Machine translation has become a crucial component in the advancing of global communication. Millions of people are using online translation systems and mobile applications to communicate across language barriers. Machine translation has made rapid advances in recent years with the deep learning wave.
Microsoft Research recently achieved a historic milestone in machine translation – human parity (opens in new tab) in translation of news articles from Chinese to English. Our state-of-the-art approach is a Neural Machine Translation system that utilizes tens of millions of parallel sentences from the news domain as training data. Such a huge amount of training data is only available for a handful of language pairs and only in particular domains, such as news and official proceedings.
Indeed, while there are about 7000 spoken languages in the world, most of the world languages do not have the large resources required to train a useable machine translation system. Moreover, even languages with a large amount of parallel data do not have informal style data such as spoken dialects or social media text that usually are quite different from formal written styles. It is quite difficult to acquire millions of parallel sentences for any language pair. On the other hand, finding monolingual data for any language is simpler.
on-demand event

Microsoft Research Forum Episode 3
Dive into the importance of globally inclusive and equitable AI, updates on AutoGen and MatterGen, explore novel new use cases for AI, and more.
We tackled the challenge of insufficient parallel data using a Semi-Supervised Universal Neural Machine Translation approach that requires only a few thousand parallel sentences for an extremely low-resource language to achieve a high-quality machine translation system. This exciting research (opens in new tab) will be presented at the 16th Annual Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-2018) (opens in new tab).

Figure 1 – Higher BLEU scores are not possible with low numbers of training examples.
As Figure 1 shows, it is impossible to achieve high quality translation accuracy with limited amount of training examples. Our proposed approach therefore focuses on scenarios in which a limited amount of training examples are available, for example only 6000 training examples.

Figure 2 – Modification of the encoder aspect of the Neural Machine Translation Encoder-Decoder framework.
The proposed system utilizes a transfer learning approach to share lexical and sentences-level representations across multiple source languages into one target language. The setup assumes multi-lingual translation from multiple source languages that include both high- and low-resource languages. Our main objective is to enable sharing of the learned models in order to benefit the low resource languages. Our system architecture adds two modifications to the Neural Machine Translation (NMT) Encoder-Decoder framework to enable Semi-Supervised Universal NMT. We mainly modify the encoder part, as shown in Figure 2. Note also,
- the lexical part is shared through a Universal Lexical Representation (ULR) to support multilingual word-level sharing;
- a model of experts represents the sentence-level sharing from all source languages that share the source encoders with all other languages.
Both modifications enable the low-resource language to utilize the word-level and sentence-level representations associated with higher resource languages.
ULR utilizes a pre-projection step that projects all word embeddings trained on monolingual corpus into a unified universal space. Pre-projection can be accomplished using seed dictionaries, small parallel data or unsupervised methods. As shown in Figure 3, we end up with a unified representation for all languages; in this example, all languages are projected into English representation. It is worth noting that the unified embedding space is projected from monolingual embeddings learned using word2vec, which is not optimized for translation tasks.
