For many people, opening door handles or moving a pen between their fingers is a movement that happens multiple times a day, often without much thought. For a robot, however, these movements aren’t always so easy.
In reinforcement learning, robots learn to perform tasks by exploring their environments, receiving signals along the way that indicate how good their behavior is compared to the desired outcome, or state. For the described movements, for example, we can specify a reward function that is +1 when the door is successfully opened or the pen is at the desired orientation and 0 otherwise. But this makes the learning task complicated for the robot since it has to try out various motions before stumbling on the successful outcome, or a reward of +1.
The imitation learning (IL) paradigm was introduced to mitigate the amount of trial and error. In IL, the robot is provided with demonstrations of a given task performed by an expert from which it can try to learn the task and possibly gain information about the expert’s reward function, or the expert’s intent, similar to how people pick up various skills. Yet, learning remains difficult in instances where we only have access to the change enacted by the expert in the world, known as the expert observation, and not the precise actions the expert took to achieve the change. Another difficulty the robot faces is that even if it sees infinite expert demonstrations, it can’t fully reason about the intent of the expert—that is, compare whether one of its own learned behaviors is closer to the expert’s than another behavior—as it only knows the best behavior and has no notion of ordering over other behaviors.
Microsoft research podcast

What’s Your Story: Lex Story
Model maker and fabricator Lex Story helps bring research to life through prototyping. He discusses his take on failure; the encouragement and advice that has supported his pursuit of art and science; and the sabbatical that might inspire his next career move.
In our paper “A Ranking Game for Imitation Learning (opens in new tab),” being presented at Transactions on Machine Learning Research 2023 (TMLR (opens in new tab)), we propose a simple and intuitive framework, \(\texttt{rank-game}\), that unifies learning from expert demonstrations and preferences by generalizing a key approach to imitation learning. Giving robots the ability to learn from preferences, obtained by having an expert rank which behavior aligns better with their objectives, allows the learning of more informative reward functions. Our approach, which enabled us to propose a new objective for training over behavior preferences, makes the learning process easier for a robot and achieves state-of-the-art results in imitation learning. It also enabled the training of a robot that can solve the tasks of opening a door and moving a pen between its fingers in simulation, a first in imitation learning with expert observations alone. The incorporation of preferences has also seen success in language modeling, where chatbots such as ChatGPT (opens in new tab) are improving themselves by learning a reward function inferred via preferences over several samples of model responses in addition to learning from desired human conversational data.
- Publication A Ranking Game for Imitation Learning
Robotics has found a place in controlled environments where the tasks at hand are well-defined and repeatable, such as on a factory floor. Our framework has the potential to help enable robot learning of tasks in more dynamic environments, such as helping people with daily chores around the home.
A ranking game for imitation learning
Inverse reinforcement learning (IRL) is a popular and effective method for imitation learning. IRL learns by inferring the reward function, also referred to as the intent of the expert, and a policy, which specifies what actions the agent—or, in our case, the robot—should take in a given state to successfully mimic the expert.
Notation: We use \(\pi\) and \(\pi^E\) to denote the policy of the agent and the expert, respectively, and \(R_{gt}\) to be the reward function of the expert, which is unknown to the agent/robot. \(\rho^\pi\) denotes the state-action/state visitation distribution of policy \(\pi\) in the environment—the probabilistic collection of states the policy visits in the environment. We use \(J(R;\pi)\) to denote the \(\textit{cumulative reward}\), or the performance of policy \(\pi\) under a reward function \(R\). We assume policy \(\pi\) belongs to function class \(\Pi\) and reward function R belongs to function class \(\mathcal{R}\).
The goal of imitation learning is to make the agent have the same performance as the expert under the expert’s unknown reward function \(R_{gt}\). The classical IRL formulation tackles this by minimizing the imitation gap under a reward function that makes the performance gap the largest. We denote this framework by \(\texttt{imit-game}\) and write it below formally:
\(\texttt{imit-game}(\pi,\pi^E): \text{argmin}_{\pi\in\Pi}\text{max}_{R\in\mathcal{R}} [\mathbb{E}_{\rho^E(s,a)}[R(s,a)]-\mathbb{E}_{\rho^\pi(s,a)}[R(s,a)]]\)
Simply stated, the \(\texttt{imit-game}\) tries to find a policy that has the lowest worst-case performance difference with the expert policy. This classical IRL formulation learns from expert demonstrations but provides no mechanism to incorporate learning from preferences. In our work, we ask, does IRL really need to consider the worst-case performance difference? We find that relaxing this requirement allows us to incorporate preferences.
