
This research paper was accepted by the eighth ACM/IEEE Conference on Internet of Things Design and Implementation (opens in new tab) (IoTDI), which is a premier venue on IoT. The paper describes a framework that leverages cloud resources to execute large deep neural network (DNN) models with higher accuracy to improve the accuracy of models running on edge devices.
Leveraging the cloud and edge concurrently
The internet is evolving towards an edge-computing architecture to support latency-sensitive DNN workloads in the emerging Internet of Things and mobile computing applications domains. However, unlike cloud environments, the edge has limited computing resources and cannot run large, high accuracy DNN models (opens in new tab). As a result, past work has focused on offloading some of the computation to the cloud to get around this limitation. However, this comes at the cost of increased latency.
For example, in edge video analytics use cases, such as road traffic monitoring, drone surveillance, and driver assist technology, one can transmit occasional frames to the cloud to perform object detection—a task ideally suited to models hosted on powerful GPUs. On the other hand, the edge handles the interpolating intermediate frames through object tracking—a relatively inexpensive computational task performed using general-purpose CPUs, a low-powered edge GPU, or other edge accelerators (e.g., Intel Movidius Neural Stick). However, for most real-time applications, processing data in the cloud is infeasible due to strict latency constraints.
PODCAST SERIES

AI Testing and Evaluation: Learnings from Science and Industry
Discover how Microsoft is learning from other domains to advance evaluation and testing as a pillar of AI governance.
In our research paper, REACT: Streaming Video Analytics On The Edge With Asynchronous Cloud Support, we propose and demonstrate a novel architecture that leverages both the edge and the cloud concurrently to perform redundant computations at both ends. This helps retain the low latency of the edge while boosting accuracy with the power of the cloud. Our key technical contribution is in fusing the cloud inputs, which are received asynchronously, into the stream of computation at the edge, thereby improving the quality of detection without sacrificing latency.
Fusing edge and cloud detections
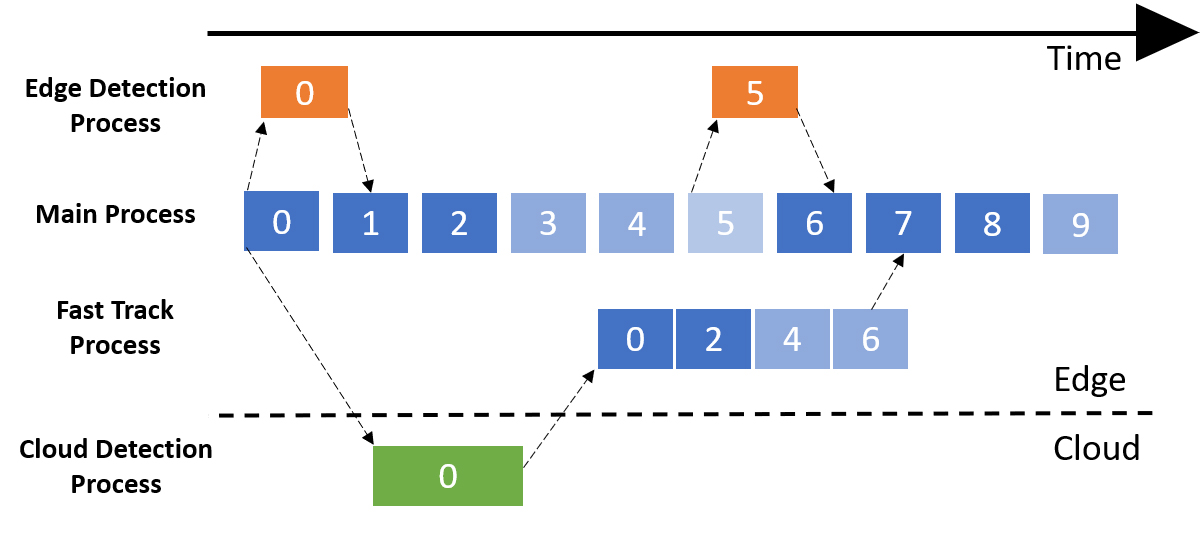

We illustrate our fusion approach in REACT for object detection in videos. Figure 1 shows the result of object detection using a lightweight edge model. This suffers from both missed objects (e.g., cars in Frame 1 are not detected) and misclassified objects (e.g., the van on the right of the frame that has been misclassified as a car).
