A few months ago, we introduced Orca, a 13-billion parameter language model that demonstrated strong reasoning abilities by imitating the step-by-step reasoning traces of more capable LLMs.
Orca 2 is the latest step in our efforts to explore the capabilities of smaller LMs (on the order of 10 billion parameters or less). With Orca 2, we continue to show that improved training signals and methods can empower smaller language models to achieve enhanced reasoning abilities, which are typically found only in much larger language models.
Orca 2 significantly surpasses models of similar size (including the original Orca model) and attains performance levels similar to or better than models 5-10 times larger, as assessed on complex tasks that test advanced reasoning abilities in zero-shot settings.
Orca 2 comes in two sizes (7 billion and 13 billion parameters); both are created by fine-tuning the corresponding LLAMA 2 base models on tailored, high-quality synthetic data. We are making the Orca 2 weights publicly available to encourage research on the development, evaluation, and alignment of smaller LMs.
Using LLMs to train smaller language models
Frontier Language Models such as GPT-4, PaLm, and others have demonstrated a remarkable ability to reason, for example, answering complex questions, generating explanations, and even solving problems that require multi-step reasoning; capabilities that were once considered beyond the reach of AI. Traditionally, such abilities have not been observed in smaller language models, so the challenge is how to use our growing knowledge of large language models to increase the abilities of these smaller models.
Expanding the capabilities of smaller language models
A key insight behind Orca 2 is that different tasks could benefit from different solution strategies (e.g. such as step-by-step processing, recall then generate, recall-reason-generate, extract-generate, and direct answer) and that the solution strategy employed by a large model may not be the best choice for a smaller one. For example, while an extremely capable model like GPT-4 can answer complex tasks directly, a smaller model may benefit from breaking the task into steps.
Orca 2 is trained with an expanded, highly tailored synthetic dataset. The training data was generated such that it teaches Orca 2 various reasoning techniques, such as step-by-step processing, recall then generate, recall-reason-generate, extract-generate, and direct answer methods, while also teaching it to choose different solution strategies for different tasks.
The training data is obtained from a more capable teacher model. Note that we can obtain the teacher’s responses through very detailed instructions and even multiple calls, depending on the task and the desired behavior of the model. In the absence of the original instruction, which details how to approach the task, the student model will be encouraged to learn that underlying strategy as well as the reasoning capabilities it elicits.
video series

On Second Thought
A video series with Sinead Bovell built around the questions everyone’s asking about AI. With expert voices from across Microsoft, we break down the tension and promise of this rapidly changing technology, exploring what’s evolving and what’s possible.
Orca 2 has reasoning capabilities comparable to much larger models
To evaluate Orca 2, we use a comprehensive set of 15 diverse benchmarks that correspond to approximately 100 tasks and more than 36,000 unique test cases in zero-shot settings. The benchmarks cover a variety of aspects, including language understanding, common-sense reasoning, multi-step reasoning, math problem solving, reading comprehension, summarizing, groundedness, truthfulness, and toxic content generation and identification.
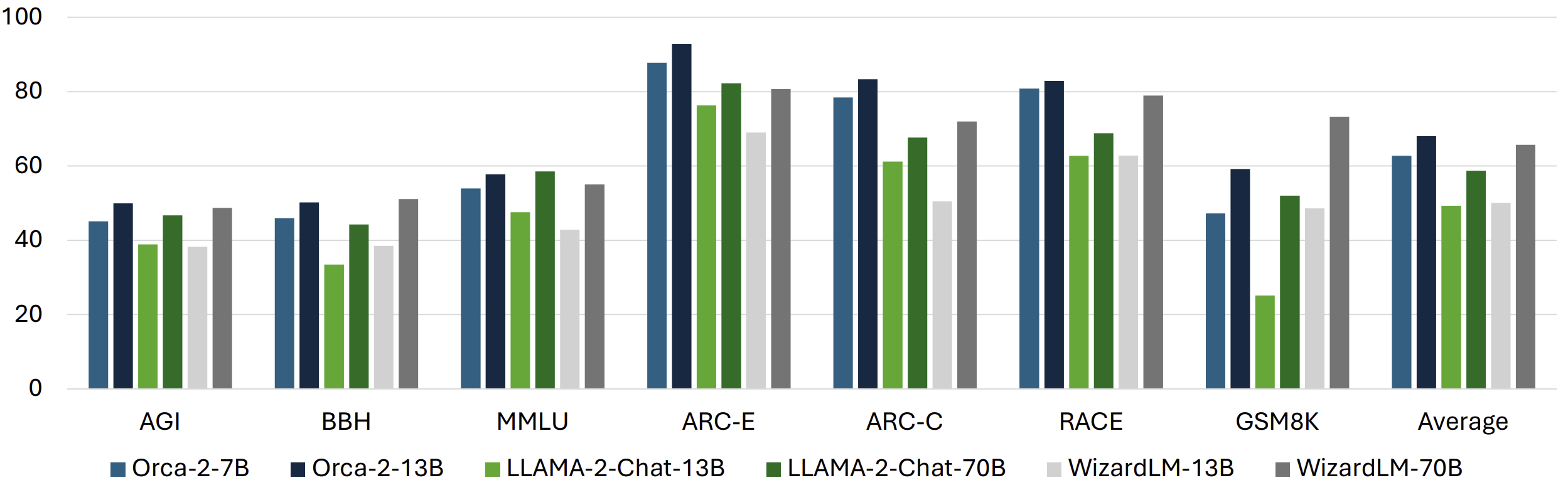
Our preliminary results indicate that Orca 2’s performance significantly surpasses models of similar size. It also attains performance levels similar or better than those of models at least 10 times larger, showcasing the potential of equipping smaller models with better reasoning capabilities.
Orca 2 models exhibit limitations common to other language models and could retain many of the constraints of the base models upon which they were trained. While Orca 2 training could be applied to different base models, we report results based on using LLaMA-2 7B and 13B models. Orca 2 models have not gone through reinforcement learning from human feedback (RLHF) training for safety.
Conclusion
Our research on the Orca 2 model has yielded significant insights into enhancing the reasoning abilities of smaller language models. By strategically training these models with tailored synthetic data, we have achieved performance levels that rival or surpass those of larger models, particularly in zero-shot reasoning tasks.
Orca 2’s success lies in its application of diverse reasoning techniques and the identification of optimal solutions for various tasks. While it has several limitations, including limitations inherited from its base models and common to other language models, Orca 2’s potential for future advancements is evident, especially in improved reasoning, specialization, control, and safety of smaller models. The use of carefully filtered synthetic data for post-training emerges as a key strategy in these improvements.
Our findings underscore the value of smaller models in scenarios where efficiency and capability need to be balanced. As larger models continue to excel, our work with Orca 2 marks a significant step in diversifying the applications and deployment options of language models.