
By Vikas Sabharwal and Vineet Pruthi, Microsoft Shared Platform Group
In late 2011, Bing’s shared platform team started looking at different solutions for distributed NoSQL stores. We needed a fast, unified, distributed key value-store that is scalable and can be turned into a shared platform for many Bing internal partners. We wanted to serve lookups with low single-digit millisecond latencies. We added strong requirements for scale, latency, availability, and multi-tenancy. We set the following goals for us to meet in order to release a shared platform:
- Super-fast read latencies at high throughput targeting microseconds for local server look-ups.
- High availability of writes with low write latencies and high bandwidth; and eventual consistency.
- Share a physical server with multiple partners and dynamically combine workload variations that have different memory, storage, and load requirements.
- Schema awareness of data.
- Run on commodity hardware.
We realized there is no one-size-fits-all approach, and we wanted to allow different scenarios to use different indexing and storage techniques. We wanted to allow transparent and continuous migration from one storage engine to another while serving the traffic on the same data interface.
Spotlight: Microsoft research newsletter

Microsoft Research Newsletter
Stay connected to the research community at Microsoft.
We looked at some of the open source solutions available at that point in time, our effort started before some other solutions became mature enough. Our requirements related to availability, latency, and multitenancy made us take a different direction. We reached out to the Microsoft Research Team and worked closely with them to come up with a high-performance storage platform from the ground up.
We named our platform ObjectStore and started working on it. We came up with a group of core concepts we needed to build for our platform:
- Pluggable Storage Engine: Core storage engine, where implementation is easily swappable with different storage technologies and supports secondary indexes, like BW Tree.
- Coprocessors: Allow running C# or C++ code close to data; distributed compute for online serving.
- Data Replication & Recovery: Replicates sharded data at runtime to additional copies, and also assist in data recovery from good copies upon machine’s fatal failures.
- Multi-tenancy of different compute and storage workloads: Managed by centralized resource controller/allocator called Table Master.
- Availability, elasticity, manageability, and fast repairs: Continuous health monitoring and algorithms that move data around when needed within corpus of machines to achieve healthy state and higher availability for all tenants.
In this article we will focus on Pluggable Storage Engine, at later point we will share more details on Replication, Coprocessors, secondary indexes and automated repairs.
Pluggable Storage Engine
At Bing, we generate, process, and serve tons of data – and we wanted a solution to serve two classes of data update mechanisms for key-value store, extremely fast and efficiently. We settled for the following:
- Bulk Table: that are suitable for machine learning models, that needs consistent view across versioned data sets
- Point Table: that allow online updates and deletes as well; to serve scenarios like Bing rewards, fresh news feeds, fresh Wikipedia updates, etc.
Regardless of the model, we wanted to use a pluggable storage engine that would allow us to replace one storage type with another while sharing common components, such as request/response interface and data replication layer. We leveraged this plug-ability to serve these tables types.
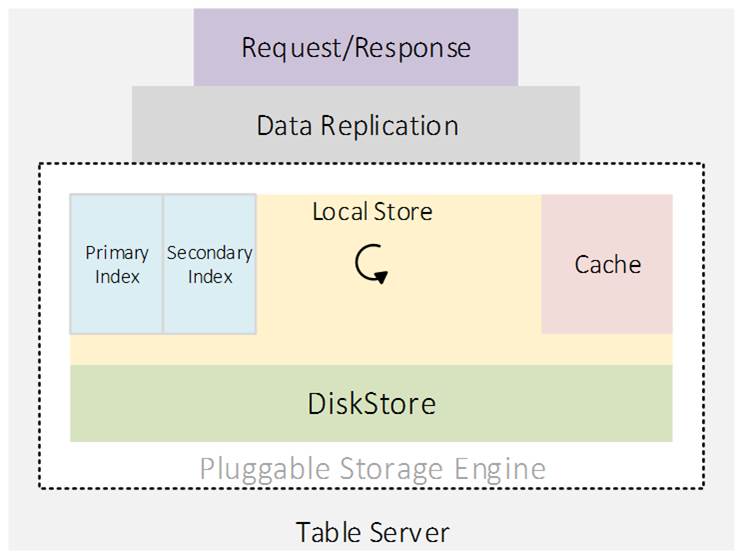
Figure 1 – Table Server
Bulk Tables – Read-Only Stores
This type of store supports read-only tables with very low memory utilization by leveraging minimum overhead per record. To achieve fast lookups, we keep the hash of the keys in memory while trying to keep a low memory consumption. We use the minimal perfect hashing (opens in new tab) algorithm. The data is loaded atomically into the storage engine on a different machine, without impacting lookup serving. Bulk stores allow for delta or full refresh of store with data publishing. We ensure that every request with multiple keys only hits same version of the data.
