By Christopher Bishop, Distinguished Scientist and Director of Microsoft Research Cambridge Lab

This month, I will attend the Conference and Workshop on Neural Information Processing Systems (NIPS), the premier gathering in the machine learning field. I’ve participated in this conference most years since it began in 1987 and I’m looking forward once again to catching up with colleagues and friends as well as exploring new developments in the field. Until recently, the conference attracted a few hundred attendees. The number of participants has grown rapidly in recent years and this year there are more than 4,500 people registered!
Microsoft Research blog

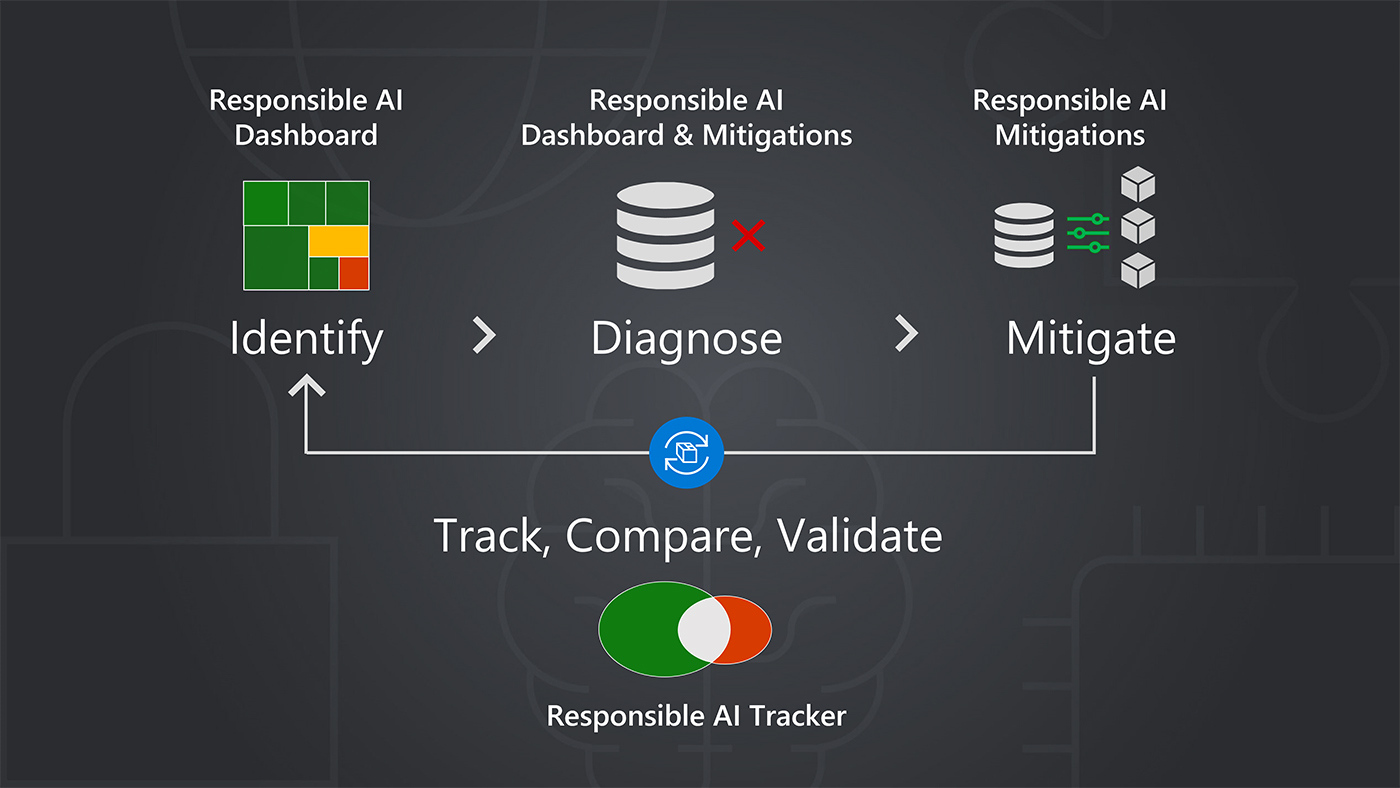
Microsoft at FAccT 2024: Advancing responsible AI research and practice
From studying how to identify gender bias in Hindi to uncovering AI-related risks for workers, Microsoft is making key contributions towards advancing the state of the art in responsible AI research. Check out their work at ACM FAccT 2024.
This explosion of activity in machine learning is remarkable and reflects the positive trend of research making its way to the marketplace. The first manifestation was the growing interest in “big data.” More recently, the focus shifted to “artificial intelligence.” I am regularly asked to speak on AI, including our research as well as more generally about the social, economic, business, and government policy implications. Everyone wants to know what AI means for them. And while there may be more to AI than machine learning, the resurgence of interest in building intelligent machines undoubtedly stems from advances in machine learning, including deep neural networks.
Is this excitement about AI just hype, or is there substance too? In my view, computing is undergoing the most substantial transformation since the foundations of the field were laid by Alan Turing some eight decades ago. This revolution has two complementary aspects. One is the shift from software solutions that are hand-crafted to solutions learned from data. The second transformation underway is from a view of computation as logic to one involving uncertainty expressed through probabilities. Learning from data and computing with uncertainty are intimately linked. From a probabilistic perspective, machine learning can be viewed as a reduction in uncertainty as a result of observing new data. This process is intrinsically sequential and open-ended, with the posterior distribution resulting from observations so far acting as the prior distribution for the next round of data.
This reduction in uncertainty is illustrated in the Clutter productivity feature, first designed in our labs and recently introduced into the Microsoft Exchange email system, used regularly by tens of millions of users. The feature employs a hierarchical probabilistic model to classify a user’s email into high and low priority. Since definition of high and low priority varies from one user to another, a hierarchical model is used to enable personalization. At the top level of the hierarchy is a probabilistic model learned across a large population of users. New users experience this prior model. The system continually adapts based on the user’s own email usage, providing each user a personal set of parameters derived from the shared prior. This allows a new user to have a positive initial experience, while also providing a system that continues to learn thereby creating a customized experience for each user.
Writing the software to implement these kinds of probabilistic models can be complex and challenging. In this case, however, the process was streamlined by creating the code automatically using Infer.NET, which provides a programming language and associated compiler. Infer.NET supports probabilistic variables as first class citizens and provides an elegant example of probabilistic programming. While there are numerous probabilistic programming languages under development, the focus of Infer.NET is efficient inference for large-scale applications.
Microsoft is placing machine learning and AI at the core of its strategy and we are looking for exceptionally talented scientists and engineers interested in this field to join us. We recently created a new AI and Research group of more than 5,000 researchers and engineers dedicated to developing advances in AI. There is tremendous breadth and depth of talent across the group and ample opportunities for teams to collaborate on some of the world’s toughest research and engineering challenges, resulting in the ability to positively impact the lives of millions. Microsoft has long been at the forefront of machine learning and AI. Today, Microsoft holds the record error rate for object recognition in images and recently announced the first achievement of human parity in word-error rate for speech recognition, both built on deep-learning technology developed in our research labs. We also recently announced the creation of the world’s first exa-scale AI supercomputer, based on a global deployment of FPGAs (field programmable gate arrays) in our data centers to complement our CPU and GPU capabilities.
At Microsoft, we are democratizing AI to empower every person and every organization on the planet to achieve more. I’m looking forward to NIPS as a superb opportunity to meet and talk to people about how they can join us in achieving this goal.
Related: