


Introduction
The computation of deep neural networks (DNNs) is usually abstracted as data flow graphs (DFGs) that consist of operators and the dependency between them. This representation naturally contains two levels of parallelism. The first level is the inter-operator parallelism, where operators that do not have dependencies in the DFG may run in parallel. The second level is the intra-operator parallelism, where an operator such as matrix multiplication has inherent internal data parallelism and can leverage hardware accelerators that are able to perform parallel computation, such as a GPU.
To exploit the two levels of parallelism, existing deep learning frameworks (TensorFlow, PyTorch, MXNet, etc.) adopt a two-layered scheduling approach. DFG layer schedulers take the data flow graph and emit operators that are ready to be executed based on the dependencies, which takes advantage of the inter-operator parallelism. In addition, there is another layer of schedulers that takes the responsibility to exploit the intra-operator parallelism and maps an operator to finer grained execution units in the accelerator. This intra-operator scheduler is often hidden behind opaque libraries, such as cuDNN, and is sometimes partially implemented in hardware, as is the case with GPUs.
While such a two-layer scheduling approach is widely adopted for its simplicity, the mutual unawareness of schedulers for inter- and intra-operator parallelism incurs fundamental performance limitations, including significant scheduling overhead in runtime, ineffective exploitation of inter-operator parallelism, and overlooked interactions between these two levels of parallelism.

Fig 1: An illustration of (a) the inefficient scheduling in existing approaches; and (b) an optimized scheduling plan.
To overcome these limitations, Microsoft Research Asia collaborated with Peking University and ShanghaiTech University to propose Rammer, a DNN compiler design that maximizes hardware utilization by holistically exploiting parallelism through inter- and intra-operator co-scheduling. On the workload side, Rammer converts every operator of the original DFG to an rOperator and further breaks it up into smaller schedule units called rTasks. On the computational resource side, the underlying device is abstracted into a vDevice that consists of a number of virtualized execution units (vEU). With the help of these proposed abstractions, Rammer can schedule finer grained rTasks onto several vEUs rather than dispatching an operator to the whole device, thereby opening up new optimization space. More importantly, the schedule plan is generated at compile time and is “statically” mapped onto the hardware during runtime, naturally eliminating most of the schedule overhead.
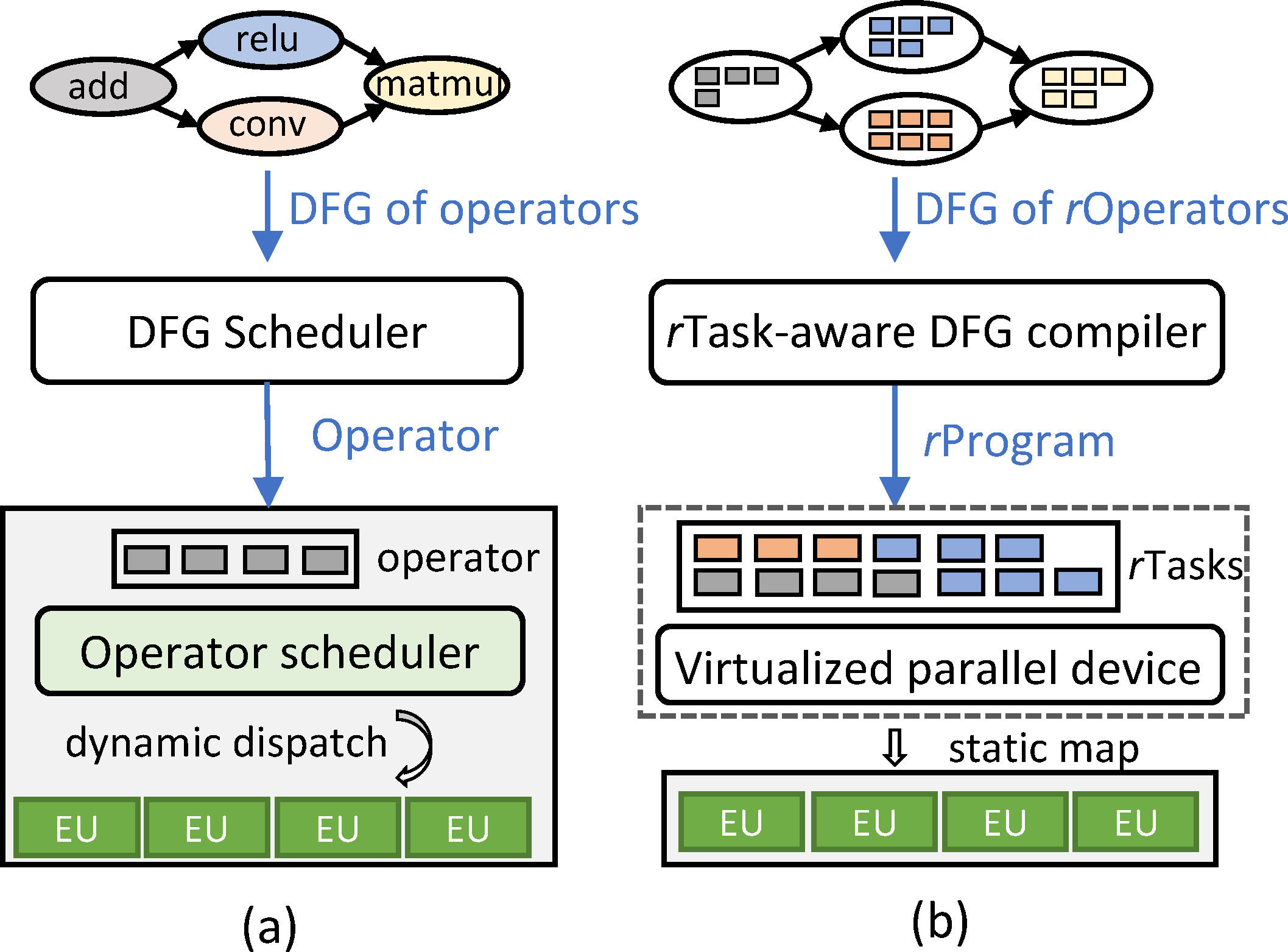
Fig 2: System overview of DNN computation in (a) existing DNN frameworks, and (b) RAMMER
Although several terminologies found above are borrowed from NVIDIA CUDA, it is easy to see from the descriptions so far that the designs of abstraction are hardware neutral. Rammer can be easily customized to mainstream accelerators such as different GPUs, IPUs, etc., and it has been evaluated on different backends including NVIDIA GPU, AMD GPU, and GraphCore IPU. Compared with TensorRT, a state-of-the-art vendor optimized proprietary DNN inference library from NVIDIA, Rammer can achieve an acceleration that is up to 3.1x faster for certain workloads.

