
Recently, Transformer-based deep learning models like GPT-3 have been getting a lot of attention in the machine learning world. These models excel at understanding semantic relationships, and they have contributed to large improvements in Microsoft Bing’s search experience and surpassing human performance on the SuperGLUE academic benchmark. However, these models can fail to capture more nuanced relationships between query and document terms beyond pure semantics.
In this blog post, we are introducing “Make Every feature Binary” (MEB), a large-scale sparse model that complements our production Transformer models to improve search relevance for Microsoft customers using AI at Scale. To make search more accurate and dynamic, MEB better harnesses the power of large data and allows for an input feature space with over 200 billion binary features that reflect the subtle relationships between search queries and documents.
Why “Make Every feature Binary” to improve search?
One reason MEB works so well as a complement to Transformer-based deep learning models for search relevance is that it can map single facts to features, allowing MEB to gain a more nuanced understanding of individual facts. For example, many deep neural network (DNN) language models might overgeneralize when filling in the blank in this sentence: “(blank) can fly.” Since the majority of DNN training cases result in “birds can fly,” DNN language models might only fill the blank with the word “birds.”
MEB avoids this by assigning each fact to a feature, so it can assign weights that distinguish between the ability to fly in, say, a penguin and a puffin. It can do this for each of the characteristics that make a bird—or any entity or object for that matter—singular. Instead of saying “birds can fly,” MEB paired with Transformer models can take this to another level of classification, saying “birds can fly, except ostriches, penguins, and these other birds.”
There’s also an element of improving the method for using data more efficiently as scale increases. The ranking of web results in Bing is a machine learning problem that benefits from learning over huge amounts of user data. A traditional approach for leveraging click data is to extract thousands of handcrafted numeric features for each impressed query/document pair and to train a gradient boosted decision tree (GBDT) model.
However, even the state-of-the-art GBDT trainer, LightGBM (opens in new tab), converges after hundreds of millions of rows of data, due to limited feature representation and model capacity. Also, these handcrafted numeric features tend to be very coarse by nature. For example, they can capture how many times the term at a given position in the query occurs in the document, but information about what the specific term is gets lost in this representation. Additionally, the features in this method don’t always accurately account for things like word order in the search query.
To unlock the power of huge data and enable feature representation that better reflects the relationships between queries and documents, MEB is trained with more than 500 billion query/document pairs from three years of Bing searches. The input feature space has more than 200 billion binary features. With FTRL (opens in new tab), the latest version is a sparse neural network model with 9 billion features and over 135 billion parameters.
Uncovering hidden intent with the largest universal model served at Microsoft
MEB is running in production for 100 percent of Bing searches, in all regions and languages. It is the largest universal model we’re serving at Microsoft, and it demonstrates an excellent ability to memorize facts represented by these binary features while reliably learning from vast amounts of data in a continuous way.
We’ve empirically found that training over this large amount of data is a unique capability of large sparse neural networks. When feeding the same Bing logs to a LightGBM model and training with traditional numeric features, such as BM25 and other kinds of query and document matching features, the model quality no longer improves after one month of data is used. This indicates that the model capacity is not enough to benefit from larger amounts of data. In contrast, MEB is trained on three years of data, and we have found that it continues to learn with more data added, indicating that model capacity increases with newly added data.
When compared to Transformer-based deep learning models, the MEB model also demonstrates interesting capabilities to learn beyond semantic relationships. When looking into the top features learned by MEB, we found it can learn hidden intents between query and document.
