(opens in new tab)
Microsoft researchers are developing a transfer learning–based approach for adapting general question answer models to documents in specialized domains. Their new demonstration system (above) can answer questions against Welcome to Canada, the Canadian government’s guidebook for new immigrants.With the advent of AI assistants, initially developed for structured databases and manually curated knowledge graphs, answers to the types of basic fact-based questions people encounter during the course of regular conversation became keystrokes or a verbal cue away. What film won the Academy Award for best picture in 1998? (Titanic.) What’s the weather going to be like today? (Likely around 80° and sunny if you’re on the Microsoft campus in Redmond, Washington.) What was the score of Monday’s Seattle Mariners game? (They won, 7-3.)
As machine reading comprehension (MRC) technology emerged, these question answer (QA) systems became capable of finding answers directly from passages of text without the need for curated databases and graphs, unlocking the potential of these systems to leverage the vast collection of material online, including digital books and Wikipedia articles. In fact, MRC technology is now being used in Bing (opens in new tab) to provide direct answers to some similar style queries by finding the answer in the text of the web pages retrieved. Microsoft is looking to extend that power to another class of questions: domain- and enterprise-specific queries.
Microsoft Research Podcast

Collaborators: Renewable energy storage with Bichlien Nguyen and David Kwabi
Dr. Bichlien Nguyen and Dr. David Kwabi explore their work in flow batteries and how machine learning can help more effectively search the vast organic chemistry space to identify compounds with properties just right for storing waterpower and other renewables.
We’re developing a transfer learning–based approach for quickly adapting models that have proven good at answering general interest–type questions to documents in specialized domains using only limited amounts of domain-specific example data. Our goal is to provide a platform for easily searching such documents as instruction manuals, employee handbooks, and organization guidelines. Current answer-seeking tools like tables of contents, document indices, and keyword search mechanisms can be tedious. A system that can take people directly to the exact answer they’re looking for would save them time and effort. To illustrate our approach, we’re releasing a new demonstration system that can answer questions against Welcome to Canada (opens in new tab), the Canadian government’s guidebook for new immigrants.

(opens in new tab)
Microsoft has been a leader in advancing machine reading comprehension and uses the technology in such products as Bing. Above is an example MRC answer provided for a submitted query as extracted from a Wikipedia page retrieved by Bing.‘What is?’ versus ‘What should?’
Thanks to such open datasets as the Stanford Question Answering Dataset (SQuAD) (opens in new tab), NewsQA (opens in new tab), and Microsoft Machine Reading Comprehension (MS MARCO) (opens in new tab), existing deep learning MRC algorithms have had success answering general-knowledge questions. In January 2018, for example, the R-NET system (opens in new tab) from Microsoft became the first to achieve parity with human performance on the SQuAD task (opens in new tab). When applied to domain-specific documents, though, these algorithms don’t perform as well because of fundamental differences between the general question-and-answer data they’re trained on and the types of questions asked of domain-specific data.
To explore this problem, we collected approximately 100,000 question-and-answer pairs against five different automobile manuals. When training a BERT-based QA model on a training set of 94,000 question-and-answer pairs in the auto domain, our system achieves an MRC F1 score of 0.83 on test queries for an auto manual, where the F1 score is a measure of the average overlap between the proposed answers and the reference answers and where higher scores are reflective of more accurate answers. However, when we attempt to answer auto manual questions using a model trained from 400,000 general-purpose question-and-answer pairs from the SQuAD, NewsQA, and MS MARCO datasets, an F1 score of only 0.65 is achieved.