Fig 3: End-to-end model inference time with a batch size of 1 on NVIDIA V100 GPU
The design and implementation of Rammer
Rammer was built atop NNFusion, a DNN compiler developed by our team at Microsoft Research Asia. NNFusion can compile a deep learning model into highly optimized source codes (CUDA, ROCm, etc) targeting different hardware devices. In addition, users can import external kernel implementation (e.g. generated by TVM [1]) based on their needs. By doing this, NNFusion reduces runtime overhead and removes library/framework dependencies.
Let us first look at what, exactly, rTasks are. They are independent building blocks of the rOperator and the minimal schedule units. Taking NVIDIA GPU as an example, for CUDA kernel implementation, each thread block can be converted into an rTask by a light parser. To enable compatibility with the codebase of NNFusion and the prevalent GPU programming model, Rammer adopted a source code transformation approach. In other words, every rTask can directly apply the original CUDA semantics, which couples the rTask with the programming model but also reduces the burden of implementation.
The next question is how to create vDevice and vEU. Currently, they can be created and configured based on the parameters of the hardware and a simple heuristic search. For example, NVIDIA V100 owns 80 SMs, and each SM can at most serve 32 thread blocks concurrently, so we can easily create and configure a vDevice consisting of 2560 vEU, which matches the physical device.
Now we have the DFG of rTasks and a resource pool filled with vEUs by applying certain naïve policies (such as Round Robin scheduling), which can help to generate an efficient execution plan. Because of the limitations of the hardware and programming model, the dispatcher and the scheduler within GPUs are not programmable to the developer. Rammer, therefore, leverages a technique called “persistent thread” [2] to bind vEUs and SMs and “statically” map the virtual device we have proposed to the physical hardware.
What critical piece of the puzzle does Rammer fill in?
A good piece of work in computer systems should not only help to optimize performance, but more importantly, clarify the problem itself.
Like many projects, the development of Rammer was driven by a specific problem, namely, how to improve the utilization of GPU for DNN inference. To meet the strict latency constraint, small batch sizes are often prevalent in inference engines, which usually puts GPUs in an extremely underutilized situation. Besides optimizing the implementation of operators, the most straightforward approach to address this issue is to concurrently execute multiple operators on the device, which happens to be a familiar problem in the computer architecture community. CUDA introduced the concept stream at a very early stage, and there are already a number of effective solutions (concurrent kernel execution [3],elastic kernel [4]) to this challenge. Why, then, did researchers ignore the same elephant in the room with DNN serving for such a long time?