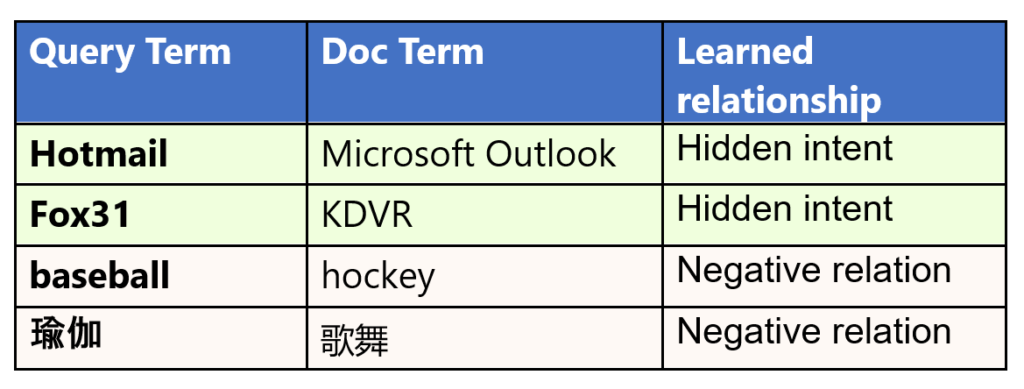
For example, MEB learned that “Hotmail” is strongly correlated to “Microsoft Outlook,” even though they are not close to each other in terms of semantic meaning. MEB picks up on a nuanced relationship between these words: Hotmail was a free web-based email service provided by Microsoft that later changed its name to Microsoft Outlook. Similarly, it learned a strong connection between “Fox31” and “KDVR,” where KDVR is the call sign of the TV channel in Denver, CO, that’s operating under the brand Fox31. Once again, there’s no overt semantic connection between the two phrases.
More interestingly, MEB can identify negative relationships between words or phrases, revealing what users do not want to see for a query. For example, users searching for “baseball” usually do not click on pages talking about “hockey” even though they are both popular sports. The same applies when users search for 瑜伽 (yoga) but do not click on documents containing 歌舞 (dancing and singing). Understanding these negative relationships can help to omit irrelevant search results.
These relationships learned by MEB are very complementary to the ones learned by Transformer-based DNN models. The benefits for search relevance and user experience are very clear. The introduction of MEB on top of our production Transformer models resulted in:
- An almost 2 percent increase on clickthrough rate (CTR) on the top search results. Those results found “above the fold” without the need to scroll down.
- A reduction in manual query reformulation by more than 1 percent. Users needing to manually reformulate queries means they didn’t like the results they found with their original query.
- A reduction of clicks on pagination by over 1.5 percent. Users needing to click on the “next page” button means they didn’t find what they were looking for on the first page.
How MEB trains on data and serves features at large scale
Model Structure
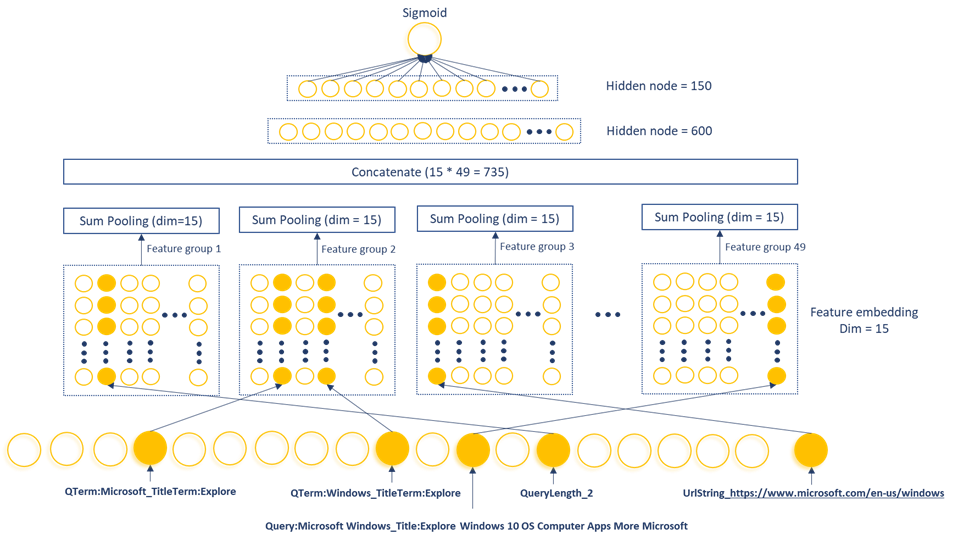
As illustrated in Figure 1, the MEB model is composed of a binary feature input layer, a feature embedding layer, a pooling layer, and two dense layers. The input layer contains 9 billion features, generated from 49 feature groups, with each binary feature encoded into a 15-dimension embedding vector. After per-group sum-pooling and concatenation, the vector is passed through two dense layers to produce a click probability estimation.
