

The Conference on Computer Vision and Pattern Recognition (CVPR) is regarded as the premier conference in computer vision and pattern recognition. CVPR 2022, held on June 19-23, received a record number of 8,161 full submissions that went into the review process. The program committee recommended 2,067 papers to be accepted, resulting in an acceptance rate of 25.33%. In this article, we have selected eight of the accepted paper submissions from Microsoft Research Asia to introduce some of the hottest research trends in computer vision.
Neural Compression-Based Feature Learning for Video Restoration

Paper link: https://arxiv.org/abs/2203.09208 (opens in new tab)
Video restoration tasks rely heavily on temporal features to achieve better reconstruction quality. Existing video restoration methods mainly focus on network structure design to better extract temporal features, such as bidirectional propagation. However, what’s often overlooked is how to effectively use temporal features and fuse them with the current frame. In reality, temporal features usually contain a great amount of noise and irrelevant information, and directly using them without feature refinement would interfere with the restoration of the current frame.
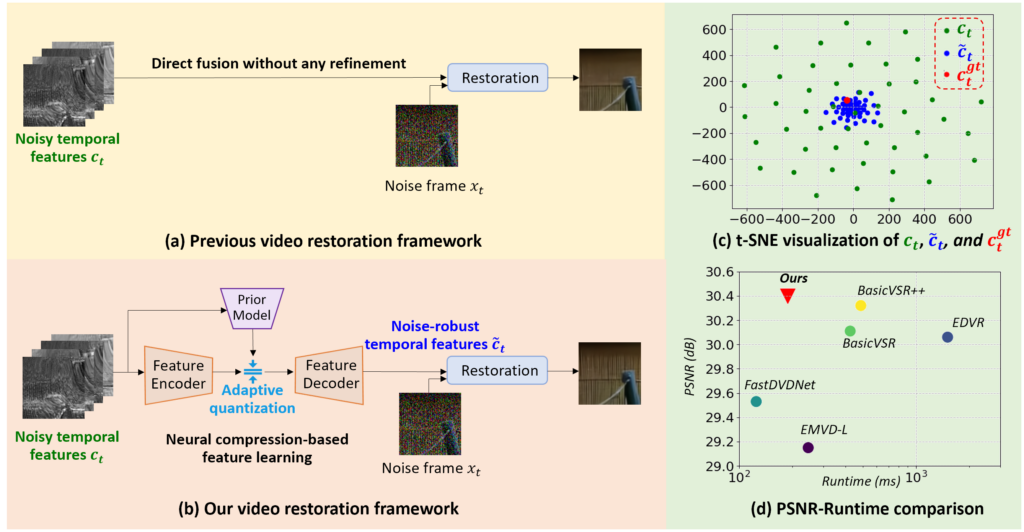
To this end, the researchers proposed a neural compression-based module to learn efficient temporal feature representations. Because neural compression discards irrelevant information and noise in order to save bits, it is a natural denoiser, and so researchers employed this method to effectively filter out noise and preserve the most important temporal information. As shown in Figure 1(b), the researchers used neural compression to refine the temporal features before the feature fusion. To achieve robustness against noise, the researchers proposed an adaptive and learnable quantization mechanism for the compression module to efficiently handle different content types. During the training process, the cross-entropy loss function and the reconstruction loss function guided the learning of the whole model.
Figure 1(c) shows that the features learned by this method are more robust against noise and more closely resemble the features from a clean video. Experiments show that neural compression-based feature learning has helped this method achieve best performances in multiple video restoration tasks, including video denoising, video deraining, and video dehazing. For video denoising in particular, this method obtained an improvement of 0.13 dB over BasicVSR++ with only 0.23x FLOPs.
GRAM: Generative Radiance Manifolds for 3D-Aware Image Generation

Paper link: https://yudeng.github.io/GRAM/ (opens in new tab)
Traditional 2D image GAN models can generate high-fidelity virtual images that are sometimes hard to distinguish from real ones. However, the generation process does not consider the 3D geometry of the objects to be generated and they cannot generate the images of the same instance from different viewpoints. Recently, 3D-aware image GANs have begun to emerge, and they are trained to synthesize geometrically consistent multiview imagery of novel instances. The key to achieving this is to generate an underlying 3D representation, for which the most advanced methods employ neural radiance fields (NeRF).
Despite the promising results shown by recent 3D image GANs, their image generation quality still lags far behind traditional 2D GANs. A critical reason for this is that the high memory and computation cost of NeRF representation learning greatly restricts the number of point samples that can be used in radiance integration for ray rendering. Deficient point sampling not only limits the expressive power of the generator to handle fine geometry details but also impedes effective GAN training due to the noise caused by unstable Monte Carlo sampling.
The researchers proposed a novel approach named Generative Radiance Manifolds (GRAM), which regulates point sampling and radiance field learning on 2D manifolds embodied as a set of learned implicit surfaces in the 3D volume. The radiance manifold representation greatly facilitates fine detail learning and is free from the noise patterns caused by inadequate Monte Carlo sampling. Experiments conducted on multiple datasets show that this method can generate high-quality images with strong multiview consistency that significantly outperforms prior methods.

StyleSwin: Transformer-based GAN for High-resolution Image Generation

Image generative modeling has seen dramatic advancement in recent years, and generative adversarial networks (GANs) offer arguably the most compelling results when synthesizing high-resolution images. While early attempts have focused on stabilizing training dynamics, remarkable performance leaps in prominent recent work can be mainly attributed to the architectural modifications that have been made to realize stronger modeling capacity. These modifications include adopting self-attention, scaling up to large models, or employing style-based generators.
Recently, Transformer has gained significant attention and achieved great success in a series of discriminative tasks. Taking inspiration from this, researchers at Microsoft Research Asia have attempted to use pure transformers to build a generative adversarial network for high-resolution image synthesis based on theirstrong capability in long-range dependency modeling. To tame the quadratic computational cost so that the network is scalable to high resolutions, the researchers adopted Swin Transformer, which was proposed by Microsoft, as a basic building block to strike a balance between computational efficiency and modeling capacity.
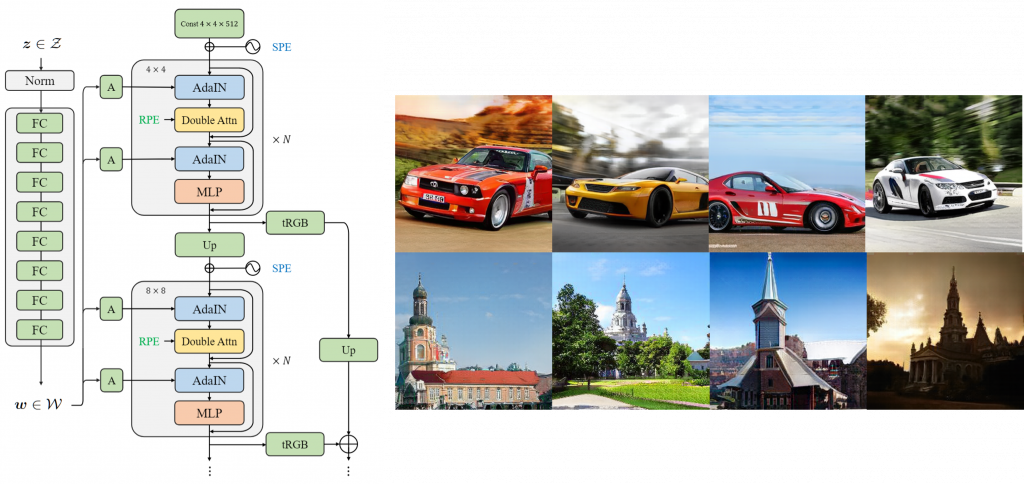
The researchers further proposed several improvements to better adapt Swin Transformer to the image generation task. First, they adopted a style-based structure for the generator and explored several style injection mechanisms suitable for Transformer blocks. Second, they proposed replacing overlapping windows in Swin Transformer with double attention, allowing each layer of the Transformer module to have a larger attention span. Further, the researchers pointed out that for generative models, it is necessary to use both relative position encoding and absolute position encoding.
More importantly, the researchers discovered that computing self-attention within the local window could generate blocking artifacts similar to JPEG compression. This issue is only noticeable in generative tasks. To this end, they proposed using a discriminator model based on wavelet transformation to identify these blocking artifacts in the frequency domain, effectively improving the quality of generated images under human perception.
StyleSwin, as proposed in this paper, achieves competitive generation quality on several datasets such as FFHQ, CelebA-HQ, LSUN Church, and LSUN Car. At 256×256 resolution, StyleSwin surpasses all existing GAN approaches. StyleSwin also achieves image quality comparable to StyleGAN2 at 1024×1024 resolution. The significance of this paper is to validate the effectiveness of the Transformer model in high-resolution, high-quality image generation tasks for the first time, and to shed new light on the development of the generative network backbone.
Vector Quantized Diffusion Model for Text-to-Image Synthesis

