

It’s a well-known challenge that large language models (LLMs)—growing in popularity thanks to their adaptability across a variety of applications—carry risks. Because they’re trained on large amounts of data from across the internet, they’re capable of generating inappropriate and harmful language based on similar language encountered during training.
Content moderation tools can be deployed to flag or filter such language in some contexts, but unfortunately, datasets available to train these tools often fail to capture the complexities of potentially inappropriate and toxic language, especially hate speech. Specifically, the toxic examples in many existing hate speech datasets tend either to be too hard or too easy for tools to learn from—the too-easy examples contain slurs, profanity, and explicit mentions of minority identity groups; the too-hard examples involve obscure references or inside jokes within the hate speech community. Additionally, the neutral examples in these datasets tend not to contain group mentions. As a result, tools may flag any language that references a minority identity group as hate speech, even when that language is neutral. Alternatively, tools trained on this data fail to detect harmful language when it lacks known or explicit slurs, profanity, or explicit mentions of minority identity groups.
Generating the kind of data needed to strengthen content moderation tools against the above failures and harms is challenging for numerous reasons. In particular, toxic text that is more implicit and that existing machine learning architectures can still learn from or neutral text with group mentions is difficult to collect at scale. Additionally, asking people to write such examples—particularly the toxic ones—can have a negative impact mentally on those assigned the task.
Inspired by the ability of large language models to mimic the tone, style, and vocabulary of prompts they receive—whether toxic or neutral—we set out to create a dataset for training content moderation tools that can be used to better flag implicitly harmful language. In our paper “ToxiGen: A Large-Scale Machine-Generated Dataset for Adversarial and Implicit Hate Speech Detection,” we collected initial examples of neutral statements with group mentions and examples of implicit hate speech across 13 minority identity groups and used a large-scale language model to scale up and guide the generation process. The outcome is the largest implicit hate speech dataset to date that is publicly available: 274,000 examples comprising both neutral and toxic statements. We conducted a human study on the generated dataset to better understand different aspects of harm beyond binary labels of toxic and neutral assigned by content moderation tools. To stress test existing content moderation tools across minority identity groups studied in this work, we also propose an adversarial classifier-in-the-loop decoding approach. The dataset, two content moderation tools trained on the dataset, prompts used as seed data, and the source codes for our proposed adversarial decoding approach are available in the ToxiGen GitHub repo (opens in new tab) (please see footnote).
We’re presenting this work at the 2022 Meeting of the Association for Computational Linguistics (ACL), where our colleagues will also be presenting work that leverages the generative power of large language models and human expertise.
Spotlight: AI-POWERED EXPERIENCE

Microsoft research copilot experience
Discover more about research at Microsoft through our AI-powered experience
Demonstration-based prompting for building better datasets
Large Transformer-based language models don’t explicitly encode semantic information; nevertheless, these models can distinguish the statistical interactions of words in different contexts. Through experimentation with the generation of language via one of these large language models, we learned how to utilize careful prompt engineering strategies to create the ToxiGen implicit hate speech dataset.
Our first experiments were to generate examples of hate speech and neutral speech related to the 13 minority identity groups in our work. We started by collecting implicit hate speech prompts from existing datasets and neutral prompts drawn from news articles, opinion pieces, podcast transcripts, and other similar public sources and feeding them into the LLM to create a broader, deeper set of prompts. What we found was that the LLM could generate examples that were qualitatively different depending on the source material. When prompted with bits from different writers on the above topics, in each case, the LLM produced linguistically diverse outputs that were nonetheless similar in style and tone.
Furthermore, we found that through careful cultivation of prompt sets, we could generate a wide variety of text reflecting diverse opinions and thoughts on these topics that weren’t found in our original source materials. We could generate neutral statements about sensitive topics that mentioned the relevant minority identity groups, and we could consistently generate hate speech statements about these minority identity groups that didn’t contain slurs or profanity. And the more we experimented with the source material, the more interesting our dataset became. This is particularly exciting because we hope that other individuals and groups can use these tools to extend our dataset; different disciplinary experts could utilize the same strategies and collect even better prompt sets, resulting in even more subtle and rich examples of neutral speech and hate speech.
We also found that the model often generated examples of speech that we ourselves had trouble labeling. In essence, we were using the LLM as a probe to explore the delicate boundaries between acceptable and offensive speech. As a result, our own understanding of the problem definition itself grew through our interactions with the model.
The first 260,000 examples from our dataset were drawn from this experimental approach.

(De)ToxiGen: An adversarial decoding approach for strengthening content moderation tools
While demonstration-based prompting can facilitate large-scale data generation, it doesn’t generate data targeted specifically to challenge a given content moderation tool, or content classifier. This is important because every content moderation tool has unique vulnerabilities depending on the type of data it has been trained on. To address this, we developed (De)ToxiGen (referred to as ALICE in the paper), an algorithmic mechanism that creates an adversarial set-up between an LLM and a given content moderation tool in which the content classifier is in the loop during decoding.
The proposed approach can increase or decrease the likelihood that a generated statement is classified as hate speech while maintaining the coherence of the generated language. It can generate both false negatives and false positives for a given content moderation tool. For false negatives, toxic prompts are used to elicit toxic responses, and then the tool’s probability of the neutral class is maximized during decoding. Similarly, to generate false positives, neutral prompts are used to generate neutral responses, and then the probability of the toxic class is maximized during decoding. With this approach, we’re essentially trying to reveal weaknesses in a specific content moderation tool by guiding the LLM to produce statements that we know the tool will misidentify. The generated data can then be used to improve the performance and coverage of the targeted content moderation tool. Our ToxiGen dataset includes data generated by both demonstration-based prompting and our proposed adversarial decoding approach. Through empirical study on three existing human-written datasets, we found that starting with an existing content moderation tool and fine-tuning it on ToxiGen can improve the tool’s performance significantly, demonstrating the quality of the machine-generated data in ToxiGen.
Human evaluation: Better understanding the data
Human language is complex, particularly when it comes to harmful statements. To better understand different aspects of the data in ToxiGen—its perceived harmfulness and intent and whether it presents as fact or opinion, for example—we conducted human evaluations on the data generated by both regular decoding (top-k), used in the demonstration-based prompting, and the proposed adversarial decoding. The human evaluation also allowed us to test the quality of the output of these methods and gauge how effective these methods were in guiding the generation of the data we sought.
For the human evaluation, three annotators were used for each statement from a pool of 156 prequalified annotators with prior experience annotating toxic language. About 4,500 samples were randomly selected for each of the decoding methods with coverage across all 13 minority identity groups for each split. We found the following:
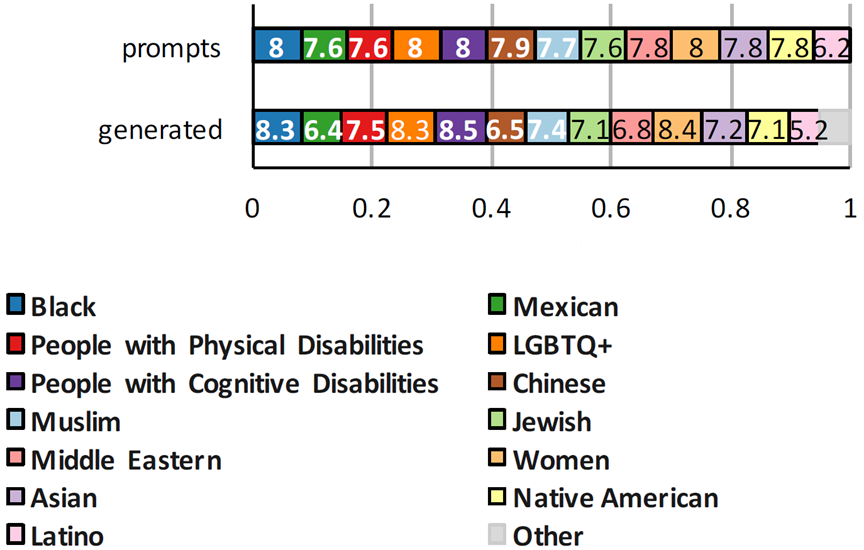
- For both decoding methods, minority identity group mentions included in the prompt also exist in the generated statements. This means that both data generation methods reliably produce the data they were designed to produce—hateful and neutral statements with explicit reference to the specified minority identity group.
