Initially meant to fit into one chapter, this text grew quickly and I had to split it into two. So there will be four parts of the article in total.
See Introduction (or Part 1) >
By no means this list is “complete”. I think every security person on the planet can add couple extra good tricks learned through their experience.
Microsoft research podcast

What’s Your Story: Lex Story
Model maker and fabricator Lex Story helps bring research to life through prototyping. He discusses his take on failure; the encouragement and advice that has supported his pursuit of art and science; and the sabbatical that might inspire his next career move.
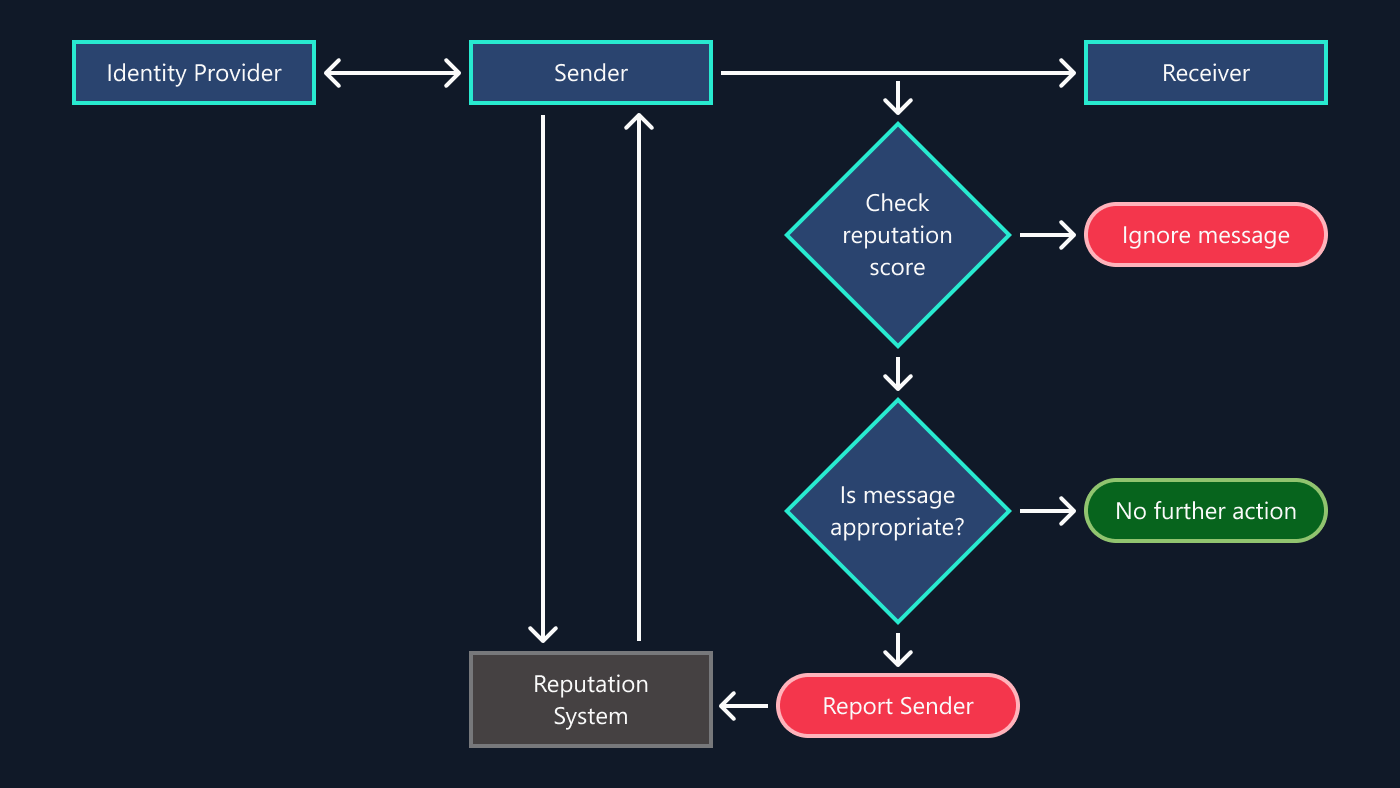
Heuristic 1: “Audit”
I already considered this method in the previous chapter, so I’ll be brief here.