Paper link: https://arxiv.org/abs/2111.14822 (opens in new tab)
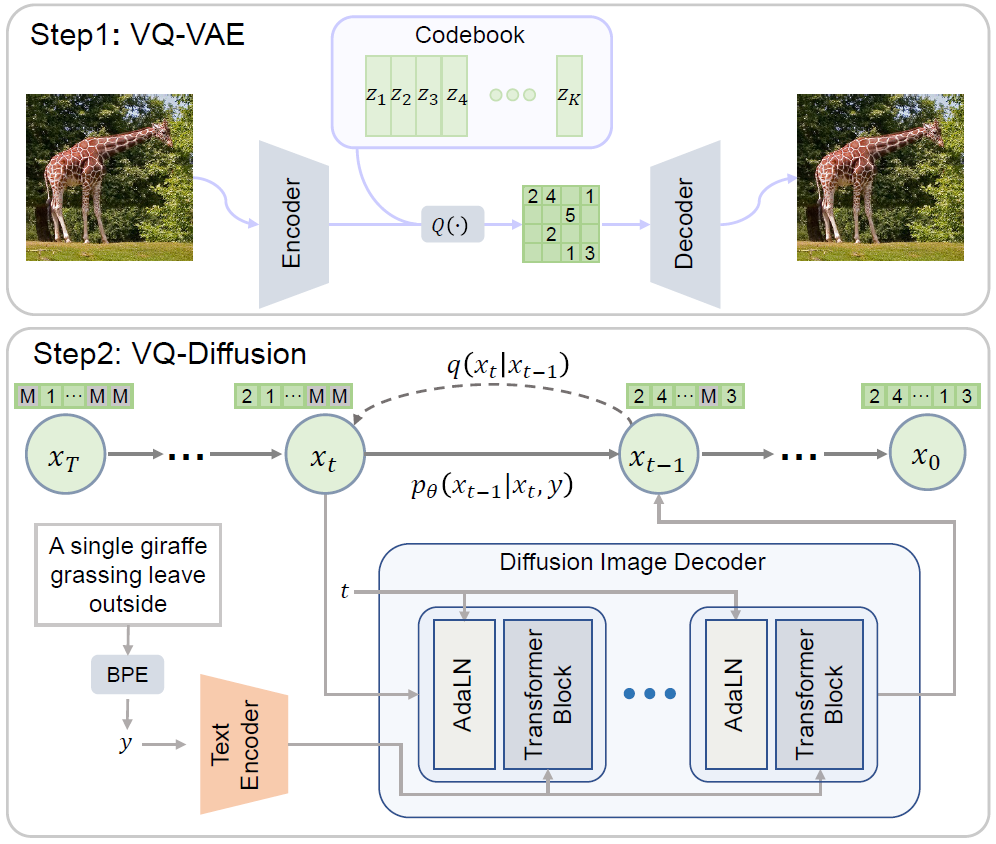
Text-to-image synthesizing has raised tremendous interest among researchers in recent years. Previous work can be mainly divided into two categories: Generative adversarial networks (GANs) and autoregressive models (ARs). Generative adversarial networks are limited by their fitting capability and often can only fit images of a single scene or category. The autoregressive model, meanwhile, transforms the image generation problem into a serialization generation problem but suffers from unidirectional bias and error accumulation issues. It is also very time consuming in generating images. This paper proposes a new generative model, the vector quantized denoising diffusion model (VQ-Diffusion), which can effectively address the above problems. Specifically, this method first adopts a vector quantized variational autoencoder (VQVAE) to encode an image into discrete codes, and then uses a conditional denoising diffusion model (DDPM) to model the distribution of the latent space.
Unlike with diffusion models in continuous space, in order to fit the discrete data distribution, the researchers leveraged the probability transition matrix instead of Gaussian noise to add noise to the target distribution in the diffusion step. To be specific, a novel mask-and-replace diffusion strategy is proposed that can successfully avoid the error accumulation issue. Furthermore, by exploiting a bidirectional attention mechanism in the denoising step, this method avoids the problem of unidirectional bias. This paper also proposes a reparameterization trick for the discrete diffusion model, which can effectively balance generation speed and image quality. The framework for VQ-Diffusion is shown in Figure 4.
To assess the performance of VQ-Diffusion, researchers conducted text-to-image generation experiments on a variety of datasets, including CUB-200, Oxford-102, and MSCOCO. Compared with the AR model that has similar model parameters, VQ-Diffusion can obtain better generation results and is 15 times faster. Compared with previous GAN-based text-to-image generation methods, VQ-Diffusion can handle more complex scenes and improves synthesized image quality by a large margin. Furthermore, this method is general and produces strong results in both unconditional and conditional image generation with FFHQ and ImageNet datasets.
A Simple Multi-Modality Transfer Learning Baseline for Sign Language Translation

