![]()
By Alekh Agarwal and John Langford, Microsoft Research New York
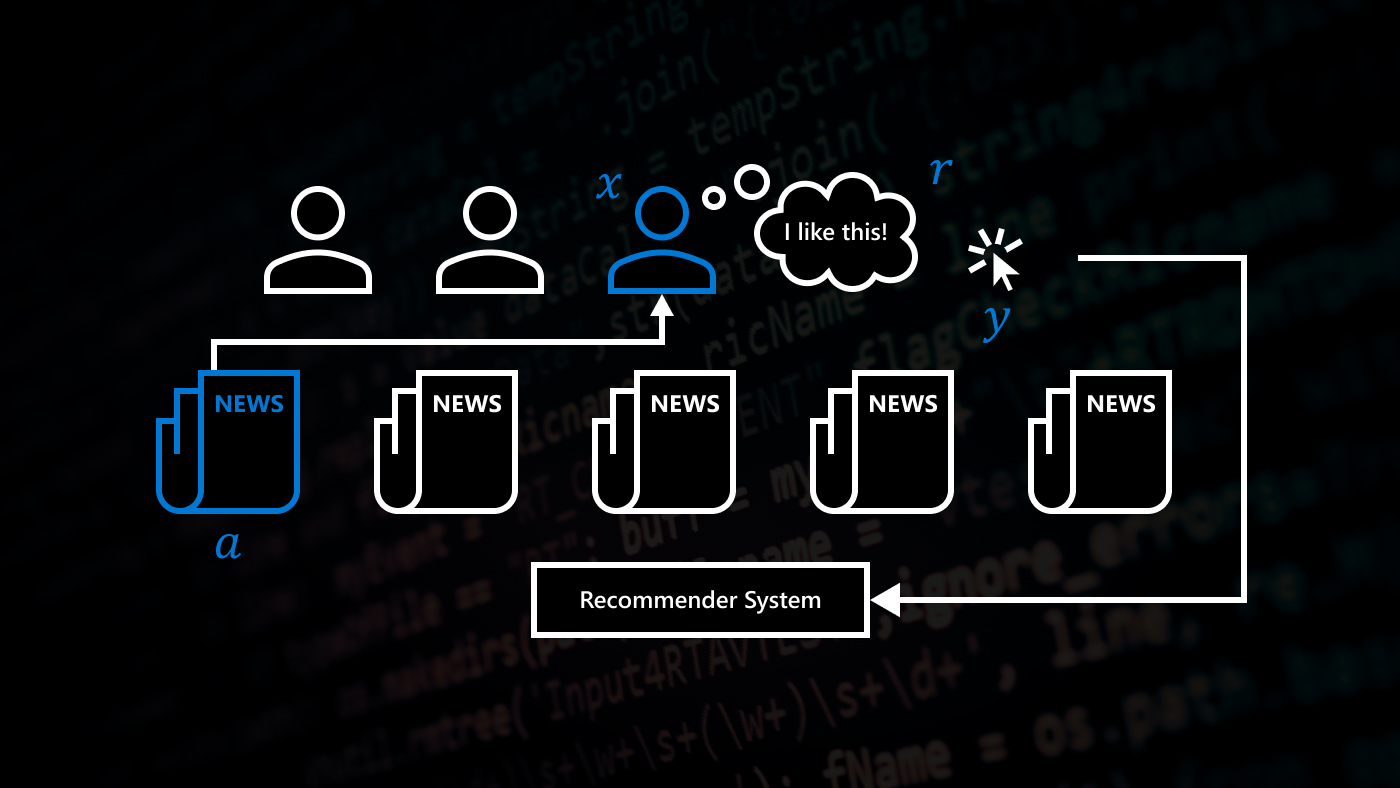
Clicks on Microsoft’s news website MSN.com increased 26 percent when a machine-learning system based on contextual-bandit algorithms was deployed in January 2016 to personalize news articles for individual users.
Spotlight: Blog post

Research Focus: Week of September 9, 2024
Investigating vulnerabilities in LLMs; A novel total-duration-aware (TDA) duration model for text-to-speech (TTS); Generative expert metric system through iterative prompt priming; Integrity protection in 5G fronthaul networks.
The same real world interactive learning technology is now available as a Microsoft Cognitive Service called the Custom Decision Service as well as via open source on GitHub. The core contextual-bandit algorithms are also available from Vowpal Wabbit, our team’s long-term fast-learning project.
We believe contextual-bandit learning is at the cusp of enabling a new class of applications just as new algorithms and large datasets powered breakthroughs in machine-learning tasks such as object recognition and speech recognition.
Tasks such as object recognition and speech recognition are based on a paradigm called supervised learning that uses tools such as classification and regression to successfully make predictions from large amounts of high-quality data. Crucially, each example is annotated with a label indicating the desired prediction such as the object contained in an image or the utterance corresponding to a speech waveform.
Supervised learning is a good fit for many practical questions, but fails in a far greater number of scenarios.
