

By Tie-Yan Liu, Tao Qin, Bin Shao, Wei Chen, and Jiang Bian, Microsoft Research Asia
Machine learning is quite hot at present.
Technological innovation is a fundamental power behind economic growth. Among these innovations, the most important is what economists label “general technology,” such as the steam engine, internal combustion engine, and electric power. AI is the most important general technology in this era, with machine learning the most important focus within AI.
The focus of machine learning is to mimic the learning process of human beings: learning patterns or knowledge from empirical experiences, and then generalizing to similar new scenarios. It is a cross-disciplinary research field that includes computer science, statistics, function approximation, optimization, control theory, decision theory, computational complexity, and experimentation.
This article examines the following questions: What are the important concepts and key achievements regarding machine learning? What are the key skills that machine learning practitioners should have? Finally, what kind of future trends for machine learning technologies can we anticipate?
The Forefront of Machine Learning Technology
In recent years, researchers have developed and applied new machine learning technologies. These new technologies have driven many new application domains. Before we discuss that, we will first provide a brief introduction to a few important machine learning technologies, such as deep learning, reinforcement learning, adversarial learning, dual learning, transfer learning, distributed learning, and meta learning.
Deep learning
Based on multi-layer nonlinear neural networks, deep learning can learn directly from raw data, automatically extract and abstract features from layer to layer, and then achieve the goal of regression, classification, or ranking. Deep learning has made breakthroughs in computer vision, speech processing and natural language, and reached or even surpassed human level. The success of deep learning is mainly due to the three factors: big data, big model, and big computing.
In the past few decades, many different architectures of deep neural networks have been proposed, such as (1) convolutional neural networks, which are mostly used in image and video data processing, and have also been applied to sequential data such as text processing; (2) recurrent neural networks, which can process sequential data of variable length and have been widely used in natural language understanding and speech processing; (3) encoder-decoder framework, which is mostly used for image or sequence generation, such as machine translation, text summarization, and image captioning.
Reinforcement learning
Reinforcement learning is a sub-area of machine learning. It studies how agents take actions based on trial and error, so as to maximize some notion of cumulative reward in a dynamic system or environment. Due to its generality, the problem has also been studied in many other disciplines, such as game theory, control theory, operations research, information theory, multi-agent systems, swarm intelligence, statistics, and genetic algorithms.
In March 2016, AlphaGo, a computer program that plays the board game Go, beat Lee Sedol in a five-game match. This was the first time a computer Go program had beaten a 9-dan (highest rank) professional without handicaps. AlphaGo is based on deep convolutional neural networks and reinforcement learning. AlphaGo’s victory was a major milestone in artificial intelligence and it has also made reinforcement learning a hot research area in the field of machine learning.
Transfer learning
The goal of transfer learning is to transfer the model or knowledge obtained from a source task to the target task, in order to resolve the issues of insufficient training data in the target task. The rationality of doing so lies in that usually the source and target tasks have inter-correlations, and therefore either the features, samples, or models in the source task might provide useful information for us to better solve the target task. Transfer learning is a hot research topic in recent years, with many problems still waiting to be solved in this space.
Adversarial learning
The conventional deep generative model has a potential problem: the model tends to generate extreme instances to maximize the probabilistic likelihood, which will hurt its performance. Adversarial learning utilizes the adversarial behaviors (e.g., generating adversarial instances or training an adversarial model) to enhance the robustness of the model and improve the quality of the generated data. In recent years, one of the most promising unsupervised learning technologies, generative adversarial networks (GAN), has already been successfully applied to image, speech, and text.
Dual learning
Dual learning is a new learning paradigm, the basic idea of which is to use the primal-dual structure between machine learning tasks to obtain effective feedback/regularization, and guide and strengthen the learning process, thus reducing the requirement of large-scale labeled data for deep learning. The idea of dual learning has been applied to many problems in machine learning, including machine translation, image style conversion, question answering and generation, image classification and generation, text classification and generation, image-to-text, and text-to-image.
Distributed machine learning
Distributed computation will speed up machine learning algorithms, significantly improve their efficiency, and thus enlarge their application. When distributed meets machine learning, more than just implementing the machine learning algorithms in parallel is required.
