

During World War II, Abraham Wald who was a statistician at Columbia University arrived at a very counterintuitive solution. He was tasked by the military to determine where to place armor on airplanes to increase their chances of surviving the mission [1]. The military research team and Abraham’s statistical group both analyzed the damaged portions of planes that returned from combat, paying special attention to the locations where bullet holes were found. The army suggested placing armor where planes were hit the most. Abraham disagreed. He suggested reinforcing the least damaged parts of the aircraft. As confusing as this might first sound, his suggestion was correct. The holes on the planes that came back were not as critical as the holes on the planes that crashed. In other words, the planes that never returned needed to be included in the analysis for its results to be trustworthy.
How does this story relate to A/B testing?
Just as Abraham Wald could not conduct a complete analysis of aircraft survival without considering those planes which did not return, so too do A/B testers need to be aware of missing users in their experiments. A/B tests often suffer from the same problem that Abraham recognized in his analysis – survivorship bias [2]. It manifests itself as a statistically significant difference between the ratio of users counted in variants A and B from what was configured before the experiment began (e.g. a 50/50 split). As we’ll see in a moment, performing analyses on such disproportional data can be harmful to the product it’s meant to support. To prevent that harm, at Microsoft, every A/B test must first pass this Sample Ratio Mismatch (SRM) test before being analyzed for its effects.
How Do SRMs Impact A/B Tests?
A team at MSN once tested a change on their image carousel [4]. They expected to see an increase in user engagement when the number of rotating cards was increased from 12 (A) to 16 (B). This A/B test had enough statistical power to detect very small changes and user interaction telemetry were correctly logged and collected. Despite the expectations that were grounded in related A/B tests, the results showed a decrease in engagement! This decrease, however, came with a warning saying that the number of users in variants A and B statistically differed from the configured ratio. The A/B test failed the SRM check and was examined further. An in-depth investigation revealed an interesting finding. Not only was version B more engaging – the users exposed to B engaged with it enough to confuse a bot detection algorithm which then filtered them out of the analysis.

The issue was resolved, and the results were flipped. The new variant was in fact positive, with the additional content significantly increasing user engagement with the product. At the same time, this example illustrates an important learning: missing users are rarely just some users. They are often the ones that were impacted the most by what was being tested. In the MSN example, these were the most engaged users. In another A/B test with an SRM, the data from the least engaged users could be missing. In short, one of the biggest drivers of incorrect conclusions when comparing two datasets is the comparison of disproportionate datasets. Don’t trust the results of A/B tests with an SRM until you diagnose the root cause.
How widespread are SRMs and why do they happen?
Recent research contributions from companies such as LinkedIn [3] and Yahoo, as well as our own research [4] confirm that SRMs happen relatively frequently. How frequently? At LinkedIn, about 10% of their zoomed-in A/B tests (A/B tests that trigger users in the analysis if they satisfy some condition) used to suffer from this bias. At Microsoft, a recent analysis showed that about 6% of A/B tests have an SRM [4]. Clearly, this is an important problem worth understanding, so we investigated the diverse ways that SRMs can happen.
Just like fever is a symptom for multiple types of illness, an SRM is a symptom for a variety of quality issues. This makes diagnosing an SRM an incredibly challenging task for any A/B tester. In Diagnosing Sample Ratio Mismatch KDD’19 paper [4], we derived a taxonomy for distinct types of SRMs. This knowledge unpacks the common root causes for an SRM at each of the stages of an A/B test. We discovered several causes for an SRM that happen in the Assignment stage (such as incorrect bucketing of users, faulty User IDs, carry over effects, etc.), causes that happen in the Execution stage (such as redirecting users in one variant, variant changing engagement, etc.), in the Log Processing stage (e.g. incorrect data joins), and finally in the Analysis Stage (e.g. using biased conditions to segment the analysis). Orthogonal to the stages, SRMs can also be caused at any time by A/B testers by simply ramping up the experiment variants unevenly or by making it too easy for users to self-assign into a variant. For a comprehensive taxonomy, see the figure below or read our report [4].

The taxonomy creates an understanding of the problem, but it does not answer the key question of how to know what’s biasing a given A/B test. Let’s investigate this next.
How to diagnose SRMs?
Diagnosing an SRM happens in two steps. Step one is detection – testing if an A/B test has an SRM. Step two is a differential diagnosis – synthesizing the symptoms and excluding root-causes that seem unlikely based on the evidence.
