

Central to our Microsoft Academic project is a machine reader that understands and tags the concepts mentioned in each paragraph. The concept tags are then used to cluster the documents for organizing the concepts into a taxonomy that plays a key role in semantic search and recommendations. A frequently asked question is whether we can share the underlying technologies in concept tagging and automatic taxonomy learning so that users can apply them to documents such as proprietary research papers, policy analyses, grant proposals, and others not currently included in Microsoft Academic Graph (MAG). We are announcing today that users can do so with the software package LanguageSimilarity, now distributed with MAG.
Before diving into the details of this new package, let’s start with a quick overview on what we have done to semantically understand publications indexed by MAG.
Our previous blog (opens in new tab) described how we leverage data mining and machine reading technologies to discover concepts and automatically tag them to publications. To address the document‑concept tagging problem, we use not only the linguistic information from each publication, but also signals from the topological structure surrounding the publication in MAG, such as where it is published, and what other articles the publication cites and receives citations from. The tagging results are published as the “PaperFieldsOfStudy.txt” stream in MAG and are surfaced in the Microsoft Academic website as follows:

In this example, several concepts, such as Word2vec, Distributional semantics, Natural language processing, Artificial intelligence, and Computer science (all circled above), do not appear explicitly as keywords in the text body of the article. However, our algorithm can understand the semantic meaning in the text by using the latent signals derived from the language and graph topology, as mentioned above. Since the algorithm and tagging results learn with new publication data (more details are available in [Shen, et al, ACL 2018 (opens in new tab)]), each version of MAG releases concept tagging results that reflect improved tagging quality.
We have previously made available, through Microsoft Cognitive Services, an early version of our semantic tagging technology as an API called Similarity (opens in new tab). Since its release, it has been successfully applied to various document collections. However, the monthly cap on the Similarity API prevents many users from testing and realizing the full potential of the technology. The LanguageSimilarity package is the response to such feedback: instead of having an online API, we package the pre‑trained models and concept‑tagging algorithms as a software tool that executes in the end user’s environment. Our customers can also tag, compare, and rebuild concept hierarchies based on any private corpus that they would not want to send over the internet‑based API.
There are three API methods in the package and they implement the following functions:
- float ComputeSimilarity(string text1, string text2) — Generate a score (ranging from 0 to 1) to measure semantic similarity between two given texts, which is similar to the Similarity (opens in new tab) API in the Microsoft Cognitive Services, but with a more advanced language model.
- float ComputeSimilarity(string text, long fieldOfStudyId) — Generate a score (ranging from 0 to 1) to measure semantic similarity between a given text and a given concept (called “field of study”) by its MAG ID.
- IEnumerable<Tuple<long,float>> GetTopFieldsOfStudy(string text, int maxCount=100, int minScore=0) — Generate a list of concepts (“field of study” in MAG) for a given text with similarity scores. Users can specify optional parameters, such as maximum number of concepts returned and/or minimum similarity score returned.
Please note that for now we are not using any topological structure signals from MAG for concept tagging in the GetTopFieldsOfStudy API, i.e., only input linguistic features are considered. Accordingly, when the exact title and abstract from a publication in MAG is supplied as the input to the GetTopFieldsOfStudy API, it may not return the exact set of tagging concepts published in MAG. In the future, we plan to release another software package that computes node similarities based on their topological constructs in MAG.
The LanguageSimilarity package is distributed as a single .zip file. It includes the algorithms, wrapped in dlls and a binary resource directory containing the pre‑trained models. After unzipping the package, users will see a folder structure as shown in the figure below. README.md and README.txt contain the general information about the package, system requirements, and API signature definitions.