To address the challenges of limited edge computation capacity and the drop in accuracy from using edge models, we follow a two-pronged approach. First, since the sequence of video frames are spatiotemporally correlated, it suffices to call edge object detection only once every few frames. As illustrated in Figure 1(a), edge detection runs every fifth frame. As shown in the figure, to interpose the intermediate frames, we employ a comparatively lightweight operation of object tracking. Second, to improve the accuracy of inference, select frames are asynchronously transmitted to the cloud for inference. Depending on network delay and the availability of cloud resources, cloud detections reach the edge device only after a few frames. Next, the newer cloud detections—previously undetected—are merged with the current frame. To do this, we feed the cloud detection, which was made on an old frame, into another instance of the object tracker to “fast forward” to the current time. The newly detected objects can then be merged into the current frame so long as the scene does not change abruptly. Figure 1(b) shows a visual result of our approach on a dashcam video dataset.
Here’s a more detailed description of how REACT goes about combining the edge and the cloud detections. Each detection contains objects represented by a ⟨class_label, bounding_box, confidence_score⟩ tuple. Whenever we receive a new detection (either edge or cloud), we purge from the current list the objects that were previously obtained from the same detection source (either cloud or edge). Then we form a zero matrix of size (c, n). Here, c and n are the indices associated with detections from current list and new source, respectively. We populate the matrix cell with the Intersection over Union (IoU) values—if it is greater than 0.5—corresponding to specific current and new detections. We then perform a linear sum assignment, which matches two objects with the maximum overlap. For overlapped objects, we modify the confidence values, bounding box, and class label based on the new detections’ source. Specifically, our analysis reveals that edge detection models could correctly localize objects, but often had false positives, i.e., they assigned class labels incorrectly. In contrast, cloud detections have higher localization error but lower error for class labels. Finally, newer objects (unmatched ones) will then get added to the list of current objects with the returned confidence values, bounding boxes, and class labels. Thus, REACT’s fusion algorithm must consider multiple cases —such as misaligned bounding boxes, class label mismatch, etc. — to consolidate the edge and cloud detections into a single list.
| Detector | Backbone | Where | #params |
|---|---|---|---|
| Faster R-CNN | ResNet50-FPN | Cloud | 41.5M |
| RetinaNet | ResNet50-FPN | Cloud | 36.1M |
| CenterNet | DLA34 | Cloud | 20.1M |
| TinyYOLOv3 | DN19 | Edge | 8.7M |
| SSD | MobileNetV2 | Edge | 3.4M |
In our experimentation, we leveraged state-of-the-art computer vision algorithms for getting object detections at the edge and the cloud (see Table 1). Further, we use mAP@0.5 (mean average precision at 0.5 IoU), a metric popular in the computer vision community to measure the performance of object detections. Moreover, to evaluate the efficacy of REACT, we looked at two datasets:
- VisDrone (opens in new tab): as drone-based surveillance
- D2City (opens in new tab): dashcam-based driver assist
Based on our evaluation, we observed that REACT outperforms baseline algorithms by as much as 50%. Also, we noted that edge and cloud models can complement each other, and overall performance improves due to our edge-cloud fusion algorithm.
