This was a beneficial lesson to learn because it is driving the prioritization of delta processing in the new solution.
Processing future state
Delta processing will enable the transition to streaming processing and closer to real-time transaction attribution. We estimate that this will reduce the daily processing by 50% by eliminating the reprocessing of static data and the associated I/O issues and costs. This will introduce variable timing into the system, depending on the level of change and processing required.
Current state pipeline output
After processing is complete, we use Spark connector to push each unique cluster output to a virtual machine running SQL. These databases are aggregated and then replicated to a scaled set of 10 to 20 query servers that are used for the distribution. This is based on client load and dynamically scaled as needed. This provides redundancy as well as load balancing to improve performance. Our reporting tool, MSRA, is configured to access the appropriate database instance for the user. This creates an additional penalty of four to five hours, transferring to the distribution environment, but it still enables a one-hour improvement over the existing on-premises system. The significantly improved processing speed keeps us aligned with our SLAs.
Future state pipeline output
The strategy for future output is to simplify and refine datasets for common use cases. The intent is to provide an interactive in-memory querying capability. This will provide 70% of users with a streamlined and fast interaction with the system, and it will work along with the current model to provide the large queries the business relies on today.
Future business rules
Business rules play a critical role in MS Sales functionality. Business rules define how data is represented in MS Sales. We took the opportunity to evaluate and optimize business-rules management within MS Sales, and adopted the following best practices:
- All rules can be updated in a prompt and inexpensive manner.
- Each rule is documented in a single, natural-language statement (although it can be implemented using more than one programming language or declaration).
- Each natural-language rule statement uses business terminology rather than database table or column names or program module names.
- Each natural-language rule is unambiguous and succinct (uses no more words than necessary).
- All natural-language rules are consistent in terms of vocabulary (terms used) and syntax (structure).
Incorporating these best practices into rules we build using Drools and JBoss makes it easier to check for rule conflicts, negative rule effects, and confirm data relationships within the ruleset taxonomy. Our rules are authored in Drools, published to our business rules Git repository, which is managed through Azure DevOps until the publishing phase, and then Spark processes the changes.
Using a declarative business-rules approach
Our business rules are created using a declarative approach, which makes the rules implementation process more flexible and makes it easier to create or redefine rules. Our natural-language rules are accessible to all of our stakeholders, which makes them easy to review, approve, or change and keeps our rules in a standard format that uses business terminology rather than database object names and obscure variables.
Testing and release
Our testing and release process for MS Sales has three primary phases to ensure that all functionality works as expected before full release:
- Testing and preproduction. In testing and preproduction, we analyzed the primary functions of MS Sales in Azure and focused on any areas where significant change has occurred. We focused on the following:
- Data ingestion patterns and use
- Testing comparison data between the on-premises and Azure versions
- Load testing and performance testing of the Azure solution to confirm initial estimates and look for optimization
- Production deployment refinement. We built the process and environment in our Continuous Integration/Continuous Deployment (CI/CD) pipeline, using configuration as code to automate deployment. The new system was completely provisioned and tested with live data, requiring three complete month-end parity checks before retiring the on-premises system.
- Pilot phase. The pilot phase includes a limited release to a group of users who are familiar with MS Sales and have a better-than-average understanding of its architecture and functionality. These users are helping us to test real-life usage patterns and find any issues that arise from day-to-day use.
- Public release. 100% of MS Sales users are viewing the data processed via the new system design.
Benefits and best practices
Although MS Sales is still migrating, we’ve already realized several benefits on the new platform. Many Microsoft business groups have adapted their business processes to the schedule and workflow in the original MS Sales version. With the new version, they’re finding that the faster processing time enables them to reexamine their business processes and redefine them to fit business demands rather than technical limitations. Here are the other benefits that we’ve experienced:
- Reduced SLA for large processing. End-to-end latency has been drastically reduced for the heaviest batch processes. We have improved overall publishing times by 30 percent. As MS Sales continues to evolve in Azure, we expect that number to shrink even further.
- Lift and shift. We found challenges with the lifted-and shifted distribution environments. We expended efforts to improve the processes while still maintaining a legacy design. Efforts to modernize the system would provide a larger ROI.
- Demonstrated scalability. The Azure components we’re using scale naturally and automatically to adapt to demand and volume. As a result, MS Sales can handle larger transaction volumes with a sublinear correlation in end-to-end time. For example, we ran 1,000 percent more transactions through MS Sales for testing, and end-to-end processing went from 42 minutes to 52 minutes, an increase of only 24 percent.
- Increased agility. We have moved away from the monolithic nature of the earlier code base, and we incorporate modern engineering practices into development of the next version of MS Sales. The distinct components of the new MS Sales can be modified apart from the rest of the solution. We can get new features incorporated more quickly using CI/CD.
There are still many areas of innovation happening in the MS Sales environment. The team is working to implement streaming data ingestion, modernizing distribution, and implementing decoupled business-rule functionality.