Does my A/B test have an SRM?
A fundamental component of every mature A/B testing platform is an integrated SRM test that prominently notifies A/B testers about a mismatch in their datasets [5], [6]. If an A/B testing platform lacks this feature, a browser extension or other method may be available to compute an SRM test, see [7].
The SRM test is performed on the underlying data i.e. counts of users that reported using A and B, before the ship-decision analysis is started. We like to think of it as an end-to-end method for detecting A/B tests that suffer from severe quality issues and need attention. Contrary to intuition, it is not sufficient to glance only at the ratio of users in A vs. B. The ratio lacks information about the sample size. We need to use a statistical test such as a chi-square statistic to determine whether the observed distribution of users in experiment variants statistically differs from the one that was configured.
As we mention above, every analysis that is part of an ongoing A/B test using ExP first needs to pass this test before we reveal the actual results of the experiment. The threshold that we use is conservative to reduce the likelihood of false positives: p-value < 0.0005. In practice, A/B tests with an SRM will result in a p-value that is much lower than the threshold. Now let’s discuss how to triage an SRM.
Finding the SRM root cause
In medicine, a differential diagnosis is the distinguishing of a particular disease or condition from others that present similar clinical features [8]. We follow a similar practice to diagnose SRMs. How? We share two common steps that we take in most of our SRM root-cause investigations. We describe the tooling that we developed to ease the investigation in the next section.
Segments. A common starting point is to analyze segments (aka cohorts). Oftentimes, an SRM root-cause is localized to a particular segment. When this is the case, the segments that are impacted will have an incredibly low p-value, prompting the A/B test owners to dive deeper. Consider for example a scenario in which one of the variants in an A/B test significantly improves web site load time for users that open it by using a particular browser. Faster load times can impact the rate at which telemetry is logged and collected. As a result, this A/B test might have an SRM that is localized to that browser type. Other segments, however, will likely be clean and useful for the analysis. Now how about when the segment evidence is inconclusive and e.g. all segments seem to be similarly impacted with an SRM?
Triggering. For A/B tests that are analyzed on a subset of the assigned population – a triggered A/B analysis [9], we recommend examining the boolean condition that was used to decide which logs to keep. Commonly, A/B testers will create a triggered analysis to increase the sensitivity of their metrics. For example, if a change on a checkout page such as a new coupon code field is introduced, it might be valuable to analyze only the users that actually visited this page. However, to zoom in, a valid condition – one that captures the experience of the users before the change being tested – needs to be used. Oftentimes the necessary logging for the provided condition is not present in every variant. Consider if the change in the checkout website example above was a new coupon code field and the condition was zooming-in to users that were exposed to this new field. What would happen in the analysis? Unless the counterfactual logging was added to the control variant that does not have this new field, there would be a severe SRM in favor of the treatment [10]. A simple diagnostic test for confirming such a bad condition is to examine whether the untriggered population in the A/B test does not have an SRM. Whenever the untriggered analysis for a given A/B test is trustworthy and the triggered analysis has an SRM, a misconfigured triggered condition or the lack of logging for the configured condition are the most likely root cause. The solution is often simple: updating the triggered condition so it includes all aspects that could affect a user (e.g. to a condition that is triggering to users that visited the sub-site as opposed to users that interacted with a component on that sub-site).
Of course, there are several other diagnostic steps that can be taken to collect more evidence. Some other data-points that help A/B testers diagnose their SRMs are the significance of the SRM (a very low p-value indicates a very severe root cause), the directionality of the SRM (more users in the new variant compared to the expected baseline often indicates increased engagement or better performance), and of course the count of SRMs (many distinct SRMs in a product at the same time could point to a data pipeline issue).
What tools help with the diagnosis?
At ExP, we have developed a tool that helps diagnose SRMs for common root causes discussed above. Our tool displays the most relevant information that it can collect and compute for a given A/B analysis. Users of the tool are given progressive experience, starting with an explanation of what an SRM is, followed by a series of automated and manual checks. The automated checks help A/B testers in answering the following three questions for any A/B analysis with an SRM:
- Is the SRM localized to some segments or widespread?
- Was the SRM caused by the configured boolean condition for triggering?
- Has the SRM root-cause been present from the beginning of an A/B test?
We discuss how we answer the first two questions in the remainder of this blog post and save the answer to the third question for the next one.
Is the SRM localized to some segments or widespread?