Meta learning
Meta learning is an emerging research direction in machine learning. Roughly speaking, meta learning concerns learning how to learn, and focuses on the understanding and adaptation of the learning itself, instead of just completing a specific learning task. That is, a meta learner needs to be able to evaluate its own learning methods and adjust its own learning methods according to specific learning tasks.
The Challenges Facing Machine Learning
While there has been much progress in machine learning, there are also challenges.
For example, the mainstream machine learning technologies are black-box approaches, making us concerned about their potential risks. To tackle this challenge, we may want to make machine learning more explainable and controllable. As another example, the computational complexity of machine learning algorithms is usually very high and we may want to invent lightweight algorithms or implementations. Furthermore, in many domains such as physics, chemistry, biology, and social sciences, people usually seek elegantly simple equations (e.g., the Schrödinger equation) to uncover the underlying laws behind various phenomena. In the field of machine learning, can we reveal simple laws instead of designing more complex models for data fitting? Although there are many challenges, we are still very optimistic about the future of machine learning. As we look forward to the future, here are what we think the research hotspots in the next ten years will be.
Explainable machine learning
Machine learning, especially deep learning, evolves rapidly. The ability gap between machine and human on many complex cognitive tasks becomes narrower and narrower. However, we are still in the very early stage in terms of explaining why those effective models work and how they work.
What is missing: the gap between correlation and causation
Most machine learning techniques, especially the statistical ones, depend highly on data correlation to make predictions and analyses. In contrast, rational humans tend to reply on clear and trustworthy causality relations obtained via logical reasoning on real and clear facts. It is one of the core goals of explainable machine learning to transition from solving problems by data correlation to solving problems by logical reasoning.
Explanation shows us the machine understands the known and is aware of the unknown
Machine learning models analyze and make decisions based on historical data. Due to their lack of common sense, machines may make basic mistakes that humans would not when facing unseen or rare events. In such cases, the statistical accuracy rate cannot effectively measure the risk of a decision. Sometimes, the reasoning behind a seemingly correct decision might be totally wrong. For the fields such as medical treatment, nuclear, and aerospace, understanding the supporting facts of decisions is a prerequisite for applying machine learning techniques, as explainability implies trustworthiness and reliability.
Explainable machine learning is an important stepping stone to the deep integration of machine learning techniques and human society. The demands of explainable machine learning come not only from the quest for advancement in technology, but also from many non-technical considerations including laws and regulations such as GDPR (General Data Protection Regulation), which took effect in 2018. GDPR gives an individual the right to obtain an explanation of an automated decision, such as an automatic refusal of an online credit application.
Besides the demands of industry and the society, it is the built-in ability and desire of the human brain to explain the rationale behind actions. Michael S. Gazzaniga, a pioneer researcher in cognitive neuroscience, has made the following observation from his influential split-brain research: “[the brain] is driven to seek explanations or causes for events.”
Who explains and to whom: people-centric machine learning evolution
Machines need to be able to explain themselves to both experts and laypeople. Ideally, a machine gives the answer to a question and explains the reasoning process itself. However, it is not possible for many machines to explain their own answers because many algorithms use the Data-In, Model-Out paradigm; where the causality between the model output and its input data becomes untraceable, such that the model becomes a so-called magical black box.
Before machines can explain their own answers, they can provide a certain level of explainability via human reviews and retracing the problem-solving steps. In this case, the explainability of each module becomes crucial. For a large machine learning system, the explainability of the whole depends on the explainability of its parts. The transition from black-box machine learning to explainable machine learning needs a systematic evolution and upgrade, from theory to algorithm to system implementation.
Explainability: stems from practical needs and evolves constantly
The requirements of explainability can be very different for different applications. Sometimes, the explanations aimed at experts are good enough, especially when they are used only for the security review of a technique. For other applications, everybody requires explanations, especially when they are part of the human-machine interface. Any technique works only to a certain degree within a certain application range and the same is true for explainable machine learning. Explainable machine learning stems from practical demands and will continue to evolve as more needs come out.
Lightweight machine learning and edge computing
In an ideal environment, edge computing refers to analyzing and processing data near the data generation source, to decrease the flow of data and thereby reduce network traffic and response time. With the rise of the Internet of Things and the widespread use of AI in mobile scenarios, the combination of machine learning and edge computing has become particularly important.
Why will edge computing play an important role in this embedded computing paradigm of machine learning?
- Data transmission bandwidth and task response delay: In a mobile scenario, while training over a large amount of data, machine learning tasks indeed require shorter response delays.
- Security: Edge devices can guarantee the security of the sensitive data collected. At the same time, edge computing can decentralize intelligent edge devices and reduce the risk of DDoS attacks affecting the entire network.
- Customized learning tasks: Edge computing enables different edge devices to take on learning tasks and models for which they are best designed.
- Multi-agent collaboration: Edge devices can also model multi-agent scenarios, helping to train multi-intelligent collaborative reinforcement learning models.
Quantum machine learning
Quantum machine learning is an emerging interdisciplinary research area at the intersection of quantum computing and machine learning.
Quantum computers use effects such as quantum coherence and quantum entanglement to process information, which is fundamentally different from classical computers. Quantum algorithms have surpassed the best classical algorithms in several problems (e.g., searching for an unsorted database, inverting a sparse matrix), which we call quantum acceleration.
When quantum computing meets machine learning, it can be a mutually beneficial and reinforcing process, as it allows us to take advantage of quantum computing to improve the performance of classical machine learning algorithms. In addition, we can also use the machine learning algorithms (on classic computers) to analyze and improve quantum computing systems.
Quantum machine learning algorithms based on linear algebra
Many quantum machine learning algorithms are based on variants of quantum algorithms for solving linear equations, which can efficiently solve N-variable linear equations with complexity of O(log2 N) under certain conditions. The quantum matrix inversion algorithm can accelerate many machine learning methods, such as least square linear regression, least square version of support vector machine, Gaussian process, and more. The training of these algorithms can be simplified to solve linear equations. The key bottleneck of this type of quantum machine learning algorithms is data input—that is, how to initialize the quantum system with the entire data set. Although efficient data-input algorithms exist for certain situations, how to efficiently input data into a quantum system is as yet unknown for most cases.
Quantum reinforcement learning
In quantum reinforcement learning, a quantum agent interacts with the classical environment to obtain rewards from the environment, so as to adjust and improve its behavioral strategies. In some cases, it achieves quantum acceleration by the quantum processing capabilities of the agent or the possibility of exploring the environment through quantum superposition. Such algorithms have been proposed in superconducting circuits and systems of trapped ions.
Quantum deep learning
Dedicated quantum information processors, such as quantum annealers and programmable photonic circuits, are well suited for building deep quantum networks. The simplest deep quantum network is the Boltzmann machine. The classical Boltzmann machine consists of bits with tunable interactions and is trained by adjusting the interaction of these bits so that the distribution of its expression conforms to the statistics of the data. To quantize the Boltzmann machine, the neural network can simply be represented as a set of interacting quantum spins that correspond to an adjustable Ising model. Then, by initializing the input neurons in the Boltzmann machine to a fixed state and allowing the system to heat up, we can read out the output qubits to get the result.
The quantum annealing device is a dedicated quantum information processor that is easier to build and expand than a general-purpose quantum computer; and examples are already in use, such as the D-Wave computer.
Simple and elegant natural laws
Complex phenomena and systems are everywhere. Inspecting them thoroughly, we come to a surprising conclusion: many seemingly complex natural phenomena are governed by simple and elegant mathematical laws such as partial differential equations. Stephen Wolfram, the creator of Mathematica, computer scientist, and physicist, makes the following observation: “It turns out that almost all the traditional mathematical models that have been used in physics and other areas of science are ultimately based on partial differential equations.”
