
This paper was presented at the ACM SIGMOD/Principles of Database Systems Conference (opens in new tab) (SIGMOD/PODS 2024), the premier forum on large-scale data management and databases.

As organizations grapple with ever-expanding datasets, the adoption of data lakes has become a vital strategy for scalable and cost-effective data management. The success of these systems largely depends on the file formats used to store the data. Traditional formats, while efficient in data compression and organization, falter with frequent updates. Advanced table formats like Delta Lake, Apache Iceberg, and Apache Hudi offer promising solutions with easier data modifications and historical tracking, yet their efficacy lies in their ability to handle continuous updates, a challenge that requires extensive and thorough evaluation.
Our paper, “LST-Bench: Benchmarking Log-Structured Tables in the Cloud,” presented at SIGMOD 2024, introduces an innovative tool designed to evaluate the performance of different table formats in the cloud. LST-Bench builds on the well-established TPC-DS (opens in new tab) benchmark—which measures how efficiently systems handle large datasets and complex queries—and includes features specifically designed for table formats, simplifying the process of testing them under real-world conditions. Additionally, it automatically conducts tests and collects essential data from both the computational engine and various cloud services, enabling accurate performance evaluation.
Flexible and adaptive testing
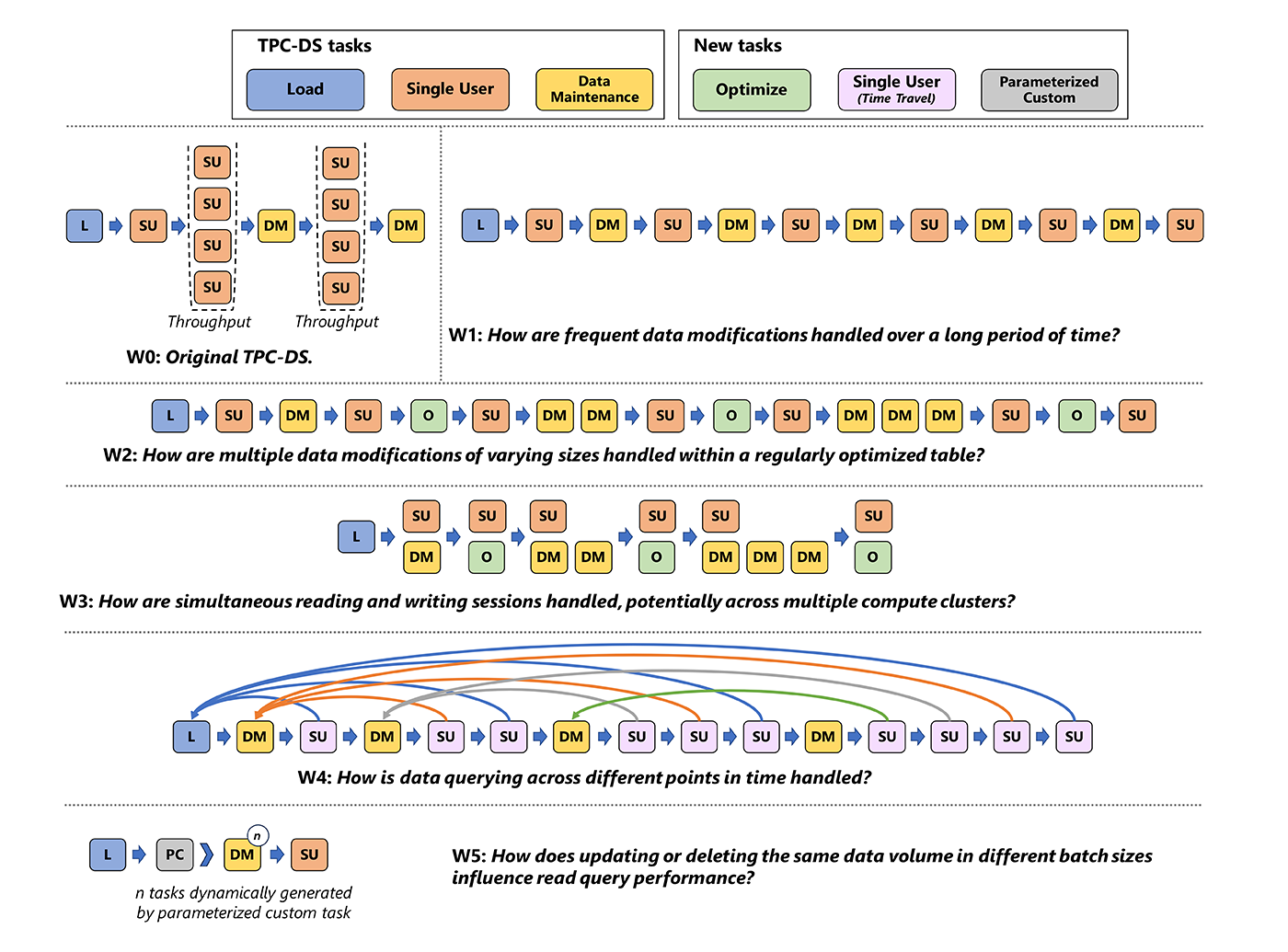
Designed for flexibility, LST-Bench adapts to a broad range of scenarios, as illustrated in Figure 1. The framework was developed by incorporating insights from engineers, facilitating the integration of existing workloads like TPC-DS, while promoting reusability. For example, each test session establishes a new connection to the data-processing engine, organizing tasks as a series of statements. This setup permits developers to run multiple tasks either sequentially within a single session or concurrently across various sessions, reflecting real-world application patterns.