We include a C# demo project in the LanguageSimilarityExample folder that also has the file sample.txt as the sample input for the demo, where each line contains the parameter(s) for an API call.
The demo is a console program that reads in the resource file directory and the path of the sample.txt file to initialize the LanguageSimilarity model:

As you can see from the source code of sample.txt, each line is a command to an API call. Three examples are illustrated below:

Example 1: call ComputeSimilarity (string text1, string text2) to compute the similarity scores of any two given texts.
The input row:
Column 1: command 1, i.e., call the ComputeSimilarity (string text1, string text2) API.
Column 2: a text paragraph as argument 1 to the call. This example uses a description of a speech understanding system.
A speech understanding system includes a language model comprising a combination of an N‑gram language model and a context-free grammar language model. The language model stores information related to words and semantic information to be recognized. A module is adapted to receive input from a user and capture the input for processing. The module is further adapted to receive SALT application program interfaces pertaining to recognition of the input. The module is configured to process the SALT application program interfaces and the input to ascertain semantic information pertaining to the first portion of the input, and then output a semantic object comprising text and semantic information for the first portion by accessing the language model, wherein performing recognition and outputting the semantic object are performed while capturing continues for subsequent portions of the input.
Column 3: the second paragraph to be compared. This example uses a patent abstract as follows:
A method and system provide a speech input mode that dynamically reports partial semantic parses, while audio captioning is still in progress. The semantic parses can be evaluated with an outcome immediately reported back to the user. The net effect is that task conventionally performed in the system turn are now carried out in the midst of the user turn, thereby presenting a significant departure from the turn‑taking nature of a spoken dialogue.
Output: a similarity score between the two paragraphs, which in this example is 0.8210485, thus indicating a high semantic similarity.

Example 2: call ComputeSimilarity (string text, long fieldOfStudyId) to compute how much a given text is similar to a concept in MAG, as specified by its entity ID. This example uses another patent summary and compares the paragraph with the “Closed caption” concept of the ID “157657479.”
Input row: three tab‑separated columns.
Column 1: 2 (for ComputeSimilarity (string text, long fieldOfStudyId) API).
Column 2: concept entity ID.
Column 3: text1.

Output: a semantic similarity score of 0.5344269, also indicating a high similarity.

Example 3: call GetTopFieldsOfStudy(string text, int maxCount=100, int minScore=0) to tag a given text with concepts, with the thresholds set to return at most 10 concepts (maxCount=10) and similarity scores greater than or equal to 0.4 (minScore=0.4).
Input row: four tab‑separated columns.
Column 1: 3 (for GetTopFieldsOfStudy API).
Column 2: maximum number of concepts to be returned.
Column 3: minimum similarity score to be returned.
Column 4: text as shown below.

Output: the list of concepts, ordered by the descending similarity scores.
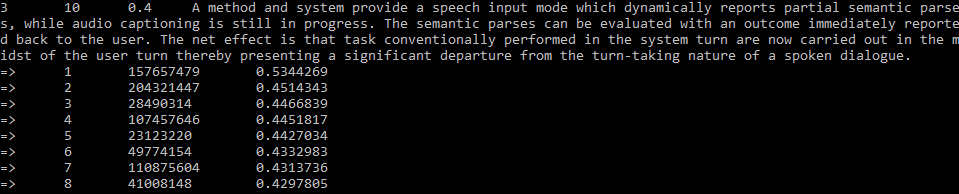
Again, both the input and the output concepts are represented by a long Field‑of‑Study entity ID defined in MAG that can be looked up in the “FieldsOfStudy.txt” stream in MAG.
Starting from the 2019‑05‑16 release version, we have included the LanguageSimilarity package in the MAG distribution to selected customers. It is refreshed every two weeks (the same cadence as MAG releases) to reflect the latest knowledge the algorithms learn while reading newly published articles. Currently, we provide this package for .NET framework and the technology works the best on English documents, as the language models on titles and abstracts are all trained with English papers in MAG. If you would like to receive this package with your MAG distribution, please contact us at academicapi@microsoft.com (opens in new tab).
We will continue to make improvements, provide new features on MAG, and announce them here. If you use this software for research, please cite our ACL paper (opens in new tab) so that we can follow how the software is used.
Happy researching!