

By Zewei Xu, Senior Applied Scientist and Will Dubyak, Principal Program Manager
In March we announced Dynamics 365 Copilot (opens in new tab) and the Copilot in Power Platform (opens in new tab) which has generated curiosity about how we’ve been able to bring more context and specificity to generative AI models.
This post explains how we use retrieval augmented generation (RAG) to ground responses and use other prompt engineering to properly set context in the input to large language models (LLMs), making the use of natural language generation (NLG) technology easier and faster for users. It is a look at two components of our efforts to deliver NLG: prompt engineering, and knowledge grounding.
In early use a key tension for engineering is becoming increasingly apparent.
Pretrained NLG models are powerful, but in the absence of contextual information responses are necessarily antiseptic and generic. Provision of access to customer data is an option, but the need for data security and privacy precludes many sharing options at scale.
Our challenge is to balance these competing forces: enable access to the power of these models for contextually relevant and personalized text generation, while at the same time providing every privacy and security protection our users expect.
Our approach uses two methods. The first involves additions to the user prompt to pass relevant information to the underlying NLG model. The second involves intervention in the data layer so that contextual information is available in a searchable format while remaining secure.
Note that through using Azure OpenAI to call their Generative Pre-trained Transformer (GPT), all standard Azure protections (Trust your cloud | Microsoft Azure) (opens in new tab) are assumed, and thus excluded from explicit discussion.
Prompt Engineering
The key idea behind prompt engineering is to provide enough information in the instructions to the AI model so that the user gets exactly the hoped for result.
The prompt is the primary mechanism for access to NLG capabilities. It is an enormously effective tool, but despite its flexibility there are expectations for how information is passed if user intent is to be actively converted to the expected output. It’s obvious that prompts must be accurate and precise: otherwise, the model is left guessing. But there are other dimensions to prompt engineering that enable the secure access we will require to generate useful insight.
We have 5 components in our prompt. Each of the five is a necessary part of the pipeline. Order matters, and ours are in the accepted method of ascending order of importance to accommodate recency bias.
A sample prompt is attached as an appendix.
- System Instructions: We assume a certain set of basic rules to govern generation of content in response to the prompt. This information is of several types. There is general info such as avoidance of subjective opinion or repetition, argument or excessive procedural insight with the user, and ending a chat thread that becomes controversial. There are also general rules to avoid being vague, wandering off topic, or providing images in the response.
- There is guidance about Grounding and RAI considerations which will be considered below.
- Historical Data: such as information from past conversations. Multiturn will alter this practice.
- Agent Context input (optional; in this context, “Agent” refers to a customer service agent. Note that this is an example; a very similar process occurs in functional areas outside customer service.)
- Assistant Message. This is a reference to a part of the conversation history to serve as an example of the type of response desired. It can be written by a developer.
| Case | GPT generated agent answer before prompt engineering | GPT generated agent answer after prompt engineering |
| Agent: Hello, how may I help you? Customer: Hi, I am having an issue. Customer: How to force delete VM in Azure? Agent: | Sure, I can help you with that. Please follow the below steps: 1. Open the Azure portal. 2. Select the virtual machine you want to delete. 3. Click on the “Delete” button. 4. Confirm the deletion by clicking on “Yes”. 5. Wait for the deletion process to complete. 6. Verify that the virtual machine has been deleted. | You can force delete a VM in Azure through the Azure Portal, CLI, PowerShell, and REST API. To force delete a VM in the Azure Portal, navigate to your virtual machine, select Delete on the Overview page, select the checkbox for Apply force delete in the Delete virtual machine pane, and select Ok. To delete a VM using the Azure CLI, use the –force-deletion parameter for az vm delete. To force delete a VM using PowerShell, use the -ForceDeletion parameter for Remove-AzVm. To force delete a VM using the Azure REST API, use the forceDeletion parameter for Virtual Machines – Delete. |
Grounding
NLG models generate contextually relevant responses by accessing customer’s specific data. Doing this comes down to answering one question: “How do we extract the right information from a customer’s specific data?” We call this technique “grounding”, and it refers to the ability of a model to generate correct answers to questions from customer data.
