
Azure Cognitive Search (opens in new tab) is a cloud search service that gives developers APIs and tools to build rich search experiences over private, heterogeneous content in web, mobile, and enterprise applications. It has multiple components, including an API for indexing and querying, seamless integration through Azure data ingestion, deep integration with Azure Cognitive Services, and persistent storage of user-owned indexed content. At the heart of Azure Cognitive Search is its full text, keyword-based search engine built on the BM25 algorithm—an industry standard in information retrieval.
We’ve found that what customers desire next is higher-quality results out of the box with less effort, enabling them to deliver more relevant and actionable results to their customers.
As part of our AI at Scale effort, we lean heavily on recent developments in large Transformer-based language models to improve the relevance quality of Microsoft Bing. These improvements allow a search engine to go beyond keyword matching to searching using the semantic meaning behind words and content. We call this transformational ability semantic search—a major showcase of what AI at Scale can deliver for customers.
Spotlight: AI-POWERED EXPERIENCE

Microsoft research copilot experience
Discover more about research at Microsoft through our AI-powered experience
Semantic search has significantly advanced the quality of Bing search results, and it has been a companywide effort: top applied scientists and engineers from Bing leverage the latest technology from Microsoft Research and Microsoft Azure. Maximizing the power of AI at Scale requires a lot of sophistication. One needs to pretrain large Transformer-based models, perform multi-task fine-tuning across various tasks, and distill big models to a servable form with very minimal loss of quality. We recognize that it takes a large group of specialized talent to integrate and deploy AI at Scale products for customers, and many companies can’t afford these types of teams. To empower every person and every organization on the planet, we need to significantly lower the bar for everyone to use AI at Scale technology.
Today, Microsoft is excited to announce that we’re bringing semantic search capabilities to all Azure customers in preview. You no longer need a team of deep learning experts to take advantage of this technology: we packaged all the best AI at Scale (opens in new tab)technology, from models to software to hardware, into a single end-to-end AI solution. This is AI at Scale for everyone.
This post goes deeper into the Bing technology that made semantic search possible. We also encourage you to read the post “Introducing semantic search: Bringing more meaningful results to Azure Cognitive Search (opens in new tab),” which explains what new capabilities are available to you and how you can get started today.
Semantic search capabilities in Azure Cognitive Search
Below are the features enabled by semantic search in Azure Cognitive Search. Before our public preview release, we tested many of these features on our own products, and the examples below show the dramatic improvements in results we achieved by applying AI at Scale technology.
Semantic ranking: Massively improved relevance
Semantic search is moving beyond keyword-based ranking to a Transformer-based semantic ranking engine that understands the meaning behind the text. We performed A/B testing of these technologies on Microsoft Docs, a giant library of technical documentation for users, developers, and IT professionals. The Microsoft Docs team has been tuning its search index for search relevance the last couple of years and ran multiple experiments during that period. Semantic search increased the clickthrough rate of the search result page by 2.0 percent compared to its current production system and by 4.5 percent on longer queries (three or more words) as measured by an A/B experiment. This was the largest single improvement of key performance indicators for search engagement the Microsoft Docs team has ever seen.
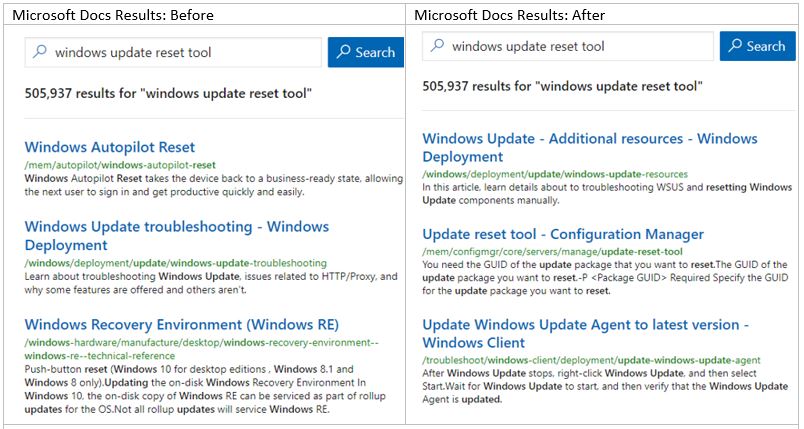
Semantic captions: Extractive summarization
We’ve found that returning relevant results isn’t the only important aspect of a search engine. The captions and snippets are also important to inform people about why a result is relevant—or perhaps not relevant—so they can proceed with a result, skip it, or reformulate their queries. Semantic captions uses extractive summarization to pull a snippet from the document that best summarizes why we think it’s relevant for the query.