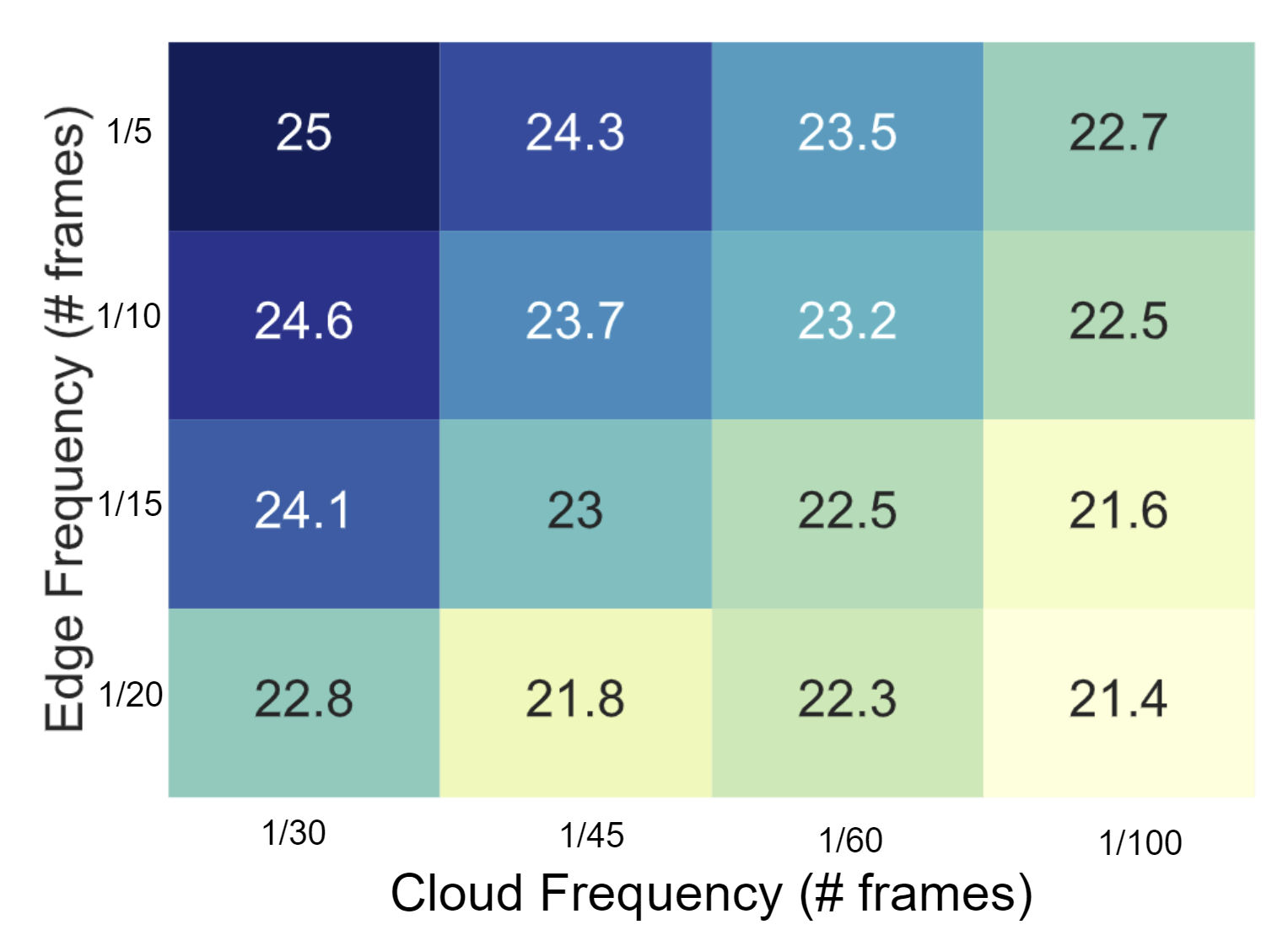
As already noted, the object detector runs only once every few frames and a lightweight object tracking is performed on intermediate frames. Running detection redundantly at both the edge and the cloud allows an application developer to flexibly trade off the frequency of edge versus cloud executions while achieving the same accuracy, as shown in Figure 2. For example, if the edge device experiences thermal throttling, we can pick a lower edge detection frequency (say, once every 20 frames) and complement it with cloud detection once every 30 frames to get mAP@0.5 of around 22.8. However, if there are fewer constraints at the edge, we can increase the edge detection frequency to once every five frames and reduce cloud detections to once every 120 frames to get similar performance (mAP@0.5 of 22.7). This provides a playground for fine-grained programmatic control.