Grounding depends on the idea of Retrieval Augmented Generation or RAG. RAG is a form of knowledge grounding; it is important because models must extract insight from different customers, and different kinds of data, almost always in great quantities. Formulating good answers requires a mechanism to make sense of the data. In Customer Service, for example, our solution is to decompose data into “chunks”, which are arranged by ranker models by relevance to different customer issues. When a customer sends a query, this query would be used to call for grounding. The ranker model is then used to extract the most relevant chunks from user data sources (e.g., we might pick a few of the most relevant). Combined with historical data and agent input (optional), extracted KB chunks are integrated into prompt LLM template to generate the answer. Similar practices are followed in other areas.
Knowledge Base chunking is a process of creating smaller units of document corpus based on paragraph separations. For our pipeline, we chunked KB articles based on the unit of paragraphs with a maximum and minimum limitation. We use Byte-pair encoding (https://huggingface.co/learn/nlp-course/chapter6/5?fw=pt (opens in new tab)) , which is the default tokenizer for GPT series. After chunking, document embeddings are generated. During runtime, the customer query is used to generate a query embedding, and cosine similarity score is calculated between query embedding and document chunk embedding. Then, the top matched document chunks are used as inputs to the prompt template for GPT to generate answer. We use all-mpnet-base-v2 (opens in new tab) as our embedding model because of its superior performance compared to other sentence embedding models (opens in new tab). Customer knowledge bases can be frequently changed, updated, or expanded with new information or KBs. Updating and storing static embedding files dynamically is also not ideal; these operations can be expensive and hard to maintain at scale. In our pipeline, we adopted Azure Cognitive Search (opens in new tab) (ACS), which provides us the scalable option for this indexing service. We have created an indexer based on ACS. In ACS, there are two levels of search. L1 of keyword-based searching (BM25) and L2 of semantic search (Semantic search – Azure Cognitive Search Microsoft Learn (opens in new tab)) (opens in new tab). We utilize L1 search for document chunks retrieval and are working on enabling semantic search for future pipeline updates. Another thread we are exploring is vector search, which is currently under private preview (Build next-generation, AI-powered applications on Microsoft Azure | Azure Blog | Microsoft Azure) (opens in new tab). It provides both the efficiency and scalability for document retrieval compared to other vector store solutions since it is constructed based on an optimized vector database.
After document chunks retrieval, we integrate top ranked chunks into our GPT prompt template for answer generation.
As shown in Figure 1, we first preprocess customer data with different formats into structured texts and save them as Dataverse entities. These entities are sent to the document featurization pipeline for chunking, text feature extraction, and embedding creation (vector search feature). Then the extracted features are uploaded to ACS storage to create an indexer.
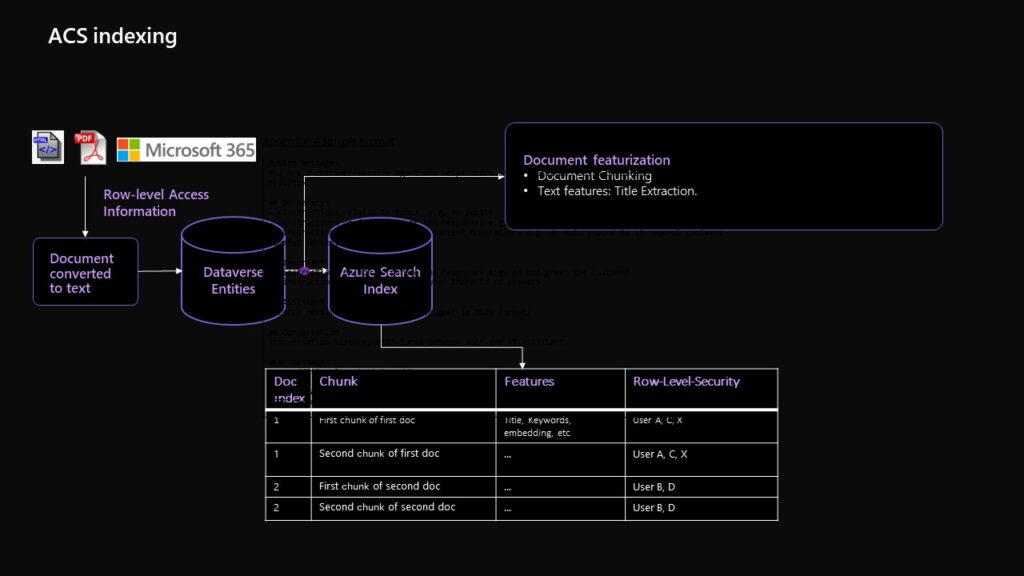
Figure 1: Indexing in Dataverse Copilot Pipeline
During real time service (Figure 2), the customer query is generated based on historical conversation using Cognitive Service’s summarization function (here: Summarize text with the extractive summarization API – Azure Cognitive Services | Microsoft Learn (opens in new tab)). It is then sent to ACS indexer to retrieve the most relevant KB chunks. After integrating the top relevant KB chunks, historic conversation data, and agent context input (optional) with our prompt template, we use GPT to generate answers for agents during conversations.
