HEXA: Self-supervised pretraining with hard examples improves visual representations
| Chunyuan Li, Lei Zhang, and Jianfeng Gao
Humans perceive the world through observing a large number of visual scenes around us and then effectively generalizing—in other words, interpreting and identifying scenes they haven’t encountered before—without heavily relying on labeled annotations for every single scene. One of the…
VinVL: Advancing the state of the art for vision-language models
| Pengchuan Zhang, Lei Zhang, and Jianfeng Gao
Humans understand the world by perceiving and fusing information from multiple channels, such as images viewed by the eyes, voices heard by the ears, and other forms of sensory input. One of the core aspirations in AI is to develop…
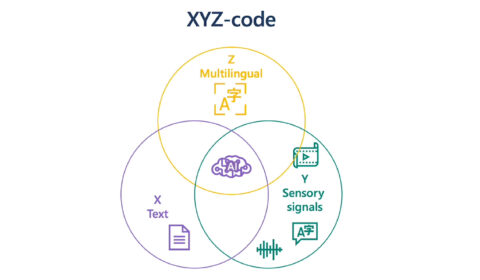
A holistic representation toward integrative AI
| Xuedong Huang
At Microsoft, we have been on a quest to advance AI beyond existing techniques, by taking a more holistic, human-centric approach to learning and understanding. As Chief Technology Officer of Azure AI Cognitive Services, I have been working with a…
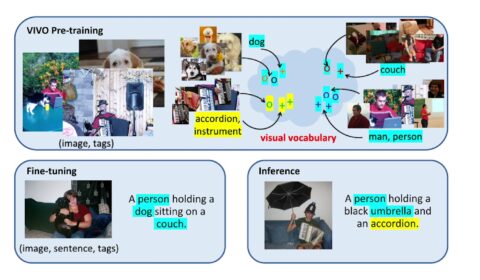
Novel object captioning surpasses human performance on benchmarks
| Kevin Lin, Xiaowei Hu, and Lijuan Wang
Consider for a moment what it takes to visually identify and describe something to another person. Now imagine that the other person can’t see the object or image, so every detail matters. How do you decide what information is important…

Enhancing your photos through artificial intelligence
The amount of visual data we accumulate around the world is mind boggling. However, not all the images are captured by high-end DSLR cameras, and very often they suffer from imperfections. It is of tremendous benefit to save those degraded…

Objects are the secret key to revealing the world between vision and language
| Chunyuan Li, Lei Zhang, and Jianfeng Gao
Humans perceive the world through many channels, such as images viewed by the eyes or voices heard by the ears. Though any individual channel might be incomplete or noisy, humans can naturally align and fuse the information collected from multiple…

Expanding scene and language understanding with large-scale pre-training and a unified architecture
| Hamid Palangi
Making sense of the world around us is a skill we as human beings begin to learn from an early age. Though there is still much to know about the process, we can see that people learn a lot, both…
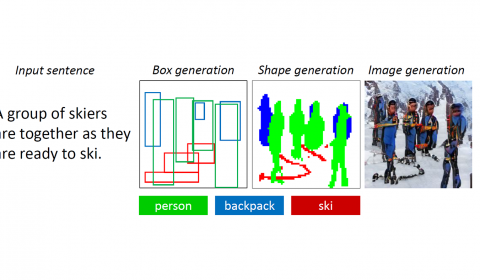
A picture from a dozen words – A drawing bot for realizing everyday scenes—and even stories
If you were asked to draw a picture of several people in ski gear, standing in the snow, chances are you’d start with an outline of three or four people reasonably positioned in the center of the canvas, then sketch…
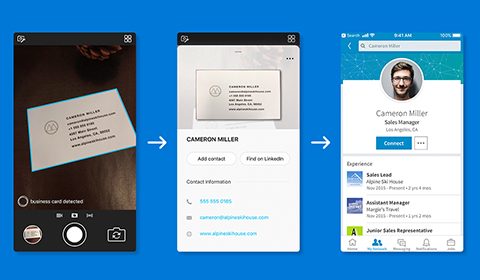
Microsoft Pix’s AI gets even smarter, Business Card feature works with LinkedIn to make it easier than ever to manage your contacts
Today's update from Microsoft debuts a new feature for its intelligent camera app, Microsoft Pix, that works with LinkedIn, showcasing the productivity capabilities of the AI-powered camera. The new Business Card feature for iPhones makes it quick and easy for…