Consider, for example, a mobile health application that gives exercise recommendations to a user and judges the recommendation’s quality based on whether the recommendation was followed. Such feedback carries less information than a label in supervised learning; knowing that the user took an exercise recommendation does not immediately imply that it was the best one to give, nor do we find out whether a different recommendation would have been better.
A common work-around is to hire a labeler to label a few data points with the best recommendations. The success of such an approach relies on the ability of the labeler to intuit what the user might want, which is a tall order since the right answer might depend on factors such as how well the user slept the previous night or whether the user experienced a stressful commute.
Furthermore, the labeling approach ignores the readily available signal that the user provided by accepting or rejecting the recommendation. In addition, obtaining labels from a labeler can be a significant cost.
Exercise recommendation is a typical example of a scenario where supervised learning fails; many common applications exhibit a similar structure. Other examples include content recommendation for news, movies and products; displaying search results and ads; and building personalized text editors that autocorrect or autosuggest based on the history of a user and the task at hand.
Solving problems such as recommendation, ad and search result display, and personalization fall under the paradigm of interactive machine learning. In this paradigm, an agent first perceives the state of the world, then takes an action and observes the feedback. The feedback is typically interpreted as a reward for this action. The goal of an agent is to maximize its reward.
Reward-based learning is known as reinforcement learning. Recent reinforcement-learning successes include AlphaGo, a computer that beat the top-ranked human player of the ancient game of go, as well as computer agents that mastered a range of Atari video games such as Breakout.
Despite these game-playing breakthroughs, reinforcement learning remains notoriously hard to apply broadly across problems such as recommendation, ad and search result display, and personalization. That’s because reinforcement learning typically requires careful tuning, which limits success to narrow domains such as game playing.
Earlier this month, we presented our Tutorial on Real World Interactive Learning at the 2017 International Conference on Machine Learning in Sydney, Australia. The tutorial describes a paradigm for contextual-bandit learning, which is less finicky than general purpose reinforcement learning and yet significantly more applicable than supervised learning.
Contextual-bandit learning has been a focus of several researchers currently in the New York and Redmond labs of Microsoft Research. This paradigm builds on the observation that the key challenge in reinforcement learning is that an agent needs to optimize long-term rewards to succeed.
For example, a reinforcement-learning agent must make a large number of moves in the game of go before it finds out whether the game is won or lost. Once the outcome is revealed, the agent has little information about the role each individual move played in this outcome, a challenge known as credit assignment.
Contextual bandits avoid the challenge of credit assignment by assuming that all the relevant feedback about the quality of an action taken is summarized in a reward. Crucially, the next observation revealed by the world to the agent is not influenced by the preceding action. This might happen, for instance, in recommendation tasks where the choice presented to one user does not affect the experience of the next user.
Over the past decade, researchers now at Microsoft Research have gained a mature understanding of several foundational concepts key to contextual-bandit learning including a concept we call multiworld testing–the ability to collect the experience of a contextual-bandit-learning agent and predict what would have happened if the agent had acted in a different manner.
The most prevalent method to understand what would have happened is A/B testing, where the agent acts according to a pre-determined alternative behavior B some fraction of the time, such as recommending exercises to some users using a different rule. In multiworld testing, we can evaluate an alternative B without the agent ever explicitly acting according to it, or even knowing what it is in advance.
The science behind multiworld testing is well-established and now publicly available as a Microsoft Cognitive Service called the Custom Decision Service. The service applies to several of the scenarios discussed here including news recommendation, ad and search result display, and personalized text editors.
The Custom Decision Service is relatively easy to use. A few lines of Javascript code suffice to embed the service into an application, along with registering the application on a portal and specifying, in the simplest case, a RSS feed for the content to be personalized.
The Custom Decision Service uses other Microsoft Cognitive Services to extract features from the content automatically as well as information about a user such as location and browser. The contextual-bandit algorithms come up with a recommendation based on the user information. Real-time online learning algorithms update the Custom Decision Service’s internal state with feedback on the decision.
In addition, an application developer has access to all the data they collect via an Azure account they specify on the sign-up portal, which allows them to leverage the multiworld testing capabilities of contextual bandits to do things such as discover better features.
An open-source version of the Custom Decision Service is available on Github and the core contextual-bandit algorithms are available on Vowpal Wabbit.
Overall, contextual bandits fit many applications reasonably well and the techniques are mature enough that production-grade systems can be built on top of them for serving a wide array of applications. Just like the emergence of large datasets for supervised learning led to some practical applications, we believe the maturing of this area might be at the cusp of enabling a whole new class of applications.
Microsoft Researchers working on contextual bandit learning include John Langford, Rob Schapire, Miro Dudik, Alekh Agarwal and Alex Slivkins in the New York lab, and Sebastien Bubeck, Lihong Li and Adith Swaminathan in the Redmond lab.
Related:
- Check out the Tutorial on Real World Interactive Learning
- Learn more about the Custom Decision Service from Microsoft Cognitive Services
- Download the Custom Decision Service on GitHub
- Download the core contextual bandit algorithms from Vowpal Wabbit
- Learn more about Multiworld Testing