Our proposed method treats imitation as a two-player ranking-based game between a policy and a reward. In this game, the reward agent learns to map more preferred behaviors to a higher total reward for each of the pairwise preferences, while the policy agent learns to maximize the performance on this reward function by interacting with the environment. Contrary to the classical IRL framework, the reward function now has to get only the rankings correct and not optimize for the worst case (see Figure 1).
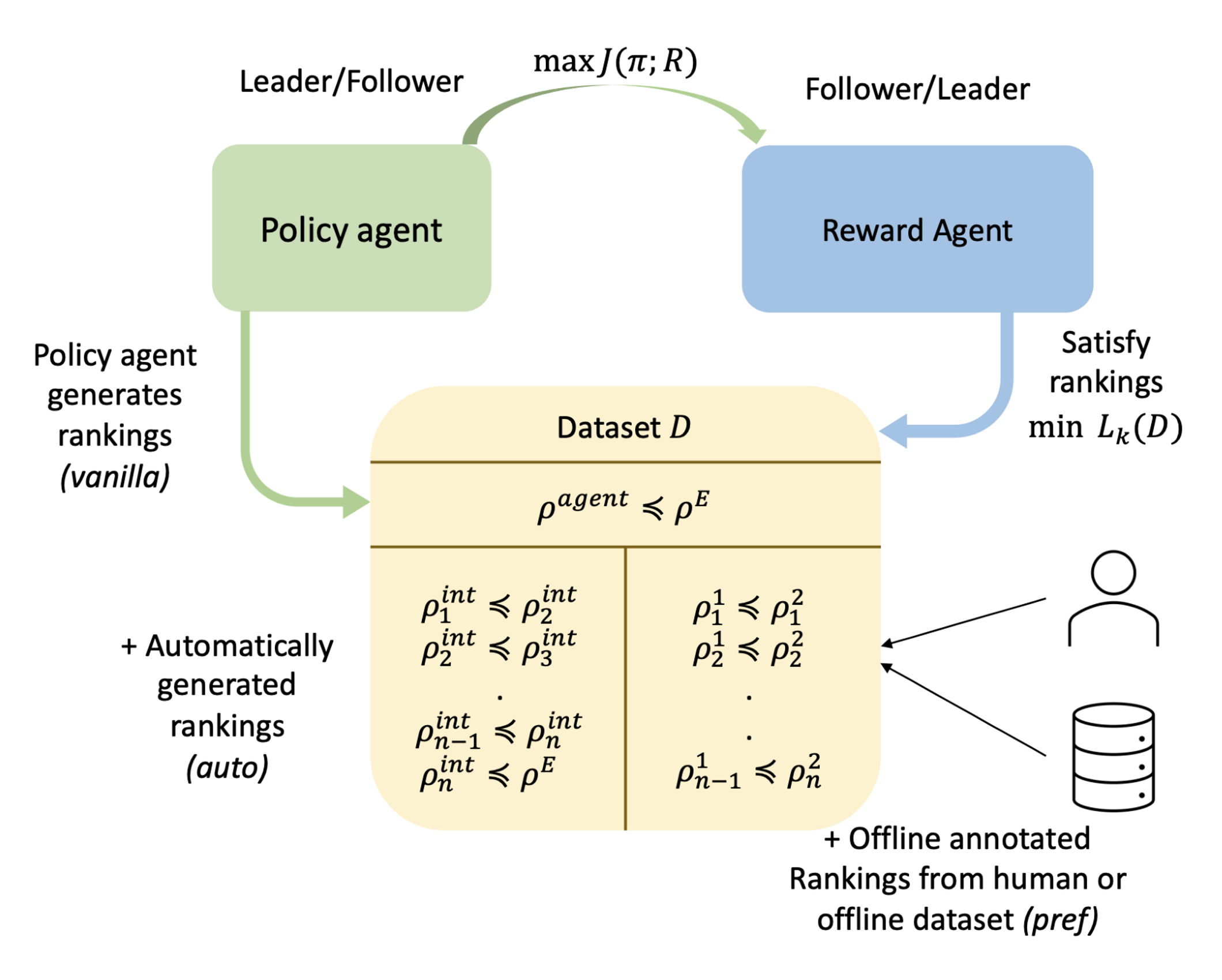
To incorporate preferences, we need to quantify the behaviors in order to compare them. In this work, we choose the behaviors (\(\rho\)) to be the state-action or state-only visitation distribution of the agent. A ranking between behaviors is used to specify that the expert would prefer one behavior over the other. A reward function that satisfies the behavior rankings ensures that the average return under a lower-ranked behavior is smaller than the higher-ranked behavior. More formally, the ranking game is defined as a game where the policy agent \(\pi\) maximizes the expected return \(J(R;\pi)\) of the policy under reward function \(R\) when deployed in the environment. The reward player takes the dataset of pairwise rankings \(D^p\) (rankings are denoted as \(\rho^i\preceq\rho^j\)) as an input and attempts to learn a reward function that satisfies those rankings using a ranking loss (denoted by \(L(D^p;R)\)).
