

Enterprise Dictionary
Established: April 14, 2014
1. Project Introduction
“Everyday we are faced with a sea of acronyms, ever changing group structures, and fast-tracked projects.”
Currently, collation and curation of corporate knowledge is a painstaking manual process. We seek to move these activities into the background so that the relationships between different people, project updates, and emerging milestones can be surfaced in an ambient light-weight way.
This is our project: Enterprise Dictionary. It is a research project which aims to learn enterprise entities and their properties automatically from enterprise documents. It can gracefully collect information about workplace collaborations, project ebb-and-flows so that institutional knowledge can be easily gathered and shared.
The ultimate goal of our project is to build an Enterprise Satori. So that we can enable others to build knowledge-empowered applications in Enterprise.
2. Framework
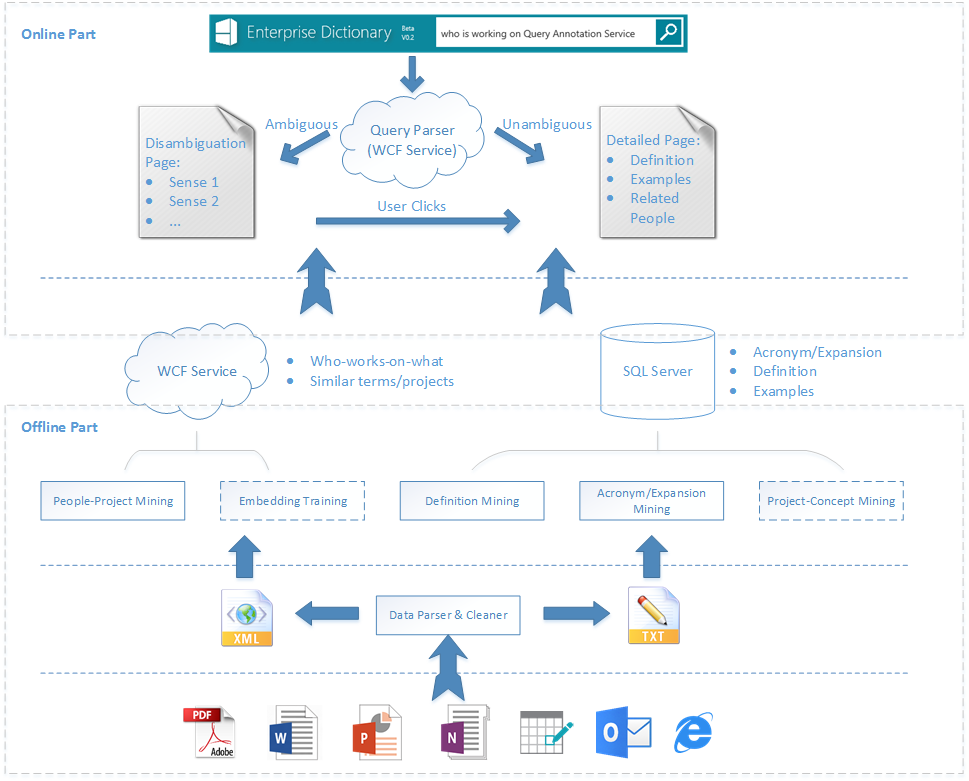
Our framework includes the offline part and the online part.
3. Offline Part
1) Data Source
Currently, we can handle different data sources, such as PDF, WORD, PPT, ONENOTE, MEETING, EMAIL, SharePoint/Web Page, etc.
2) Data Parser & Cleaner
We parse all data sources to two formats: XML and TXT.
XML is semi-structured. It can be used for semi-structured knowledge learning. E.g. Using the Kable’s technique to extract people-project relations.
TXT is unstructured. It can be used for acronym/expansion mining, definition mining, project-concept (type) mining, etc.
3) People-Project Mining
We apply Kable (semi-structure mining) technology to extract facts
Actually, the real technology is more complex than table extraction. We need to identify the “structure” first, then extract the “data”, followed by classify the content to it’s “function/property”, and then, build the association. This technology is successfully applied in Bing DU to automatic extract knowledge for Satori.
4) Definition Mining
We start from Hearst patterns, isA patterns, and some other patterns, e.g. “is a”, “is one of”, “means”, “stands for”, etc. to get the candidate definition sentences for each topic. We manually label some ground-truth for the definition, and use Rank SVM to train a linear classifier to classify whether it is definition or not. The features includes: NLP features, pattern features, data source, author, acronym, structure, statistical, symbol, conceptualization, embedding, keywords, etc.
Our discriminative features:
- Word Embedding (Implicit embedding)
- Conceptualization (Explicit embedding)
5) Acronym/Expansion Mining
Some patterns & rules are introduced to mine the acronym. For example, a full name followed by a bracket containing word with capital characters, e.g. Affinity Intent Map (AIM). Other patterns includes: a.k.a., f.k.a., etc.
After we get a set of acronyms, we make an assumption that the same acronym appeared in the same document should share the same semantic meaning. So, we link all acronym with the same expression in current document to the same extension.
6) Embedding Training (Ongoing)
We want to learn an implicit embedding for each term (word, or phrase) in Enterprise. So that we can measure the similarity between two projects.
We plan to leverage the AIM model for enterprise embedding training.
7) Project-Concept Mining (Ongoing)
We want to learn the concept (type) for each entity in Enterprise. E.g. we want to learn AIM is a Deep Learning Project, Word Embedding Project, etc.
So that we can learn an explicit embedding for each entity, and can support explicit topic reasoning for enterprise documents.
4. Online Part
1) Query Parser
Since we try to support question-like queries, we need a parser to understand users’ queries.
First, we extract question patterns from emails in “program manager information” discussion group, which is a place to let Microsoft employee ask questions to PM.
As soon as get the question pattern, we also get a set of “pseudo labels” as well as sentences for training. We apply our parallelized sequential RNN (which is similar to semi-CRF, we are working with Mei-Yuh team to apply this for Cortana) to parse/understand the query. And then generate related SQL to get the results.
Most of the queries are 1-hop, but, for “steven yao’s PM”, it is a 2-hop query. We decomposed it into “steven yao’s projects X” and “project X’s PM” to get the results.
The output of this parser includes:
- Query Term
- Type: including “(What) is”, “(Who) works on what”, and “Who works on (what)”, where (what) and (who) are the answers that users look for.
2) Disambiguation Page
If the user’s query is ambiguous, e.g. “AIM”, then we will return a page which contain different sense of this term as follow:
Then the user can pick up the sense of the term he looks for.
If the user search a term like “Who works on QAS”, we also try to distinguish the sense:
If user search a person’s name, e.g. “Ye-yi Wang”, we will try to return his projects directly:
3) Detailed Page
When the user pick up a sense of the term, we will return a detailed page, which includes three parts: definition, examples, and related people.
Contacts
 Zhongyuan Wang |
 Dawei Zhang |
Lei Ji |
 Jun Yan |
 Wei-Ying Ma |
Group
![]() Data Mining and Enterprise Intelligence Group, MSRA
Data Mining and Enterprise Intelligence Group, MSRA
People
Lei Ji
Senior Researcher