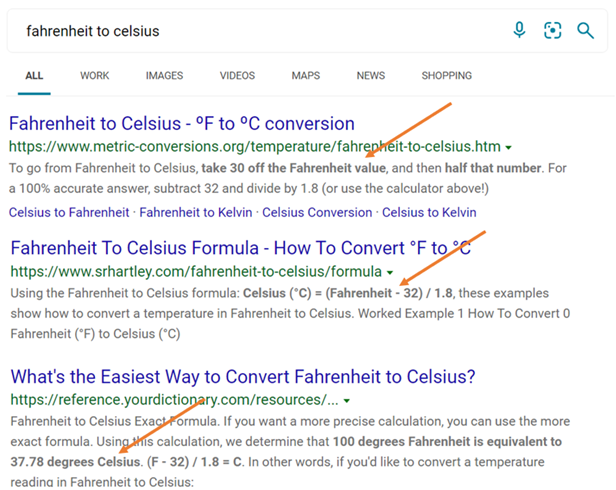
Semantic highlights: Machine reading comprehension
Going beyond keyword-based highlighting in captions and snippets is also valuable for improving user experience. With the right hit highlighting, people can immediately and directly get the answer they’re looking for, quickly scan a page of results to find the document they want, or even get a summary of a topic. Machine reading comprehension enables semantic highlights of relevant words or phrases on answers and captions to save people time.
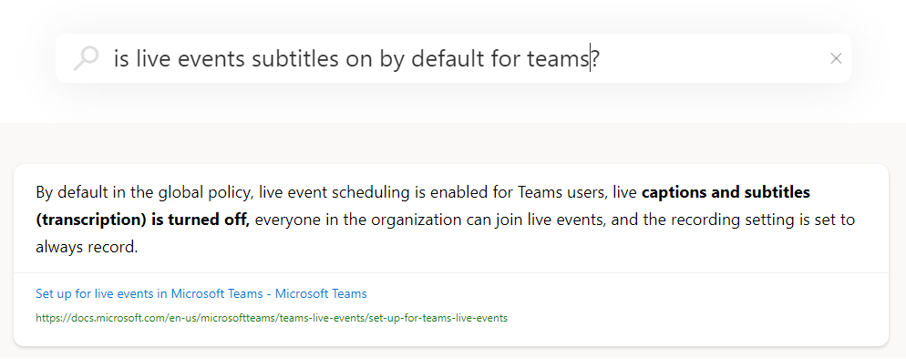
Semantic answers: Instant answers
Queries formulated as questions are one of the more important query segments on Bing. Our customers aren’t just looking for relevant documents but instant answers. We aim to provide them through machine learning—reading through all the documents in the corpus, running extractive summarization, and then using machine reading comprehension—and finally promoting a direct answer to an individual’s question to the top of the results.
Automatic spell correction
Ten to 15 percent of the queries issued to search engines are misspelled. When a query is misspelled, it’s difficult for any of the downstream search components to deliver results that match intent. Semantic search enables automatic spell correction, so customers don’t have to worry about having the perfect spelling.
The best of Microsoft Research
One of our promises for semantic search is to deliver to customers state-of-the-art technologies from research and product groups across Microsoft and the broader semantic search community, at the lowest cost. Microsoft Research has been at the forefront of some of the most important breakthroughs in natural language understanding and semantic search. Microsoft Research, together with other AI teams across the company, has developed a wide range of neural language models that substantially lift the state of the art across all major research benchmarks, including achieving human parity on public natural language understanding benchmarks such as SQuAD (opens in new tab), GLUE (opens in new tab), and SuperGLUE. These innovations from Microsoft Research have been adapted for real-world scenarios and incorporated into Microsoft products (including Azure Cognitive Search).
