

Machine Teaching Group
Machine teaching seeks to gain knowledge from people rather than extracting knowledge from data alone. Any information processing skill that is teachable to a human, should be easily teachable to a machine.
Think about a business process that involves getting information out of unformatted text, such as email or other documents, such as determining how many of a certain product had been quoted to each customer last year? That might involve combing through documents, knowing that particular documents are quote documents and what part of the text includes the part being quoted and includes the customer name. Those are not difficult tasks for a human to learn, but today they can be difficult to automate because they’re customized to a specific business’s industry and document formats.
Our research is focused on teaching machines to do these types of specialized tasks in a way that is easy, fast, and accessible to people without machine learning expertise.
Traditional machine learning requires volumes of labeled data that can be time consuming and expensive to produce. Machine teaching leverages the human capability to decompose and explain concepts to train machine leaning models, which is much more efficient than using labels alone. With the human teacher and the machine learning model working together in a real-time interactive process, we can dramatically speed up model-building time.
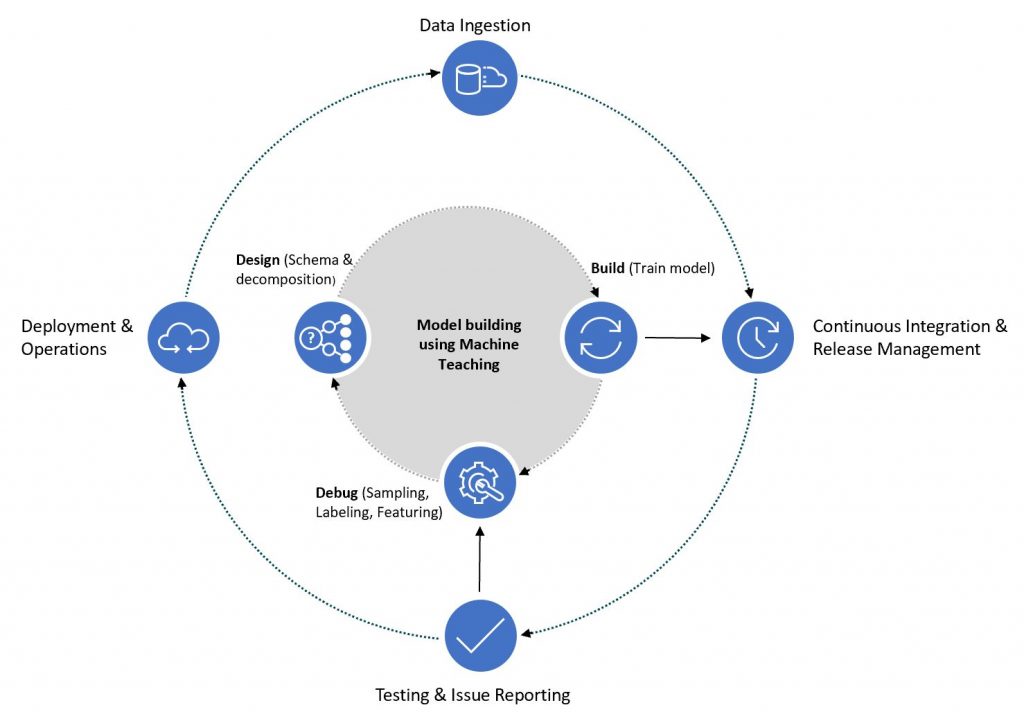
Machine teaching process
We work on making the process of building, debugging, and using ML models more efficient. We design our tools for the end-to-end development cycle, knowing that custom models must be deployed and maintained to serve their ultimate purpose. Our projects and products, such as PICL (opens in new tab) and LUIS (opens in new tab), are designed to be frictionless and enable people without data science knowledge to leverage the power of machine learning through machine teaching.
Try Machine Teaching with Language Understanding (LUIS) > (opens in new tab)
Benefits of machine teaching
Data science expertise not required
Machine teaching abstracts the information used to teach the machine away from the algorithm used to train the model. By separating the teaching information from the algorithm, we can allow the algorithms and the teaching language to innovate independently and the teacher doesn’t need to understand machine learning algorithms.
Build custom models fast
Because machine teaching leverages information from the teacher in addition to labels, we can build models with fewer labels than traditional methods. Labeling examples is part of the data exploration and debugging process and not a rote task; it’s quick and easy to start with no labeled data. A single subject matter expert can quickly build an effective model without armies of labelers.
Easily updateable model
Decomposition enables easier debugging. Our tools are built with the end-to-end development cycle in mind. When failures are found in production, they can be quickly added to the labeled data and new features can be added to address changes in the concept.
Share and reuse
Decomposition allows us to leverage work done by others and build on it. If someone has built models to recognize part numbers and prices, they could all be used as inputs to a model that is used to extract bills of materials. Those same models might also be useful in classifying documents as sales receipts. We can reuse and customize existing models to fit specific problems.