The TPC-DS workload comprises the following foundational tasks:
- Load task: Loads data into tables for experimentation.
- Single User task: Executes complex queries to test the engine’s upper performance limit.
- Data Maintenance task: Handles data insertions and deletions.
LST-Bench introduces the following tasks specific to table formats:
- Optimize task: Compacts the data files within a table.
- Time Travel task: Enables querying data as it appeared at a specified point in the past.
- Parameterized Custom task: Allows for the integration of user-defined code to create dynamic workflows.
These features enable LST-Bench to evaluate aspects of table formats that are not covered by TPC-DS, providing deeper insights into their performance, as shown in Figure 2.
A degradation rate metric to measure stability
In addition to these workload extensions, LST-Bench introduces new metrics to evaluate table formats both comprehensively and fairly. It retains the traditional metric categories like performance, storage, and compute efficiency, and it adds a new stability metric called degradation rate. This new metric specifically addresses the impact of accumulating small files in the data lake—a common issue arising from frequent, small updates—providing an assessment of the system’s efficiency over time.
The degradation rate is calculated by dividing a workload into different phases. The degradation rate \(S_{DR}\) is defined as follows:
\(S_{DR}={1\over n}\sum\limits_{i=1}^n\dfrac{M_{i} – M_{i-1}}{M_{i-1}}\)
Here, \(M_i\) represents the performance or efficiency metric value of the \(i^{th}\) iteration of a workload phase, and \(n\) reflects the total number of iterations of that phase. Intuitively, \(S_{DR}\) is the rate at which a metric grows or shrinks, reflecting cumulative effects of changes in the underlying system’s state. This rate provides insight into how quickly a system degrades over time. A stable system demonstrates a low \(S_{DR}\), indicating minimal degradation.
LST-Bench implementation
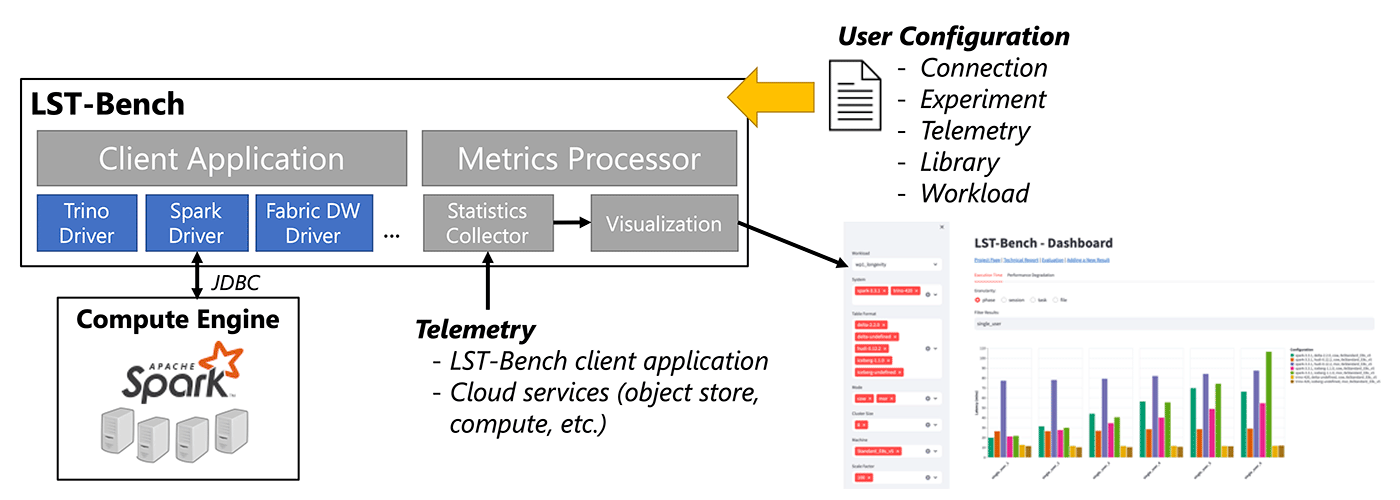
The LST-Bench features a Java-based client application that runs SQL workloads on various engines, enabling users to define tasks, sessions, and phase libraries to reuse different workload components. This allows them to reference these libraries in their workload definitions, add new task templates, or create entirely new task libraries to model-specific scenarios.
LST-Bench also includes a processing module that consolidates experimental results and calculates metrics to provide insights into table formats and engines. It uses both internal telemetry from LST-Bench and external telemetry from cloud services, such as resource utilization, storage API calls, and network I/O volume. The metrics processor offers multiple visualization options, including notebooks and a web app, to help users analyze performance data effectively.
Implications and looking ahead
LST-Bench integrates seamlessly into the testing workflows of the Microsoft Fabric (opens in new tab) warehouse, allowing that team to rigorously assess engine performance, evaluate releases, and identify any issues. This leads to a more reliable and optimized user experience on the Microsoft Fabric data analytics platform. Additionally, LST-Bench holds promise as a foundational tool for various Microsoft initiatives. It’s currently instrumental in research projects focused on improving data organization for table formats, with the goal of increasing the performance of customer workloads on Microsoft Fabric. LST-Bench is also being used to evaluate the performance of table formats converted using Apache XTable (Incubating) (opens in new tab), an open-source tool designed to prevent data silos within data lakes.
LST-Bench is open source (opens in new tab), and we welcome contributors to help expand this tool, making it highly effective for organizations to thoroughly evaluate their table formats.
Spotlight: Microsoft research newsletter

Microsoft Research Newsletter
Acknowledgements
We would like to thank Joyce Cahoon and Yiwen Zhu for their valuable discussions on the stability metric, and Jose Medrano (opens in new tab) and Emma Rose Wirshing (opens in new tab) for their feedback on LST-Bench and their work on integrating it with the Microsoft Fabric Warehouse.