\(\underbrace{\text{argmax}_{\pi\in\Pi}J(R;\pi)}_{\text{Policy Agent}}~~~~~~~~~~~~~~~\underbrace{\text{argmin}_{R\in\mathcal{R}}L(D^p;R)}_{\text{Reward Agent}}\)
The ranking loss induces a reward function \(R\) that attempts to satisfy each pairwise preference in the dataset as follows:
\(\mathbb{E}_{\rho^i}[R(s,a)]\le\mathbb{E}_{\rho^j}[R(s,a)]~~,~~\forall \rho^i\preceq\rho^j \in D^p\)
Generalizing prior imitation learning approaches with \(\texttt{rank-game}\)
The \(\texttt{rank-game}\) framework neatly encapsulates prior work in IRL and prior work in learning from preferences, respectively. First, let’s see how classical IRL is a part of this framework. Recall that the classical IRL/\(\texttt{imit-game}\) optimization can be written as:
\(\text{argmin}_{\pi\in\Pi}\text{max}_{R\in\mathcal{R}} [\mathbb{E}_{\rho^E(s,a)}[R(s,a)]-\mathbb{E}_{\rho^\pi(s,a)}[R(s,a)]]\)
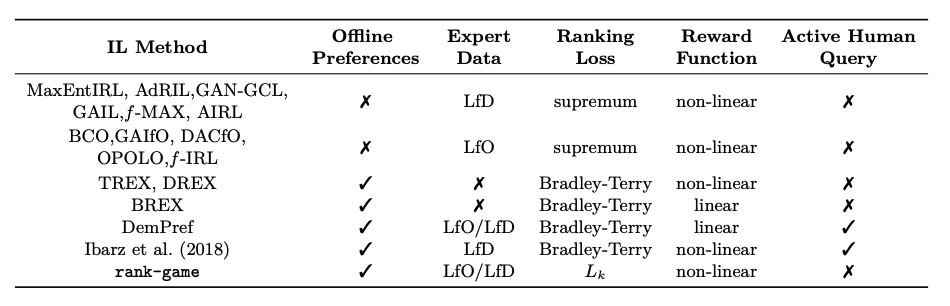
The inner optimization learns a reward function that ensures that the return gap under the reward function is maximized between the current policy’s behavior and the expert behavior. Thus, \(\texttt{imit-game}\) can be seen to be a special case of \(\texttt{rank-game}\) with: (1) a ranking dataset that prefers expert behavior more than the current agent behavior and (2) a form of ranking loss that maximizes the performance gap (termed as \(\textit{supremum loss}\)). A number of prior methods in the imitation learning domain can be understood as special cases of \(\texttt{rank-game}\) under various ranking losses, classes of reward functions, and abilities to incorporate preferences (see Figure 2).
Setting up the ranking game
To develop a framework that successfully combines learning from demonstrations and learning from preferences, we addressed several questions:
- What is the ranking loss function that allows for the reward to satisfy the preferences in the dataset?
- Where do we get the dataset of pairwise preferences?
- How can we effectively optimize this two-player game?
Step 1: A new ranking loss function for reward learning
Our proposed framework requires learning a reward function such that the rankings in the dataset are satisfied. While several loss functions exist in prior literature to enable this, such as Luce (opens in new tab) Shepard (opens in new tab), Lovász-Bregman (opens in new tab) divergences (opens in new tab), and the earlier discussed supremum loss, we introduce a new loss function:
\(L_k(\mathcal{D}^p;R) = \mathbb{E}_{(\rho^{\pi^i},\rho^{\pi^j})\sim \mathcal{D}^p} \Big[\mathbb{E}_{s,a\sim\rho^{\pi^i}}{[(R(s,a)-0)^2]} + \mathbb{E}_{s,a\sim\rho^{\pi^j}}{[(R(s,a)-k)^2]}\Big]\)
The loss function is simple and intuitive: For all the preference pairs in the dataset, the less preferred behavior is regressed to a return of 0 and more preferred behavior is regressed to a return of user-defined parameter \(k\). This loss function allows us to learn a reward function with user-defined scale \(k\), which plays an important role in enabling better policy optimization; it’s principled and facilitates near-optimal imitation learning; and by design, it allows us to incorporate preferences.
