
CURE Dataset: Ladder Networks for Audio Event Classification
- Harishchandra Dubey ,
- Dimitra Emmanouilidou ,
- Ivan Tashev
2019 IEEE Pacific Rim Conference on Communications, Computers and Signal Processing (PacRim) |
Published by IEEE
Audio event classification is an important task for several applications such as surveillance, audio, video and multimedia retrieval etc. There are approximately 340 million people with hearing loss who can’t perceive events happening around them. This paper establishes the CURE dataset which contains curated set of specific audio events most relevant for people with hearing loss. It is formatted as 5 sec sound recordings derived from the Freesound project. We propose a ladder network based audio event classifier. We adopted the state-of-the-art convolutional neural network (CNN) embeddings as audio features for this task. We start with signal and feature normalization that aims to reduce the mismatch between different recordings scenarios. Initially, a CNN is trained on weakly labeled Audioset data. Next, the pre-trained model is adopted as feature extractor for proposed CURE corpus. We also explore the performance of extreme learning machine (ELM) and use support vector machine (SVM) as baseline classifier. As a second evaluation set we incorporate ESC-50. Results and discussions validate the superiority of Ladder network over ELM and SVM classifier in terms of robustness and increased classification accuracy.
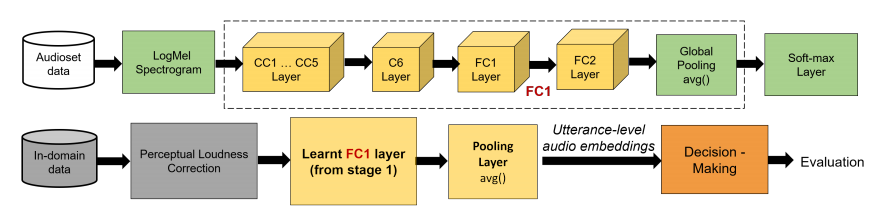
The deep CNN architecture in the vanilla transfer learning pipeline. Audio embeddings were extracted from layer FC1 of the network, trained on out-domain data. Layers CC1…CC5 are double convolutional layers and C6 is a single convolutional layer. FC1 layer includes batch normalization and ReLu activation while FC2 has sigmoid activation. The global pooling layer averages segment-level embeddings to utterance-level. The soft-max layer outputs a node per labeled class.

Illustration of a two-layer LadderNet, where x and x^ are input and reconstructed embeddings, y is the output label, and y~ the output of the noisy encoder, injected by Gaussian noise N (0, σ^2). Decoder paths are characterized by denoising functions g(.)and denoising costs Cd(.) at each layer.

Effect of feature-based normalization on weighted classification accuracy on ESC-50 and proposed SEDSET audio data. Notice the robustness of LadderNet and SVM models against feature normalization, while underlying that SVM performance varied highly during parameter optimization. In the left panel, ELM appears poor in learning the representation without proper normalization of the input data, while LadderNet is slightly affected by it potentially by mismatches between train and test data.