UniLM
“UniLMv2: Pseudo-Masked Language Models for Unified Language Model Pre-Training” (ICML 2020)
“Unified Language Model Pre-training for Natural Language Understanding and Generation” (NeurIPS 2019)
UniLM (Unified Language Model Pre-training) is a unified pretraining and fine-tuning framework that supports both natural language understanding and generation tasks, combining the strengths of autoencoding models like Google’s BERT and autoregressive models like OpenAI’s GPT-2. The unified modeling is achieved by employing a shared Transformer network and utilizing specific self-attention masks to control what context the prediction conditions on. We also propose a novel training procedure, referred to as a pseudo-masked language model, to effectively and efficiently pretrain different language modeling objectives in one forward pass. UniLM is the first unified pretrained model that shows strong results on both language understanding and generation benchmarks, creating a new state of the art on natural language benchmarks when it was introduced (opens in new tab) in addition to its competitive results on natural language tasks. The second version of the model, UniLMv2, outperformed other related models such as BERT, Google’s XLNet, and Facebook’s RoBERTa across SQuAD and GLUE at the time. Although Bing search technology was BERT-based early in 2019 (opens in new tab), we’ve moved it to UniLMv2 in 2020 for improved quality, and UniLMv2 has been incorporated into the Microsoft pretrained Turing language models.

Graph attention networks for machine reading comprehension
“Document Modeling with Graph Attention Networks for Multi-grained Machine Reading Comprehension”
The task of machine reading comprehension (MRC) is to find short answers, such as phrases, or long answers, such as paragraphs, from documents with respect to given questions. Because of the max length limitation, most existing MRC methods treat documents as separate paragraphs in the answer extraction procedure and don’t consider their internal relationship. To better model the documents for MRC, we propose a multi-grained machine reading comprehension framework where we first build a graph for each document based on its hierarchical nature—that is, documents, paragraphs, sentences, and tokens—and then use graph attention networks to learn different levels of representations. In this way, we can directly derive scores of long answers from its paragraph-level representations and obtain scores of short answers from the start and end positions on the token-level representations. Thus, both long and short answer extraction tasks can be trained jointly to promote each other. The model has been at the top of Google’s Natural Question leaderboard (opens in new tab) since its submission in February 2020 and is being used inside Bing for much of its question answering.
Multi-Task Deep Neural Networks
“Multi-Task Deep Neural Networks for Natural Language Understanding”
Multi-Task Deep Neural Network (MT-DNN), developed by Microsoft Research and Microsoft Dynamics 365 AI, is the first AI model that surpassed human performance on the GLUE leaderboard (opens in new tab), and it remained the best model on the leaderboard until December 2019, outperforming all competing models, including BERT, Google’s T5, and RoBERTa. MT-DNN combines multi-task learning and language model pretraining for learning language representations across multiple natural language understanding tasks. MT-DNN not only leverages large amounts of cross-task data, but it also benefits from a regularization effect that leads to more general representations to adapt to new tasks and domains. The models in semantic search are leveraging multi-task learning across various search tasks to maximize their quality.
MiniLM
MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers” (opens in new tab) (NeurIPS 2020)
Although large-scale Transformer-based models are powerful, they’re expensive for online serving in production settings. Microsoft Research has developed state-of-the-art task-agnostic knowledge distillation techniques to compress big pretrained Transformer-based models into small and fast ones for online serving while minimizing performance loss. MiniLM is a model compression method based on deep self-attention distillation, where a compressed (small) model is trained by deeply mimicking the self-attention module of a large model to be compressed. MiniLM achieves state-of-the-art results in small-model settings on both monolingual and multilingual natural language benchmarks. We’ve used MiniLM distillation for all the large models in our semantic search solutions; these large models retain 95 percent of the accuracy at only 20 percent of the cost.

Conclusion
The AI models behind semantic search are extremely powerful and have been validated both against external academic benchmarks and real user traffic on Bing. By bringing semantic search to Azure Cognitive Search, we’re taking a major step toward democratizing advanced machine learning technologies for everyone. Semantic search will deliver better experiences for your end users while also enabling anyone to tap into the power of AI at Scale using fewer resources and without specialized expertise. We believe semantic search on Azure Cognitive Search offers the best combination of search relevance, developer experience, and cloud service capabilities available on the market. Start using semantic search in your service today by signing up for the preview at aka.ms/semanticpreview (opens in new tab).
If you’re interested in applying the latest deep learning techniques to innovate in search, our Search and AI team is hiring globally (opens in new tab)!
Acknowledgments
This work in semantic search has been the result of companywide collaboration, including teams from Microsoft Research, Microsoft Azure, Microsoft Bing, and Azure Cognitive Search. Blog post authors Rangan Majumder, Alec Berntson, and Daxin Jiang are from Bing, while authors Jianfeng Gao, Furu Wei, and Nan Duan are from Microsoft Research.