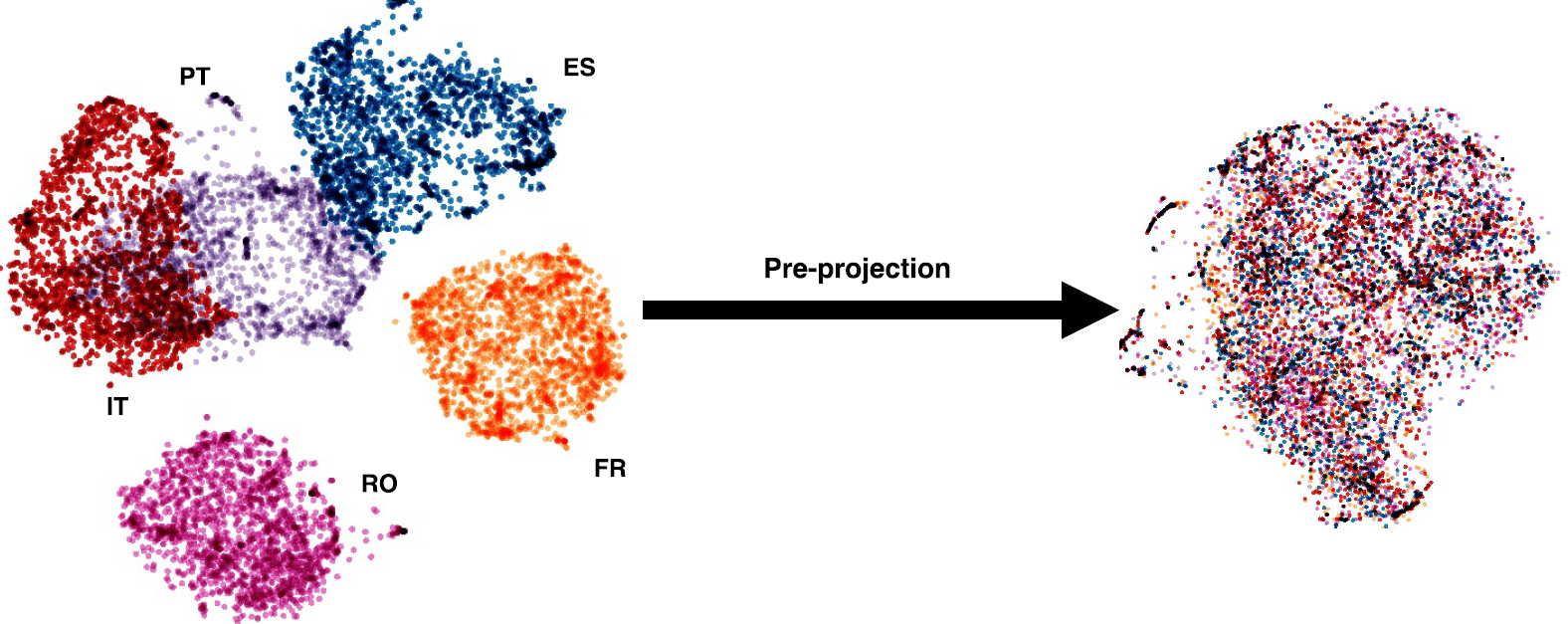
Figure 3 – ULR makes unified embedding for any word in any language possible.
With ULR, we can produce unified embedding for any word in any language. The NMT system is trained using limited multi-lingual data with optionally a small amount of data from the low-resource languages. Given any word in any language that was never observed in training data, the objective is to have a reasonable representation for such a word so that it can be translated. We propose a novel representation for multi-lingual embedding where each word from any language can be represented as a probabilistic mixture of universal space word embeddings. In this way, semantically similar words from different languages will naturally have similar representations. Our approach is based on Key-Query-Value representation on the embedding space and is illustrated in more detail in Figure 4.
For the purposes of illustration, imagine a scenario in which a multi-lingual system is being trained using parallel data from four languages Spanish (ES), French (FR), Italian (IT) and Portuguese (PT). We would like to use this system to translate Romanian (RO), assumed to be a low resource language with insufficient parallel data.
For any given Romanian word, such as “pisicile”, for example, we perform a query to find similar words from the universal embedding space depicted in Figure 3. The query is the word embedding from the monolingual embedding; the keys are the words in the universal embedding space. The values are weighted embedding that represents the given word in the universal space. ULR can handle unlimited multi-lingual vocabulary for any word that never observed in the parallel training data.
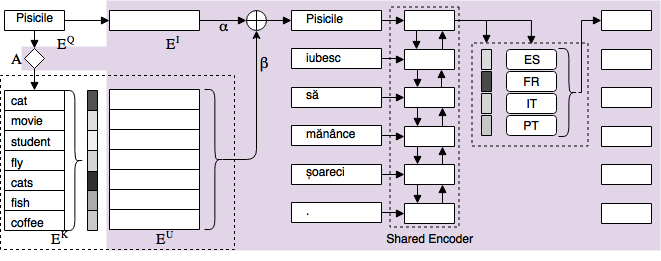
Figure 4 – System architecture with ULR and MoLE
A crucial issue is that the word embeddings are trained on monolingual data and not optimized toward the translation task. We added a trainable transformation matrix to the query matching mechanism (see A in the top left area of Figure 4) with the main purpose being to tune the similarity scores towards the translation task. As shown in Figure 5, words like “autumn”, “fall”, “spring” and “toamnă” (autumn in Romanian) would be quite similar from the monolingual embedding perspective, while “spring” should be less similar for a translation task. The transformation matrix achieves this objective.