(opens in new tab)
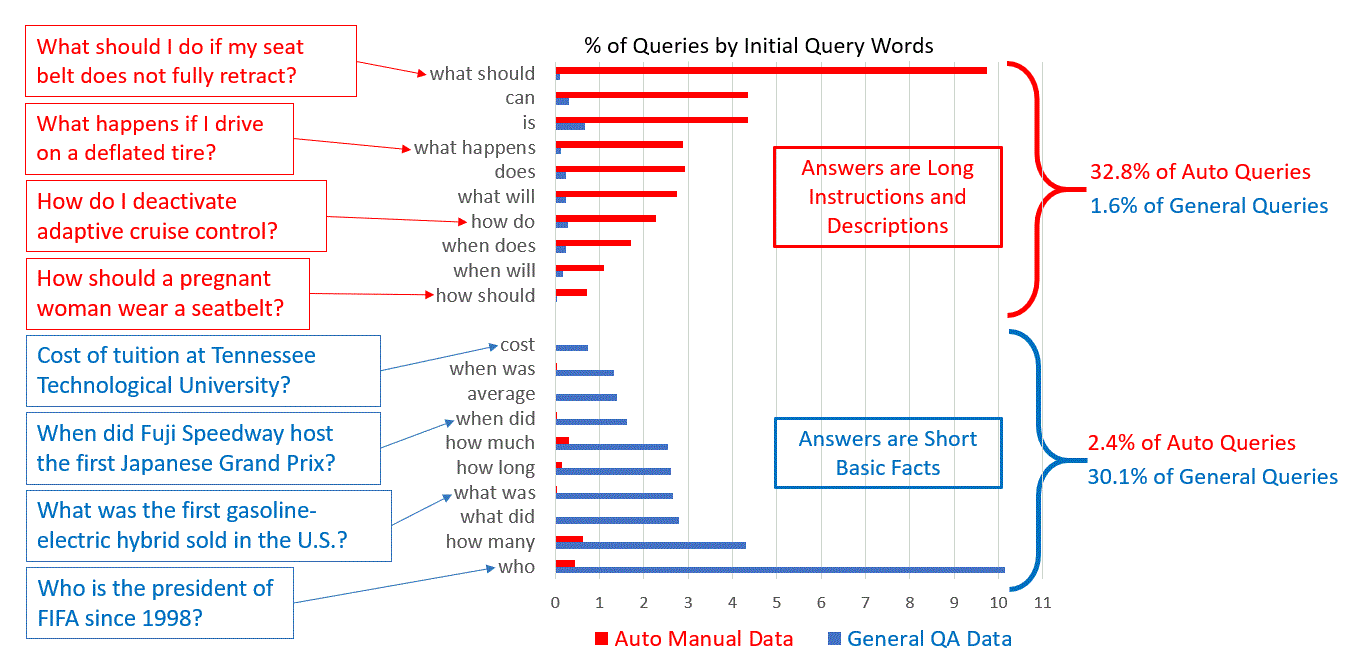
Answer seeking in more domain-specific fields can involve more nuanced questions and responses like the example question above, which is from the auto domain. With small amounts of training data, existing machine reading comprehension models can be adapted to handle such queries.Review of the kinds of questions present in each dataset reveals prominent differences in their scope. Ten common question types cover more than 30 percent of the questions in the general data. These are basic fact-based questions starting with words like who, when, or what that generate answers that are generally short in length, such as names, dates, and numbers. This style of questioning occurs much less frequently—less than 3 percent—in our auto manual dataset. Instead, questions in the auto domain tend to start with words like what should, how do, or what happens. Questions like these, which comprise longer answers such as technical descriptions or instructions, represent more than 30 percent of the auto manual queries but less than 2 percent of the general data queries.
(opens in new tab)
The types of questions in the general-purpose QA datasets and auto manual datasets used in this work are fundamentally different; the former are simpler. In the above graph, the blue bars represent the frequency of query types occurring in the general-purpose QA datasets; the red represent queries for the auto manual datasets. Example queries for some of the query types are shown on the left-hand side of the figure.While existing QA algorithms are more than capable of learning to answer questions in new domains, we recognize that collecting tens of thousands of example question-and-answer pairs to train a model for a new domain requires resources that customers might not be willing or able to expend, so we turned to transfer learning to adapt existing QA models using only small amounts of training data.
Maximizing small datasets
Transfer learning uses standard back-propagation training for a small number of epochs on the adaptation data. In the transfer learning process used in our system, five-fold cross-validation trials on the adaptation data are performed to estimate the optimal number of training epochs to maximize the performance of the model on the new domain without overfitting to the small example set. This process also inhibits the model from forgetting generalizations previously learned on the general QA data.
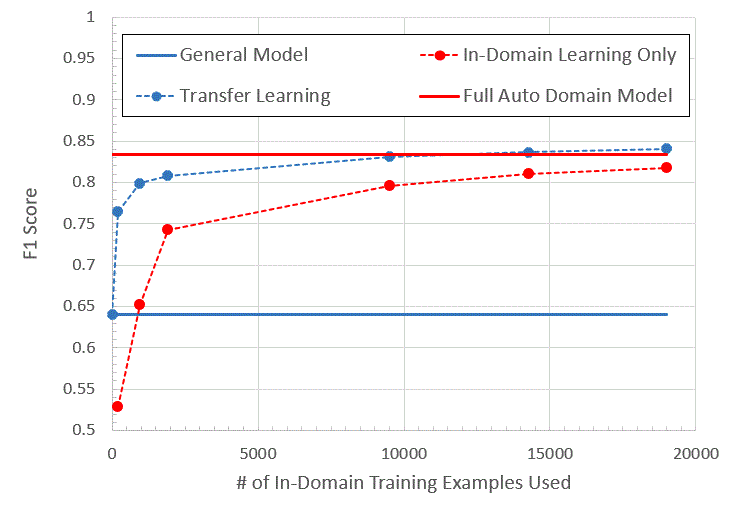
Our experiments have demonstrated a general QA model can be adapted and achieve substantial improvements in performance with limited amounts of domain-specific training data. The below figure shows results using a BERT-based QA modeling approach applied to an automobile manual. The solid blue line shows an F1 score of 0.64 for the general QA model, trained on a fixed amount of data, on our auto manual test set. The dotted blue line shows the F1 performance of adapting this general QA model using adaption data ranging from 190 examples to 19,000 examples. The red dotted line shows the model performance when training the model using varying amounts of only the training data collected for the manual. Finally, the solid red line shows an F1 performance of 0.83 when training the model using the full set of 94,000 auto domain question-and-answer pairs only.
F1 performance improves from 0.64 to more than 0.76 when adapting the general model with only 190 training examples. With just fewer than 1,000 examples in the new domain, an F1 score of 0.80 is achieved. By comparison, a model trained using only auto manual data needs more than 10 times more data to achieve the same 0.80 F1 score. Even in conditions when a lot of in-domain data is available, transfer learning from a general model provides clear benefits.
(opens in new tab)
The above figure captures question-answering performance on an auto manual under varying training conditions. Transfer learning from a general MRC model (dotted blue line) achieves substantial improvements in performance with limited amounts of domain-specific training data, even outperforming a model trained on only the full set of 94,000 auto domain question-and-answer pairs (solid red line).For those attending the 2019 Annual Meeting of the Association for Computational Linguistics (opens in new tab), we’ll be giving demonstrations of the Welcome to Canada system (opens in new tab), for which we collected only 953 question-and-answer pairs for adapting a general QA model, at the Microsoft booth throughout the conference. We look forward to seeing you there and discussing our work with you in more detail.