

Transformer stands out as the best graph learner: Researchers from Microsoft Research Asia wins the KDD Cup’s 2021 Graph Prediction Track
Transformer is well acknowledged to be the most powerful neural network in modelling sequential data, such as in natural language and speech. Model variants built upon Transformer have also shown great performance in computer vision and programming language. However, Transformer still is not the de-facto standard on public graph representation leaderboards. There have been many attempts to bring Transformer into the graph domain, but the only effective way to achieve this is by replacing certain key modules (e.g., feature aggregation) in classic GNN variants using the Softmax attention. Therefore, it is still an open question whether Transformer architecture is suitable for model graphs and how to make it work in graph representation learning.
Recently, researchers from Microsoft Research Asia are giving an affirmative answer to this question by developing Graphormer, which is directly built upon the standard Transformer and achieves state-of-the-art performance on a wide range of graph-level prediction tasks, including tasks from the KDD Cup 2021 OGB-LSC graph-level prediction track (Competition results of the KDD Cup 2021 OGB-LSC: https://ogb.stanford.edu/kddcup2021/results/ (opens in new tab)) and several popular leaderboards (e.g., OGB, Benchmarking-GNN).
Transformer was originally designed for sequence modeling. To utilize its power in graphs, we believe the key is to properly incorporate structural information of graphs into the model. Note that for each node i, the self-attention only calculates the semantic similarity between i and other nodes without considering the structural information of a graph reflected on the nodes and the relation between node pairs. Graphormer incorporates several effective structural encoding methods to leverage such information, which are described below.
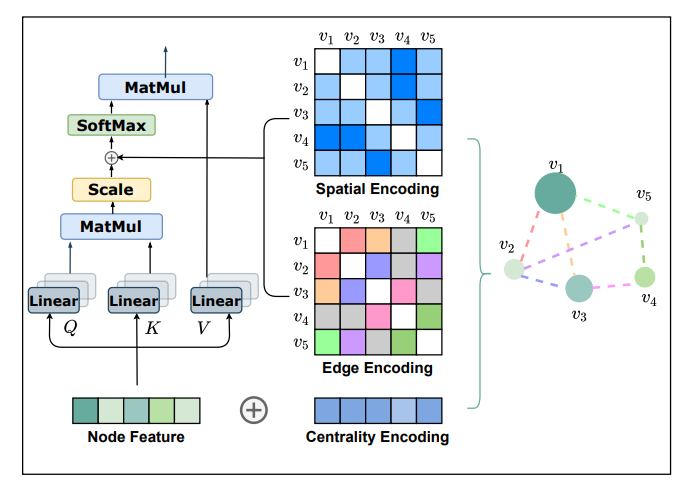
First, we propose a Centrality Encoding in Graphormer to capture the node importance in the graph. In a graph, different nodes may have different importance, e.g., celebrities are considered to be more influential than the majority of web users in a social network. However, such information isn’t reflected in the self-attention module, as it calculates the similarities mainly using the node semantic features. To address this problem, we propose encoding the node centrality in Graphormer. In particular, we leverage the degree centrality for the centrality encoding, where a learnable vector is assigned to each node according to its degree and added to the node features in the input layer. Empirical studies have shown that simple centrality encoding is effective for Transformer in modeling graph data.
Second, we propose a novel Spatial Encoding in Graphormer to capture the structural relationship between nodes. One notable geometrical property that distinguishes graph-structured data from other structured data, e.g., language or images, is that there does not exist a canonical grid to embed the graph. In fact, nodes can only lie in a non-Euclidean space and are linked by edges. To model such structural information, for each node pair, we assign a learnable embedding based on their spatial relation. Multiple measurements in the literature can be leveraged for modeling spatial relations. For a general purpose, we use the distance of the shortest path between any two nodes as a demonstration, which would be encoded as a bias term in the softmax attention and help the model accurately capture the spatial dependency in a graph. In addition, sometimes there is additional spatial information contained in edge features, such as the type of bond between two atoms in a molecular graph. We designed a new edge encoding method to further take such signals into the Transformer layers. To be concrete, for each node pair, we compute an average of dot-products of the edge features and learnable embeddings along the shortest path, then use it in the attention module. Equipped with these encodings, Graphormer can better model the relationship for node pairs and represent the graph.
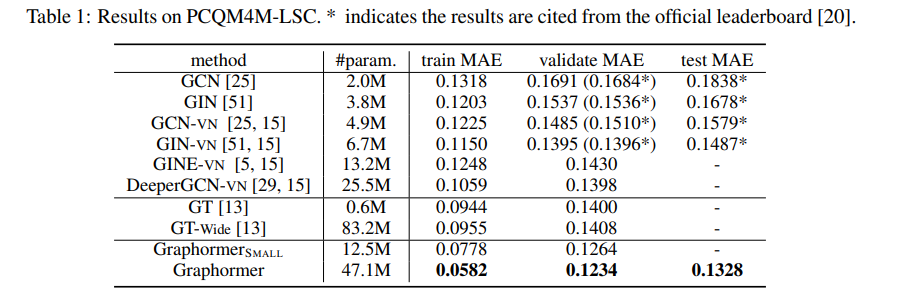
By using the proposed encodings above, we can further mathematically show that Graphormer has strong expressiveness, as many popular GNN variants are just its special cases. The great capacity of the model leads to state-of-the-art performance on a wide range of tasks in practice. On the large-scale quantum chemistry regression dataset in the very recent Open Graph Benchmark Large-Scale Challenge (OGB-LSC), Graphormer outperformed most mainstream GNN variants by more than 10% points in terms of relative error. On other popular leaderboards of graph representation learning (e.g., MolHIV, MolPCBA, ZINC), Graphormer has also surpassed previous best results, demonstrating the potential and adaptability of the Transformer architecture.
Graphormer is now open soured through GitHub: https://github.com/microsoft/Graphormer (opens in new tab)
View competition results of the KDD Cup 2021 OGB-LSC: https://ogb.stanford.edu/kddcup2021/results/ (opens in new tab)