Now that simple and elegant natural laws are prevalent, could we devise a computational method that can automatically discover the mathematical laws governing natural phenomena? It is clearly difficult, but not impossible. A certain kind of equality must exist in any equation. An intriguing question is: are there universal intrinsic equality rules in nature? The insightful Noether’s theorem, discovered by German mathematician Emmy Noether, states that a continuous symmetry property implies a conservation law. This profound theorem provides important theoretical guidance on the discovery of conservation laws, especially for physical systems. In fact, many physical equations are based on conservation laws, such as the Schrödinger equation, which describes a quantum system based on the energy conservation law.
Researchers have been exploring all kinds of possibilities based on the insight given by Noether. Schmidt and Lipson proposed an automatic natural law discovery method in their Science 2009 paper. Based on the conserved quantities of natural phenomena, the method distills natural laws from experimental data by using evolutionary algorithms. The paper tries to answer the following question: since many invariant equations exist for a given experimental dataset, how do we identify the nontrivial relations? It is nearly impossible to give a rigorous mathematical answer to this question. Schmidt and Lipson provided their practical insight on this: a meaningful conservation equation should be able to predict the dynamic relations between the subcomponents of a system. Specifically, it should be able to describe the relations between derivatives of variables over time.
Improvisational learning
The improvisational learning approach discussed here shares similar goals with the predictive learning advocated by Yann LeCun. However, they have very different assumptions of the world and take different approaches. Predictive learning comes from unsupervised learning, focusing on the ability of predicting into the future. It tries to make full use of the available information, to infer the future from the past.
Predictive learning consists of two core parts: building the world model and predicting the unknown. But, is the world predictable? We do not know.
Improvisational learning, in contrast, assumes that the world is full of exceptions. Being intelligent means improvising when unexpected events happen. To be improvisational, a learning system must not be optimized for preset static goals. Intuitively, the system conducts constant self-driven improvements instead of being optimized via the gradients toward a preset goal. In other words, improvisational learning acquires knowledge and problem-solving abilities via proactive observations and interactions.
Improvisational learning learns from positive and negative feedback by observing the environment and interacting with it. The process seemingly resembles that of reinforcement learning. The difference comes from the fact that improvisational learning does not have a fixed optimization goal, while reinforcement learning requires one. Since improvisational learning is not driven by the gradient derived from a fixed optimization goal, what is the learning driven by? When will this learning process terminate? Here, we use conditional entropy for a rough description and explanation of the process.
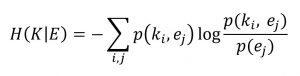
In this formula, K is the knowledge the system currently has and E is the information (negative entropy) of the environment. The formula measures the amount of uncertainty of the environment relative to the system. As the system learns more about the environment, negative entropy flows from the environment to the system and the uncertainty about the environment decreases. Eventually, the conditional entropy goes to zero and the negative entropy flow stops. By then, the system fully understands the environment.
Social machine learning
Machine learning aims to imitate how humans learn. While we have developed successful machine learning algorithms, until now we have ignored one important fact: humans are social. Each of us is one part of the total society and it is difficult for us to live, learn, and improve ourselves, alone and isolated. Therefore, we should design machines with social properties. Can we let machines evolve by imitating human society so as to achieve more effective, intelligent, interpretable “social machine learning”?
The idea of social is constituted of billions of humans and thus social machine learning should also be a multi-agent system with individual machines. Beyond collecting and processing data by using existing machine learning algorithms, machines participate in social interactions. For example, machines will actively cooperate with other machines to collect information, overtake sub-tasks, and receive rewards, according to social mechanisms. At the same time, machines will summarize the experiences, increase their knowledge, and learn from others to improve their behavior.
Actually, some of the existing methods in machine learning are inspired by social machine learning. For example, knowledge distillation, which is described as the most simplified influence among machines, may potentially model the way humans receive knowledge; model average, model ensemble, and voting in distributed machine learning are simple social decision-making mechanisms. Reinforcement learning investigates how agents adjust their behavior to get more rewards.
Since humans are social, social machine learning will be a promising direction to enhance artificial intelligence.
In Conclusion
Early computer scientist Alan Kay said, “The best way to predict the future is to create it.” Therefore, all machine learning practitioners, whether scholars or engineers, professors or students, need to work together to advance these important research topics. Together, we will not just predict the future, but create it.