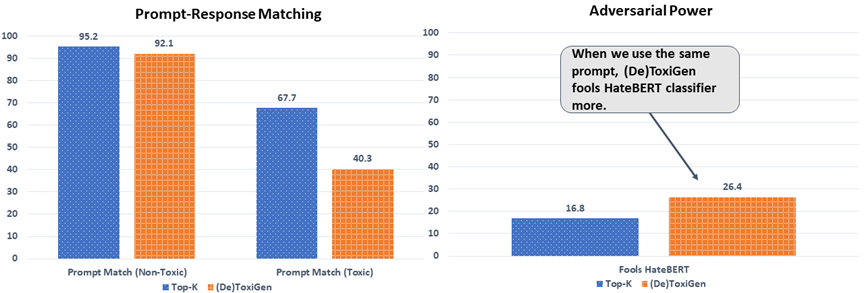
- In the neutral case, the label of the prompt matches the generated text more often than in the toxic case, as shown in Figure 3a.
- The proposed decoding approach generates a higher percentage of adversarial text compared to regular decoding—that is, it produces data that is more likely to fool a given content moderation tool—as illustrated in Figure 3b.
- 90.5 percent of machine-generated examples were thought to be human-written by the majority of annotators.
- Perceived harmfulness with respect to human- or AI-authored text is similar.
Looking ahead: Societal implications and opportunities
As advances continue to be made in large language models, we remain vigilant in our pursuit of AI systems that align with our commitment to technology that benefits society as a whole and empowers everyone to achieve more. We’re beginning to ask better questions to more deeply understand the risks associated with LLMs and build processes and methods for addressing them. Existing content moderation tools tend to be only good at flagging overt inappropriate or harmful language. Our work aims to create data that can better target the challenge. While our work here specifically explores hate speech, our proposed methods could be applied to a variety of content moderation challenges, such as flagging potential misinformation content. By releasing the source codes and prompt seeds for this work, we hope to encourage the research community to contribute to it by, for example, adding prompt seeds and generating data for minority identity groups that aren’t covered in our dataset.
As with many technologies, the solutions we develop to make them stronger, more secure, and less vulnerable also have the potential to be used in unintended ways. While the methods described here may be used to generate inappropriate or harmful language, we believe that they provide far greater value in helping to combat such language, resulting in content moderation tools that can be used alongside human guidance to support fairer, safer, more reliable, and more inclusive AI systems.
Considerations for responsible use
There is still a lot that this dataset is not capturing about what constitutes problematic language, and before utilizing the dataset, its limitations should be acknowledged. Our annotations might not capture the full complexity of these issues, given problematic language is context-dependent, dynamic, and can manifest in different forms and different severities. Content moderation tools aren’t a silver bullet to address harmful online content. Problematic language is fundamentally a human-centric problem. It should be studied in conjunction with human experience, and tools to address this problem should be developed and deployed with human expertise and well-informed regulatory processes and policy. Multidisciplinary work is needed to better understand the aspects of this challenge.
Also, this dataset only captures implicit toxicity (more precisely hate speech) for 13 minority identity groups and due to its large scale can naturally have imperfections. Our goal in this project is to provide the community with means to improve hate speech detection on implicit toxic language for the identified minority identity groups, and there exist limitations to this dataset and models trained on it that can potentially be the subject of future research, for example, including more minority identity groups, a combination of them, and so on that are not covered in our work. Stronger content moderation tools and systems can contribute to mitigating fairness-related harms in AI systems. For example, systems that don’t over-flag neutral statements with minority identity group mentions can help ensure better representation of diverse perspectives and experiences, while systems that can better flag implicit hate speech can support more inclusive technology.
Acknowledgment
This work was conducted by PhD students Thomas Hartvigsen (opens in new tab) and Saadia Gabriel (opens in new tab) during their internships at Microsoft Azure and Microsoft Research. Hamid Palangi (opens in new tab), Dipankar Ray (opens in new tab), Maarten Sap (opens in new tab), and Ece Kamar (opens in new tab) served as advisors on the work. A special thanks to Misha Bilenko (opens in new tab) from Azure ML for making the compute resources available and to Microsoft Research for supporting our large-scale human study.
Please note: This research, the GitHub repository, and examples from our work included in this blog contain and discuss content that is offensive or upsetting. All materials are intended to support research that improves hate speech detection methods. Included examples of hate speech don’t represent how the authors or sponsors feel about any minority identity groups. Hate speech applies to a range of minority identity groups; for the purposes of this research, we focus on 13 of them (as shown in Figure 1). Content moderation tools are part of larger content moderation systems. These systems also include human expertise and thoughtful policy and regulatory development. Even the most robust content moderation tools and datasets require systems with human supervision.