To run a security “audit”, you logically split the system into a set of elements and ask “security” questions about each one. Something like: “Do you use MD5?”, “Do you transfer user passwords over HTTP in clear?”, “Do you have Admin/root accounts with default password?”, “Do you parse JPGs with a home-grown untested parser?” and so on. Answering “Yes” to a question typically indicates an actionable security risk.
This approach may look primitive, but it does have its place. It usually prevents at least the most outrageous security holes. It provides *some* basic assurance when nothing else is available under the time crunch. The complexity of this algorithm is linear O(N) so it scales well. And when you are done with it, you have a bonus list of high risk targets for later detailed inspection.
On the complexity diagram, audit occupies “the first floor”:

The primary shortcoming of this method is that without special attention it would not consider complex interactions and so can miss contract violations like those I already presented:
Component A: “We don’t check any user’s input, we only archive and pass it through”
Component B: “We are the backend system and expect only good filtered inputs”
Despite that limitation, audit may still be helpful at least as a tool for the first quick assessment or when there is no time for anything else.
Some readers may point out that even audit may be tough to apply across really large products that can easily have 100,000 work items logged against them. Just reading the description of every item would consume weeks of time. It’s impossible to imagine asking 20 security questions about each one on top of that.
There are approaches to deal with that problem, both technical and organizational. The former focus on automatic items triaging and may utilize machine learning for that. The latter try to distribute this work across feature owners in some reasonable manner. Unfortunately, as this is a large topic, I’ll have to defer the discussion on it to (hopefully) some better times.
Heuristic 2: “Threat Modeling” (and other polynomial algorithms)
Let’s study this method in detail to understand some of the inherent limitations behind it.
Threat Modeling (at least in its “classical” form) primarily considers pairwise interactions between product elements. It can detect contract violations like the one just mentioned. It is a well-recognized and fairly efficient technique known broadly across the industry, it is easy to learn and there are tools that support it (e.g., http://www.microsoft.com/security/sdl/adopt/threatmodeling.aspx).
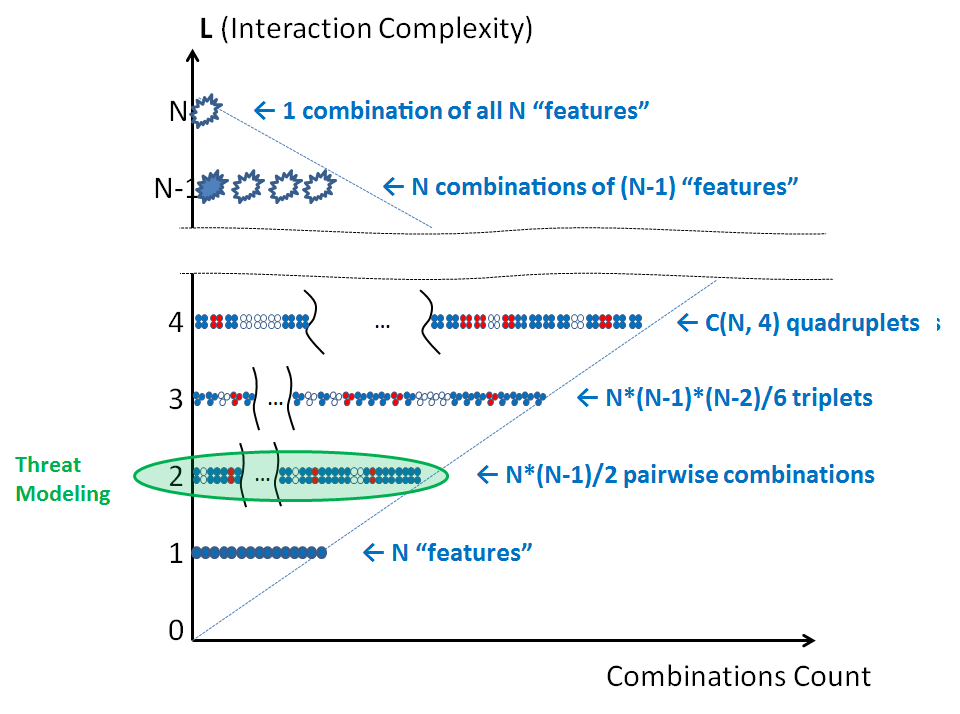
Downsides? It complexity is O(N2). No, the problem is not the volume of needed computations per se. It is rather how humans tend to respond to that, causing what I call “Threat Modeling fragmentation”.