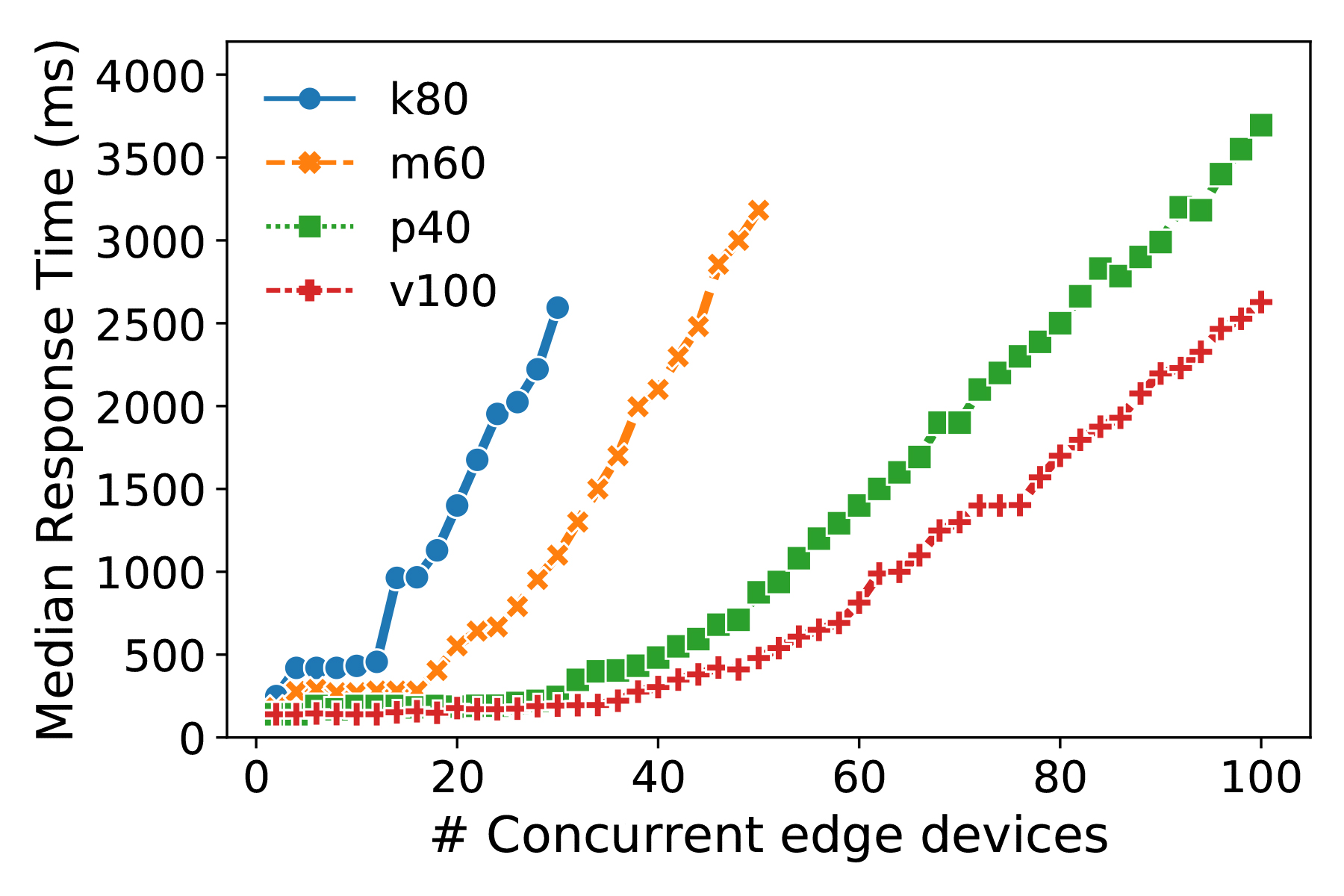
Further, one can amortize the cost of using cloud resources over multiple edge devices by having these share the same cloud hosted model. Specifically, if an application can tolerate a median latency of up to 500 ms, we can support over 60 concurrent devices at a time using the V100 GPU (Figure 3).
Conclusion
REACT represents a new paradigm of edge + cloud computing that leverages the resources of each to improve accuracy without sacrificing latency. As we have shown above, the choice between offloading and on-device inference is not binary, and redundant execution at cloud and edge locations complement each other when carefully employed. While we have focused on object detection, we believe that this approach could be employed in other contexts such as human pose-estimation, instance and semantic segmentation applications to have the “best of both worlds.”