First, to give A/B testers an insight on whether their SRMs are localized or widespread, we provide them with an intuitive visualization where all available segments are illustrated as cells. Red cells illustrate an SRM while gray cells illustrate that an SRM was not detected for that segment. The size of the cell is proportional to the size of the segment – large cells point to large segments and vice versa. Users of this visualization can also filter the view based on the SRM p-value (from exceedingly small p-value to borderline SRM-p-value to all p-values) and segment size (with respect to all data). The goal, as described above, is to find whether SRM has been detected only in some segments, and whether they are large enough to skew the overall analysis.
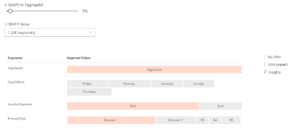
Was the SRM caused by the configured condition?
For A/B analysis that are zoomed-in to a sub-population, we provide diagnostic information on whether the condition for zooming-in is the root-cause. As described above, we do this by displaying a matching analysis that did not use this condition for the given A/B test. Whenever this standard analysis is without an SRM, we ask the diagnostician to debug the condition that was used to produce the analysis.

In addition to the checks described above, we also developed a check that uses historical data from an experiment to help determine at what time the SRM root cause occurred. We will share more details about this feature in an upcoming blogpost. Automated checks, however, might not always suffice.
Our tool also provides diagnosticians with a Q&A analysis feature where strategic questions about A/B test variants are asked (e.g. “do only some of the variants redirect traffic”) and simple yes/no/maybe answers are possible. Based on the answers to these questions, diagnosticians are guided to explanations and case studies from the taxonomy to learn about the paths that lead to an SRM whenever one of their variants behaves as the questions asks.
Our mission at ExP is to provide trustworthy online controlled experimentation. Sample Ratio Mismatch is a significant pitfall that needs to be detected, diagnosed, and resolved before the results of an A/B test can be trusted. We hope that our learnings are an insightful introduction to this topic, and that you always check and diagnose SRMs. Think of Abraham Wald and the missing planes the next time you analyze an A/B test.
– Aleksander Fabijan, Trevor Blanarik, Max Caughron, Kewei Chen, Ruhan Zhang, Adam Gustafson, Venkata Kavitha Budumuri, Stephen Hunt, Microsoft Experimentation Platform
References
[1] A. Wald, “A method of estimating plane vulnerability based on damage of survivors, CRC 432, July 1980,” Cent. Nav. Anal., 1980.
[2] “Survivorship bias.” [Online]. Available: https://en.wikipedia.org/wiki/Survivorship_bias.
[3] N. Chen and M. Liu, “Automatic Detection and Diagnosis of Biased Online Experiments.”
[4] A. Fabijan et al., “Diagnosing Sample Ratio Mismatch in Online Controlled Experiments,” in Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining – KDD ’19, 2019, pp. 2156–2164.
[5] S. Gupta, L. Ulanova, S. Bhardwaj, P. Dmitriev, P. Raff, and A. Fabijan, “The Anatomy of a Large-Scale Experimentation Platform,” in 2018 IEEE International Conference on Software Architecture (ICSA), 2018, no. May, pp. 1–109.
[6] A. Fabijan, P. Dmitriev, H. H. Olsson, and J. Bosch, “Effective Online Experiment Analysis at Large Scale,” in Proceedings of the 2018 44rd Euromicro Conference on Software Engineering and Advanced Applications (SEAA), 2018.
[7] L. Vermeer, “Sample Ratio Mismatch (SRM) Checker.” [Online]. Available: https://github.com/lukasvermeer/srm.
[8] “Differential Diagnosis.” [Online]. Available: https://en.wikipedia.org/wiki/Differential_diagnosis.
[9] R. Kohavi, D. Tang, and Y. Xu, Trustworthy Online Controlled Experiments: A Practical Guide to A/B Testing. Cambridge University Press.
[10] W. Machmouchi, “Patterns of Trustworthy Experimentation: Pre-Experiment Stage,” 2020. [Online]. Available: https://www.microsoft.com/en-us/research/group/experimentation-platform-exp/articles/patterns-of-trustworthy-experimentation-pre-experiment-stage/.
[11] T. Xia, S. Bhardwaj, P. Dmitriev, and A. Fabijan, “Safe Velocity: A Practical Guide to Software Deployment at Scale using Controlled Rollout,” in 2019 IEEE/ACM 41st International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP), 2019, pp. 11–20.