If the cost to Threat Model one 10-element feature is 10*10 = 100 questions/checks, splitting it into two sets and running two independent Threat Modeling sessions would reduce that cost to 5*5 + 5*5 = 50 checks. That is a large time saving! Unfortunately, the benefit comes purely from ignoring the connections between separated subcomponents, and thus missing possible security holes associated with them. But under tight time pressure, it visibly saves time! So people across the organization may start slicing large features into smaller and smaller components, eventually producing a huge set of tiny isolated Threat Models each concerned “with my feature only” and totally ignoring most inter-component connections.
That is the mechanism that makes Thread Modeling difficult across large products.
That issue would affect any security review algorithm with a complexity significantly greater than linear O(N). Why? Because for any function f(N) with a growth faster than O(N) it is true that:
f(N1) + f(N2) < f(N1 + N2) [1]
[This says, effectively, that two smaller reviews cost less than one review of the combined features.]
So unless a carefully planned consolidation effort is applied during the release cycle, all human-performed “complex” non-linear security algorithms would naturally tend to produce fragmented results, up to a point (in the worst case) of impossibility to merge them back into any coherent single picture.
To be free from that problem, a security review heuristic must run in time not much worse than O(N). Otherwise, reviews fragmentation will kick in and it may consume significant resources to deal with it.
An algorithm that would be naturally feature-inclusive and facilitating holistic security is the one with the property opposite to that of [1]:
f(N1) + f(N2) >= f(N1 + N2) [2]
…which is satisfied if it runs in O(N) time, or faster.
But can it really run faster? The answer is “no”, because simply enumerating all features takes O(N) effort, and not enumerating any of them would mean we completely missed some, with possible associated vulnerabilities!
Therefore, a security review algorithm that scales well across a large org on large systems must run in precisely O(N) time.
In practice small deviations from that could be permissible. E.g., if doubling the scope of the review increases a cost per feature by a small fraction only it may still be acceptable. What constitutes a “small fraction”? A review process should scale well from individual feature (N = 1) to a large product (N = 1 million). A cost per feature should not change more than by an order of magnitude upon such an expansion. That dictates that a practically acceptable review algorithm should run in a time no worse than something like O(N*Log(N)) or O(N1.16).
Finally, it’s worth mentioning that since Threat Modeling primarily focuses on pairwise interactions, it tends to pay less attention to vulnerabilities arising from interactions of higher orders of complexity (i.e, of triplet interactions). As a result, some classes of security holes are not easily found with Threat Modeling. For example, people with field experience know that it is very difficult to represent (yet to detect) an XSS or a Clickjacking attack by using a Threat Model. In reality, those attacks are usually found only when a reviewer is aware of their possibility and specifically hunts for them.
Heuristic 3: “Continued Refactoring”
So a product was represented as a set of logical elements, you ran your favorite security review algorithm over it, found some issues, got them fixed.
A question is: if you re-represent the product as a different set of elements and run a review again, will you find new security bugs?
The answer is “almost certainly yes”
A semi-formal “proof” is easy. Let’s say a product has a total of M truly “atomic”, indivisible elements (such as bits of code). There are up to 2M potential interactions between them. For review purposes, the product is represented as a set of N1 < M groups of those bits. Within each group, the review is perfectly efficient – it finds all weaknesses. Outside the group, connections are ignored.
Assuming all groups are equal in size (just to show the point), how many connections would this grouping analyze? Within each group, there are (M/N1) elements, therefore 2(M/N1) possible interactions between them will be considered. Since there are N1 groups, the total coverage would be N1*2(M/N1) which is significantly lesser than 2M when N1 < M.
In other words, by choosing a split of a product we greatly shrink the volume of our review but make it manageable. That also means that by abandoning a representation and switching to an essentially different one a new fresh look is almost guaranteed. And so new security bugs!
Of course, the catch is to choose “good” representations. Neither splitting a product into just two components, nor slicing it down to individual bits is really helpful:
Choosing the right representation still remains a bit of an art.