Step 2: Getting the ranking dataset
Besides giving more information about the expert’s intent and being easy to obtain, another benefit of preferences is that they can also help learn a more informative, or shaped, reward function. This form of reward shaping can provide better guidance for policy optimization, reducing the burden of exploring the environment to find the optimal policy and increasing sample efficiency for IRL. Our initial ranking dataset is generated by the policy agent from its interactions with the environment; we always prefer expert’s behavior to be better or equal to current policy’s behavior in the rankings. To further leverage the benefits of preferences, we consider two methods for augmenting this ranking dataset:
- Expert-annotated rankings: In situations where we have access to additional rankings, provided by humans or obtained from reward-annotated datasets, we can simply add them to our ranking dataset.
- Automatically generated rankings: It turns out we can improve learning efficiency for imitation by using the rankings already present in the dataset of pairwise preferences to generate more preferences in a procedure similar to Mixup regularization (opens in new tab) in trajectory space.
Step 3: Improving optimization stability with Stackelberg game
Prior work has found the Stackelberg game framework to be a strong candidate for optimizing two-player games in various applications. A Stackelberg game (opens in new tab) is a bi-level optimization problem:
\(\text{max}_x (f(x,y_x)),~~~~\text{s.t}~~y_x\in \text{min}_x(g(x,y))\)
In this optimization, we have two players—Leader \(x\) and Follower \(y\)—that are trying to maximize and minimize their own payoff \(f\) and \(g\), respectively. We cast \(\texttt{rank-game}\) as a Stackelberg game and propose two algorithms depending on which player is set to be the leader:
- Policy as Leader (PAL): \(\text{max}_\pi J(R,\pi)~~~~~\text{s.t}~~ R=\text{argmin}_R~L(D^p;R)\)
- Reward as Leader (RAL): \(\text{min}_R L(D^p;R)~~~\text{s.t}~~\pi = \text{argmax}_\pi~J(R;\pi)\)
Aside from improving training stability, both methods have complementary benefits in the non-stationary imitation learning setting. PAL can adjust more quickly when the intent of the expert changes, while RAL can handle environmental changes better.
How well does \(\texttt{rank-game}\) perform in practice?
In testing the capabilities of \(\texttt{rank-game}\), one of the scenarios we consider is the learning from observations alone (LfO) setting, in which only expert observations are provided with no expert actions. This more challenging setting better reflects the learning conditions robots will operate under if we want them to be more widely deployed in both controlled and dynamic environments. People can more naturally provide demonstrations by performing tasks themselves (observations only) versus performing the task indirectly by operating a robot (observations and precise actions). We investigate the LfO performance of \(\texttt{rank-game}\) on simulated locomotion tasks like hopping, walking, and running and benchmark it with respect to representative baselines. \(\texttt{Rank-game}\) approaches require fewer environment interactions to succeed and outperform recent methods in final performance and training stability.
Additionally, our experiments reveal that none of the prior LfO methods can solve complex manipulation tasks such as door opening with a parallel jaw gripper and pen manipulation with a dexterous hand. This failure is potentially a result of the exploration requirements of LfO, which are high because of the unavailability of expert actions coupled with the fact that in these tasks observing successes is rare.
In this setting, we show that using only a handful of expert-annotated preferences in the \(\texttt{rank-game}\) framework can allow us to solve these tasks. We cannot solve these tasks using only expert data—adding preferences is key.
Next steps
Equipping agents to learn from different sources of information present in the world is a promising direction toward more capable agents that can better assist people in the dynamic environments in which they live and work. The \(\texttt{rank-game}\) framework has the potential to be extended directly to the setting where humans present their preferences interactively as the robot is learning. There are some promising future directions and open questions for researchers interested in this work. First, preferences obtained in the real world are usually noisy, and one limitation of \(\texttt{rank-game}\) is that it does not suggest a way to handle noisy preferences. Second, \(\texttt{rank-game}\) proposes modifications to learn a reward function amenable to policy optimization, but these hyperparameters are set manually. Future work can explore methods to automate such learning of reward functions. Third, despite learning effective policies, we observed that \(\texttt{rank-game}\) did not learn reusable robust reward functions.
For additional details, including experiments in the learning from demonstration (LfD) setting, non-stationary imitation setting, and further framework analysis, check out the paper (opens in new tab), project page (opens in new tab), code (opens in new tab), and video presentation (opens in new tab).
Acknowledgments
This research was supported in part by the National Science Foundation, Air Force Office of Scientific Research, and Army Research Office.