Figure 5 –Tuning similarity scores toward the translation task.
As we advance toward the objective of universal embedding representation, it is crucial to have a language-sensitive module for the encoder that would help in modeling various language structures that may vary between different languages. Our solution is a Mixture of Language Experts (MoLE) module to model the sentence-level universal encoder. Figure 4 incorporates a MoLE module following the final layer of the encoder. A set of expert networks and a gating network adjusts the weight of each expert. In other words, the model is trained to learn how much information is needed from each language when translating the low resource language. The output of the MoLE module will be a weighted sum of these experts.
The NMT model learned to utilize different languages in different situations. In Figure 6, the darker the color of a square, the more relatedness exists between the Romanian and other languages for any given term. It is clear that MoLE is switching effectively between language experts when dealing with low-resource language words. In the upper part of the figure, we can see that the system is utilizing more knowledge from Greek and Czeck and to a lesser degree from German with almost no knowledge utilized from Finish. Whereas in the lower part of the figure, Italian, a more related language, was more utilized. Interestingly, the system learned that both Italian, part of same family of romance languages as Romanian, and Czech, not a Romance language but with a significant overlap with Romanian due to geographical proximity were both useful in translating Romanian.
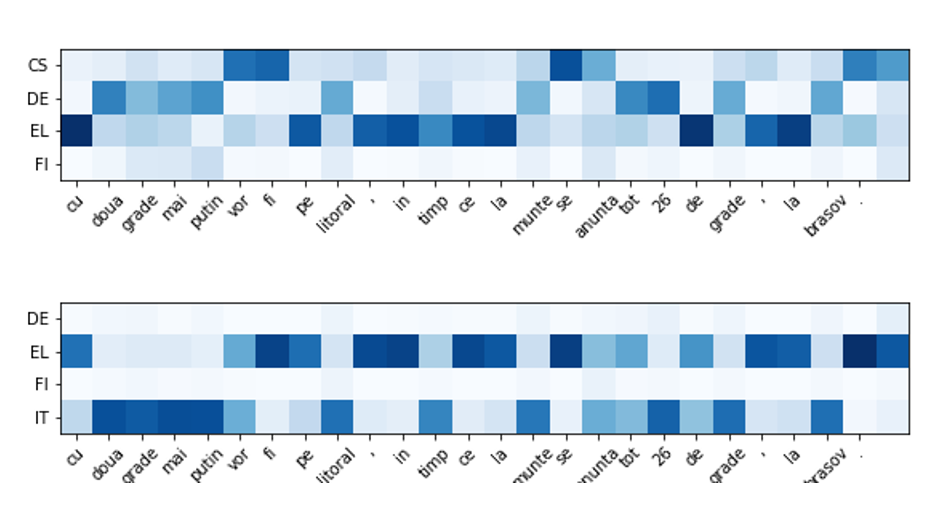
Figure 6 – MoLE in action.
In our experiments, we tried the proposed model in three scenarios. The first was a multi-lingual translation scenario in which the model learned to translate Romanian-to-English and Latvian-to-English using only 6000 parallel sentences of each language pair.
In the second scenario, we trained a model on high-resource languages first and then fine-tuned the model on a low resource language. In our experiments, the model successfully fine-tuned a multi-lingual system trained with zero Romanian-English parallel data using 6000 parallel sentences of Romanian-English. The system was able to reach nearly 20 BLEU, taking only two minutes to fine-tune a pre-trained model into a new language in a “zero-resource” translation setup.
In the third scenario, we adapted a system trained on standard Arabic-to-English translation to be used on a spoken Arabic dialect (Levantine) using no parallel data of the spoken dialect at all.
These approaches are enabling us to extend Microsoft Translator (opens in new tab) capabilities to support spoken dialects as well as low-resource languages such as Indic languages.
For more details, we encourage you to read our paper, Universal Neural Machine Translation for Extremely Low Resource Languages, (opens in new tab) to be presented at NAACL HLT (opens in new tab) 2018 in New Orleans.