So keep trying. The more meaningful ways to represent a product as “a set-of-somethings” you can creatively come up with, the more successful your review will be. Some of the possible approaches are:
- By feature
- By source file
- By API
- By binary
- By functionality domain
- By dev owner
- By location within the network topology
Generally, if you have k independent ways to re-represent your product, your security enhances roughly k times. So it makes sense to approach security from multiple angles. You split by feature and do Threat Modeling. Then you split by source file and do code review or scan for unwanted API. Then you split by API entry points and do fuzzing. Then by binary and scan for recognized insecure structures. And so on.
That’s one of the reasons why the “many eyes” argument works. And that is, essentially, how SDL-like heuristics arise. By the way, they still run in linear time – in O(k*N), precisely.
Heuristic 4: “Pattern Elimination”
Some security bugs are not completely random. Studying their past history may lead to recognition of a pattern. When a pattern is known, its detection could be automated. And then a whole class of security issues could be eliminated at one push of a button. At O(1) human time cost.
But patterns do not necessarily follow simple lines on product complexity diagram – they would rather tend to have quite complex shapes and may be difficult to spot:
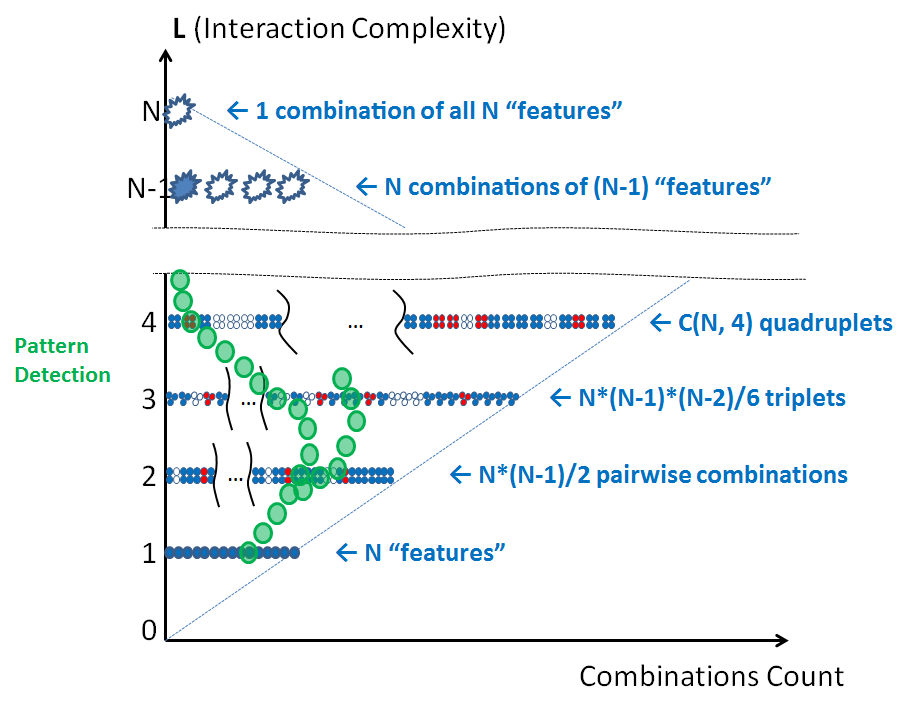
So pattern elimination is a two-step approach. First, it takes a good human guess. Next, cheap computational power essentially replicates the results of that guess across all the product, detecting and/or eliminating security issues.
The effectiveness of this approach is limited by four factors:
- It might take years of building security expertise before patterns would emerge behind what initially looks like a flow of random bugs. Yet the product may need to ship much sooner.
- Even if all patterns are somehow recognized (by a human), automating the necessary checks may not be easy. Depending on your definition of “a class” of security bugs, there are something between 20 and 3000 of them known in the industry. Each one may require a separate tool.
- Even good security tools cut only though a part of the security space. They may discover wonderful bugs in one direction and completely miss trivial issues nearby.
- Finally, the computational cost. Even with 1015 security checks available per a product, it is unrealistic to certify all interactions of complexity order higher than 4-5 for a product with more than a thousand logical elements (“features”) in it. In other words, we still need help of other methods.