The entire data set is sharded into partitions, and each partition is divided into buckets which are created offline using Cosmos (opens in new tab) via the following procedure. All records within a bucket are split into groups of about 4 records. All groups are then sorted by the number of keys in them. For each group, we determine a factor F with a value between 0-255, such that there are no collisions, and at that point, the value is flipped with the position of a key in the bucket. The keys for which we do not have such a factor F get moved into a collisions table. We use 3 hash functions, one for identifying the bucket, one for the group, and one for the position of the value in the bucket. Empty spaces in array B are compressed while storing the ordered list of values into the data file. These files are then shipped to online Table Servers, for serving this key value space.
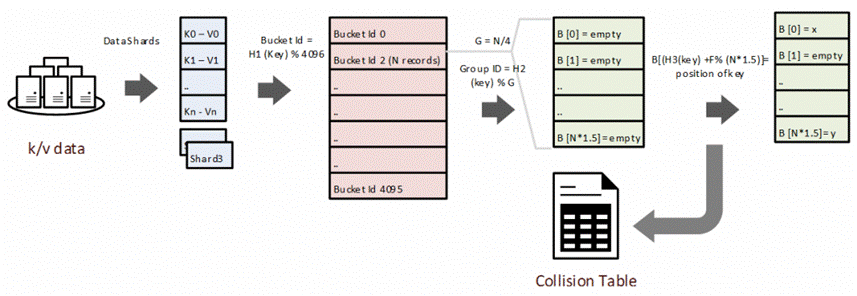
Figure 2 – Offline preparation of minimal perfect hash using map reduce
For every key in a read operation, 3 hashes are calculated. Every read key is served with about two in-memory look-ups – one to determine the bucket, and another one to find the position of the value for the key in loaded array of the group. Key collisions are served from collisions table.
Data loading is orchestrated by a centralized controller called Table Master. Each partition has at least 3 serving copies on different machines; we may pick more if we need to support higher load. During a new version of data rollout, we have more than 3 serving copies of data to support version consistency and higher availability for reads. Example, we add a 4th row of data with new version on different set of machines, and unload 1st row of old data once 4th row is successfully responding to queries. Whenever a new data rollout completes row-by-row, the old version of data is completely unloaded. Data rollout for each table is treated as separate rollout unit. Because this is happening for 100s of tables on 1000s of machines on demand, amount of additional spare capacity required for the 4th row is much smaller in magnitude.
This type of table is very useful for scenario with large keys, like machine learning models for URLs, because we only store a small key hash in memory. The typical memory footprint overhead is 14 bytes for bulk store implementation in ObjectStore.
Point Tables – Read/Write Stores
This type of store is quite different from the bulk table store. For each partition, we select a primary replica and 2 or more secondary replicas. Read operations go to any replica. Write operations go the primary replica and are sent to multiple secondary replicas as well. Writes are acknowledged to the client when a quorum of replicas on different machines accepts the write. We created our own metadata service to manage and push the information like shard distribution and primary election. The metadata changes are frequently based on heart-beats, process restarts, new data or compute workloads additions, primary lease expiration etc. The service is capable of sub-second responses to metadata changes, which is critical for keeping high availability for writes.
At the core, the LKRB point table uses linear hashing (opens in new tab) for this distributed hash table and has excellent lookup performance. It has been tested to yield more than 1M reads and writes per second each while offering sub milliseconds latencies. It is lock-free, contention-free implementation of CACM paper from 1988. It provides fast and stable performance irrespective of table size. The hash table expands/shrinks automatically without any performance penalty as the data in the table grows/shrinks. The LKRB hashtable implementation is highly customizable with options to configure space/time-based expiration, compression, persistence, caching, iterators etc. to name a few. They can be dynamically scaled up from MBs to TBs of data while offering the same performance guarantees.
Disk Store Design & Performance
Both Bulk and Point tables use the same underlying Disk store for persistence. The Disk store is an SSD optimized log-based storage. We collaborated with the Microsoft Research team to implement this persistence layer based on the FlashStore (opens in new tab) paper. This is a highly optimized implementation that yields 120K reads/sec with < 15 ms latencies at 99% percentile.

Figure 3 – Disk store layout
The log-based storage uses a circular file in which new writes for a key result in the previous occurrences of the key becoming garbage. We have a garbage collection algorithm that runs in the background and clears garbage records in conjunction with the in-memory LKRB hash table’s index. Records that are not garbage are re-written to the head of the file along with the new writes. The Disk store supports unbuffered overlapped I/O with async support. The Disk store supports batch API’s for parallel reads leveraging multiple channels of SSD.