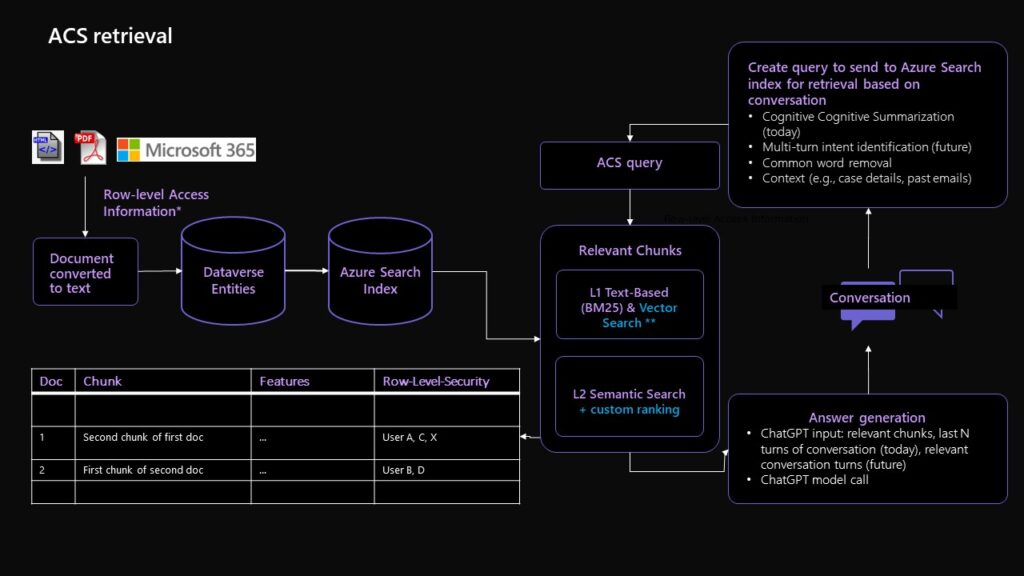
Figure 2: Real-Time answer generation
RAI: Prompt screening and Provenance check:
Our team is firmly committed to delivering services that comply fully with Microsoft Responsible AI (RAI) principles. These are described (here: https://www.microsoft.com/en-us/ai/responsible-ai). They manifest in two distinct ways.
The first is at the point of prompt. For extra protection (i.e., beyond Cog Services Content Moderation), each prompt is screened for anything that might return an NLG response considered prohibited content. Original GPT answers might contain offensive, inappropriate, and sometimes hallucinated contents that would reduce the quality of generated answers. We developed an RAI component that has been adopted across multiple BAP copilot features. Our approach is that a question that does not get asked (i.e., is not submitted to the model) cannot produce offensive or harmful answers. Therefore, each prompt is screened before execution. A prompt that fails screening is not executed, and the user receives a polite notification that they have asked a question that cannot be answered within the limits of our search policies.
In the provenance check component, we do entity checks including numeric, URL, date, and phone number checks. Moreover, we score for answer relevance to filter out irrelevant answers with a threshold.
On–going work:
In the current pipeline, we are requiring users to provide file formats in metadata as we need this info to properly parse the doc. This limits the number of file formats supportable by the pipeline. We plan a method for automatic file format detection and potentially expand file formats we currently support.
We are also working on improving the provenance check component by experimenting with Name Entity Recognition models (NER). We will enhance the RAI component by using out-of-box or fine-tuning customized NER models for extracting more entities like name, address, product related info for provenance checks.
A final thought
There is clearly an element of artistry to construction of a good prompt. The good news is that the required skills are not overwhelmingly difficult to acquire. We advise users to follow a mental framework of Ideate/Experiment/Fine Tune; prompts generation can be learned by doing. Approaching it with much the same mindset as we do multiturn prompts is a path to success with an NLG model.
| Appendix: A Sample Prompt System message: You are a customer service agent who helps users answer questions based on documents from ## On Safety: – – – ## Important – – AI Assistant message: ## Conversation User message: AI Assistant message: |