Training data and unifying features as binary
MEB uses three years of search logs from Bing as training data. For each Bing search impression, we use heuristics to determine if the user was satisfied with the document(s) they clicked. We label these “satisfactory” documents as positive samples. Other documents in the same impression are labeled as negative samples. For each query and document pair, binary features are extracted from the query text, the document URL, title, and body text. These features are fed into a sparse neural network model to minimize the cross-entropy loss between the model’s predicted click probability and the actual click label.
Feature design and large-scale training are key to the success of MEB. MEB features are defined on the very specific term–level or N-gram–level relationship between query and document, which can’t be captured by traditional numeric features that only care about the matching count between query and document. (N-grams are a sequence of N terms.) To fully release the power of this large-scale training platform, all the features are designed as binary features, which can easily cover manually crafted numeric features and features directly extracted from raw text in a consistent way. Doing so allows MEB to do end-to-end optimization in one path. The current production model uses three main types of features, which are described below.
Query and Document N-gram pair features
N-gram pair features are generated based on N-gram combinations of query and document fields from the Bing search logs. As demonstrated in Figure 2, N-grams from the query text will combine with N-grams from the document URL, title, and body text to form N-gram pair features. Longer N-grams (for higher values of N) are able to capture richer and more nuanced concepts. However, processing them is exponentially more expensive as N increases. In our production model, N is set to 1 and 2 (unigrams and bigrams respectively).
We also generate features by combining the entire query text and document field. For example, the feature “Query_Title_Microsoft Windows_Explore Windows 10 OS Computer Apps More Microsoft” is a feature generated from query=”Microsoft Windows” and document title=”Explore Windows 10 OS Computer Apps More Microsoft”.
One-hot encoding of bucketized numeric features
Numeric features are transformed into binary format by first bucketizing them and then by applying one-hot encoding. In the example depicted in Figure 2, the numeric feature “QueryLength” can take any integer value between 1 to MaxQueryLength. We define MaxQueryLength buckets for this feature so that query “Microsoft Windows” has the binary feature QueryLength_2 equal to 1.
One-hot encoding of categorical features
Categorical features can be transformed into binary features through one-hot encoding in a straightforward way. For example, UrlString is a categorical feature with each unique URL string text as a different category.

Continuous training supports a trillion query/document pairs and refreshes daily
To enable training with such a huge feature space, we leveraged Woodblock, an internal large-scale training platform built by the Microsoft Advertising (opens in new tab) team. It is a distributed, large-scale, and high-performance solution for training large sparse models. Built on top of TensorFlow, Woodblock fills the gap between general deep learning frameworks and industrial requirements for billions of sparse features. With deep optimization on I/O and data processing, it can train hundreds of billions of features within hours using CPU and GPU clusters.
Even with the Woodblock pipeline, training MEB with three years of Bing search logs that contain almost a trillion query/document pairs would be very hard to do in one shot. Instead, we apply a continuous training approach, with each month of new data continuously training the previous model, trained on top of the previous months of data.
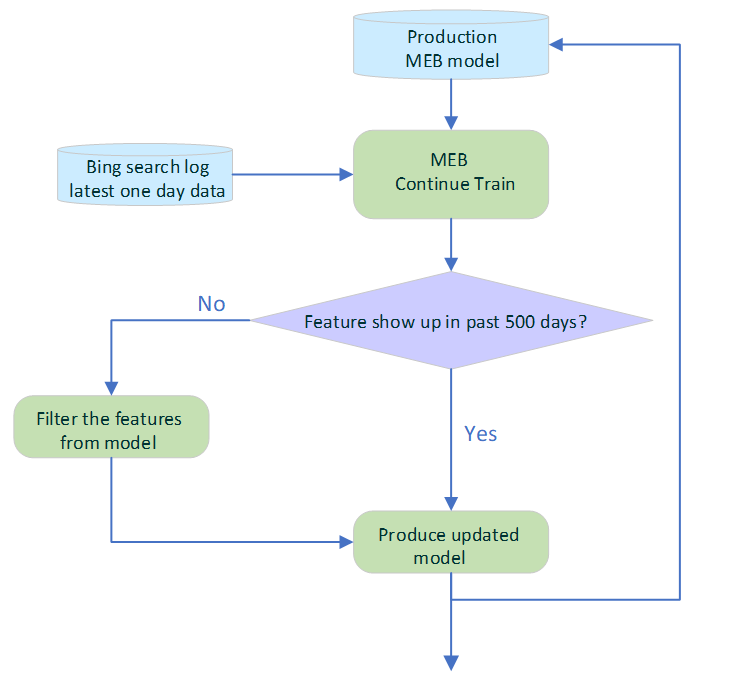
More importantly, even after implementation into Bing, the model is refreshed daily by continuously training with the latest daily click data, as illustrated in Figure 3. To avoid the negative impact of stale features, an auto-expiration strategy checks each feature’s timestamp and filters out features that have not shown up in the last 500 days. After continuous training, the daily deployment of the updated model is fully automated.