Write operations are buffered and flushed to disk lazily, in a sequential asynchronous manner. We use a DiskLog component in the Replication stack, which is responsible for providing consistency for the newest writes not yet flushed to disk.
For reads, the in-memory index keeps the reference to the location of the value in cache or block where the record is stored on SSD. All writes are write-through cache, so the most recently updated or accessed records are always available in memory.
The same implementation also runs on HDD without any code modification; latencies are higher and throughput is somewhat slower for HDD based point tables due to media limitations.
Disk store also supports a sequential iterator that is used to send a full copy of the data from a healthy machine to another machine hosting the same shard. The Disk store also supports a fast disk recovery mechanism to reconstruct the in-memory index efficiently upon process restarts.
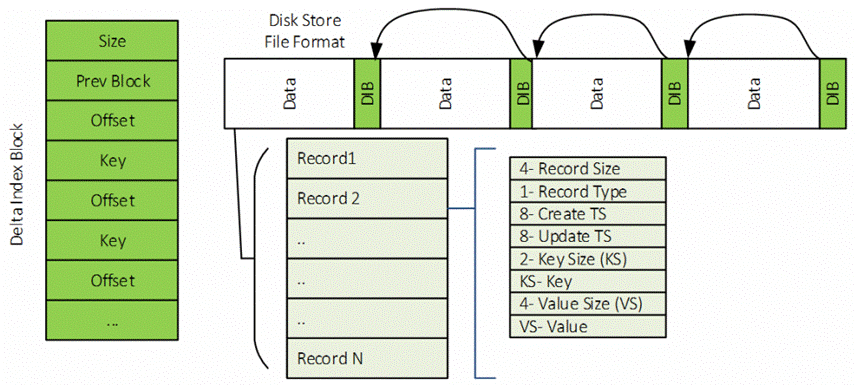
Figure 4 – Disk store record formats
The index is kept in memory to prevent 2 random disk accesses for reading a value. This architecture allows us to utilize terabyte-sized disks while maintaining read latencies under 5 ms for SSD depending on look-up rate and record sizes. However, upon process restarts we need to reconstruct the index in memory to find the data offsets again. We optimized this solution by persisting a list of changed keys and disk offsets to disk at regular intervals; we call this the “Delta Index Blocks.” The blocks are chained together using links from the current block to the previous one. On machine restart, the links are traversed from start to end of the disk and the memory index is reconstructed. The figure above shows how Delta Index Blocks are placed in the file and linked together. With this approach, we only read the keys from the disk bypassing the data, which helps us achieve very fast recovery times. For large disk tables (1TB), the recovery is completed in less than 5 minutes.
Performance
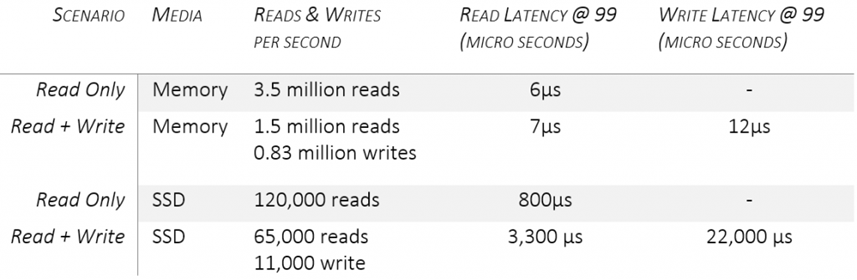
We measured the performance of in-memory and SSD tables. For in-memory tables, the entire data set is served from and updated into memory. Our implementation is able to achieve the following performance numbers when we execute the test on local machine for average record size of 2KB.
This article focuses on core storage engine implementation; performance of distributed store for remote look-ups are different.
Conclusion
This is a highly successful collaboration between the Bing shared platform team and the Microsoft Research team where we integrated the flash store with specialized indexing research work into a highly performant distributed storage system.
We put together a set of components and services which allowed us to offer a compelling platform as a service. The fully managed, multi-tenant and highly available service is a shared platform for many teams within Microsoft. The coprocessor execution on top of a fast underlying store for online workloads allows engineering teams to write customized, powerful scenarios. ObjectStore is currently serving thousands of tables and coprocessors within Bing, Cortana, online speller, query auto-complete, Skype, Entity Graph and Office 365.
References
- Cosmos (opens in new tab)
- Dynamic Hash Tables (opens in new tab)
- Minimal perfect Hashing (opens in new tab)
- Flash Store (opens in new tab)
- BW-tree paper (opens in new tab)
Would you like to work with Microsoft engineering teams on interesting challenges like those described above? Find information about working at Microsoft and search for openings (opens in new tab). Come join the team!