As the dependency engine of MXNet mentioned above, TensorFlow also tested multi-stream support in its early stage, but it was soon deprecated for several reasons:
- The CUDA streams deploy a spatial multiplexing scheme to schedule operators from different stream queues during runtime, but the units to be scheduled are coarse grained and the intervention between operators could lead to severe performance degradation [5].
- The number of streaming processors in a GPU has been drastically increasing in recent years. Nowadays, Ampere GA100 is equipped with 128 SMs, but in comparison, Kepler GK180 GPU from just a few years back is equipped with only 15 SMs. Therefore, the preconception that inter-operator parallelism is not critical to performance has been formed in both GPU and DNN framework development communities.
- Classic neural network architectures like AlexNet are simple, which means the DFG itself will not expose much inter-operator parallelism. However, the structures of DNNs are becoming increasingly complex with the rise of AutoML and new design paradigms introduced by research works such as ResNeXt [6], ResNeSt [7].
Taking advantage of inter-operator parallelism is a decent performance optimization method to boost DNN inference, but it is far from being systematic. Rammer’s early prototype had already achieved significant acceleration, but we felt that we had not grasped the essence of the problem. Was the prototype merely serving as a generalized kernel fusion approach?
Re-clarifying a problem and repositioning our work is not reinventing the wheel, as many may believe. We tried to devise the rTask and vEU abstraction, and gradually, we realized what was behind the problem through rounds of discussions and debates: the performance gap between the compute capacity of hardware and the performance achieved in practices lay in the two-layer scheduling approach adopted by present DNN frameworks. Consequently, the new abstractions soon helped us to explore the larger optimization space:
- We changed directions from subgraph fusion into workload schedule and resource allocation. Owing to the predictability of the computation pattern (DFG, operators and tensors) of DNNs, the schedule overhead can be easily offloaded to the compiler, which improves the efficiency of searching as well as simplifies the system design.
- More importantly, the new abstractions revealed to us the interplay of inter- and intra-operator scheduling. Specifically, assume that there are two kernel implementations for one operator, and one of them consumes three times more resources (e.g., CUDA cores, Shared Memory, etc) than the other but can only achieve twice the speedup, which is quite common in parallel computing. If the whole device is occupied to run a single operator, faster implementation would be always preferred since resources are abundant. However, to improve the overall performance, we showed that the “most cost effective” implementation is usually better than the “fastest” implementation while co-scheduling inter- and intra-operator parallelism. The results challenged a basic assumption in prior works such as AutoTVM [8] on kernel optimization, which is that the performance of executing the kernel on a standalone device is the exact criterion to tune a kernel. Evidently, “optimal” graph level optimizations such as TASO [9] plus “optimal” high performance kernel implementation do not lead to a global optimal.
Based on the proposed abstraction, Rammer with its simple policies can outperform state-of-the-art methods. We envision that the proposed scheduling mechanism will enable future research on more advanced scheduling policies to further explore the optimization space. Future work in this area is highly welcome!
NNFusion has been open sourced on GitHub: https://github.com/microsoft/nnfusion. NNFusion is a flexible and efficient DNN compiler that can generate high-performance executables from a DNN model description. It facilitates full-stack model optimization with ahead-of-time and model-to-code compilation. Latest NNFusion 0.2 is now available: in this release, we added new features such as a kernel tuner, kernel database, and parallel training. A more friendly python interface was also introduced to be compatible with PyTorch.
For those interested, please do check out NNFusion. We look forward to receiving any valuable feedback and ideas you may have on how we can continue to squeeze more out of accelerator performance!
Reference
[1] TVM https://tvm.apache.org/
[2] Persistent Thread https://ieeexplore.ieee.org/document/6339596
[3] Concurrent Kernel Execution https://ieeexplore.ieee.org/document/5999803
[4] Elastic Kernel http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.649.8875&rep=rep1&type=pdf
[5] Dynamic Space-Time Scheduling for GPU Inference https://arxiv.org/pdf/1901.00041.pdf
[6] ResNeXt https://arxiv.org/abs/.054311611
[7] ResNeSt https://arxiv.org/abs/2004.08955
[8] AutoTVM https://arxiv.org/pdf/1805.08166.pdf
[9] TASO https://github.com/jiazhihao/TASO