Spotlight: Blog post

MedFuzz: Exploring the robustness of LLMs on medical challenge problems
Medfuzz tests LLMs by breaking benchmark assumptions, exposing vulnerabilities to bolster real-world accuracy.
Serving an extremely large model using the Bing ObjectStore platform
The MEB sparse neural network model occupies 720 GB when loaded into memory. During peak traffic time, the system needs to sustain 35 million feature lookups per second, and so it is not possible to serve MEB from a single machine. Instead, we leverage Bing’s homegrown ObjectStore (opens in new tab) service to host and serve the MEB model.
ObjectStore is a multi-tenant, distributed key-value store supporting both data and compute hosting. The feature embedding layer of MEB is implemented as a table lookup operation in ObjectStore, with each binary feature hash used as a key to retrieve its embedding produced at training time. The pooling and dense layer parts are more compute-heavy and are executed in an ObjectStore Coproc—a near-data compute unit—hosting a user-defined function. MEB separates compute and data serving into different shards. Each compute shard takes a portion of production traffic for neural-network processing, and each data shard hosts a portion of the model data, as shown in Figure 4.
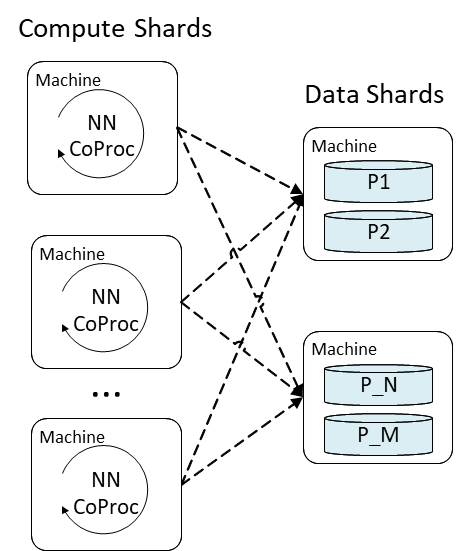
Since most workloads running on ObjectStore are exclusively doing storage lookups, co-locating the MEB compute shards and in-memory data shards allows us to maximize the ObjectStore compute and memory resources in the multi-tenant cluster. With the shards distributed across many machines, we are also able to fine-control the load on each machine such that the single digit milliseconds serving latency could be achieved in MEB.
Powering faster search that understands content better
We’ve found very large sparse neural networks like MEB can learn nuanced relationships complementary to the capabilities of Transformer-based neural networks. This improved understanding of search language results in significant benefits to the entire search ecosystem:
- Thanks to improved search relevance, Bing users are able to find content and achieve tasks faster, with a reduced need to reformulate their queries or go beyond page 1.
- Because MEB understands content better, publishers and webmasters get more traffic to their properties, and they can focus on satisfying their customers instead of spending time finding the right keyword that will help them rank higher. A concrete example is product rebranding, where the MEB model may be able to learn the relationship between the old and new name automatically, much like it did for “Hotmail” and “Microsoft Outlook.”
If you are using DNNs to power your business, we recommend experimenting with large sparse neural networks to complement those models. This is especially true if you have a large historical stream of user interactions and can easily construct simple binary features. If you go down this path, we do recommend making sure the model is updated in as near to real-time as possible.
MEB is just one example of how our team is creating impactful cutting-edge technology that advances scale and efficiency for improved search. If you’re interested in large-scale modeling for search and recommendations, the Core Search & AI team is hiring! You can find our current openings on the Microsoft Careers website (opens in new tab).