Paper link: https://arxiv.org/abs/2203.04287 (opens in new tab)
Studying sign language translation can help bridge communications with those who are deaf, leading to a more inclusive society. This paper presents a simple multi-modal transfer learning baseline for sign language translation.
Typically, neural sign language translation follows the framework of neural machine translation and employs an encoded-decoder architecture to translate visual features into spoken text. However, compared with NMT, SLT suffers from data scarcity, that is, a shortage of parallel video-text data. To address this problem, researchers proposed to progressively pre-train the model from general-domain datasets to within-domain datasets. By transferring supervisions from existing datasets, the researchers hoped that the necessity for gathering large parallel data would be lessened.
The researchers decomposed SLT into Sign2Gloss and Gloss2Text using gloss annotations so that visual and language modules could be pre-trained on two domains separately.
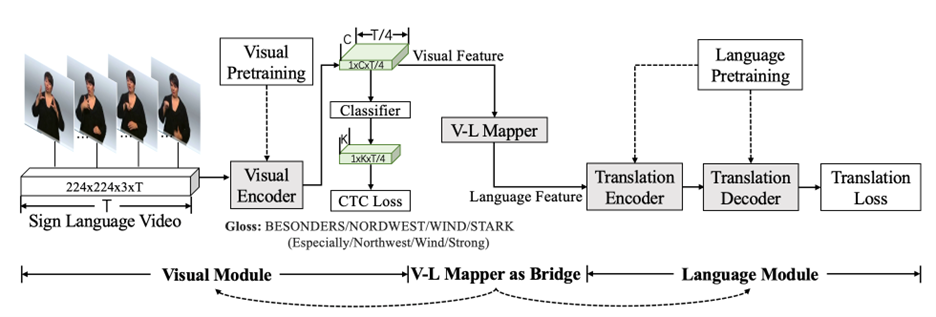
This network consists of a visual module that extracts features from input videos, a language module that translates the feature into spoken text, and a V-L mapper that bridges these two modules to enable multi-modal joint training. For the visual module, the researchers first pre-trained the S3D backbone on general domains of Kinetics-400, a human action recognition dataset, and WLASL, an isolated American sign language recognition dataset. Then, the researchers trained the visual encoder on the within-domain task of Sign2Gloss using CTC loss. For the language module, the researchers used multilingual-BART initialization, which is pre-trained on a large-scale spoken text corpus. Then, researchers applied within-domain pre-training on Gloss2Text translation using cross-entropy loss. Finally, the researchers introduced a V-L mapper, which is a two-layer MLP that projects the visual feature into the input of the translation network. By doing so, the two pre-trained modules are connected via dense visual features rather than discrete gloss representation. The whole network can then be jointly trained under the supervision of both CTC loss and translation loss.
This simple baseline surpasses all previous work by large margins on Phoenix and CSL-Daily, two SLT benchmarks for German and Chinese sign languages. The researchers also conducted a variety of ablation studies to demonstrate the effectiveness of this transfer learning strategy.
Rethinking Minimal Sufficient Representation in Contrastive Learning

Paper link: https://arxiv.org/abs/2203.07004 (opens in new tab)
Contrastive learning has been widely used in video and image pre-training in recent years. As a self-supervised method, contrastive learning seeks to learn information on data under the mutual supervision of different views. The learned representation therefore only contains the shared information between views and excludes their non-shared information. In other words, contrastive learning learns the minimal sufficient representation of different views. This brings about a question: Is it possible that the excluded non-shared information could also contain useful information for downstream tasks, or in other words is task-relevant? As the generation of views highly depends on data augmentation methods, and the information of downstream tasks is always absent in the pre-training stage, the answer to this question is affirmative.
Researchers from MSR Asia approached this problem from an information theory perspective and, through rigorous reasoning proof, found that the non-shared information excluded by minimal sufficient representation does contain task-relevant information, which shows that contrastive learning runs the risk of over-fitting to the shared-information between different views. This would decrease the generalization ability of the pre-training model, as well as the performance of downstream tasks. To solve this problem, the researchers proposed enabling contrastive learning to learn sufficient representation instead of minimal sufficient representation by increasing the mutual information of the views. This way, task-relevant non-shared information could also be learned. For this purpose, the researchers proposed two generic pre-training strategies. One is to introduce more of the data’s original information by using reconstruction tasks; the other is to compute the lower bound of the mutual information by adding corresponding regularization. Extensive experiments show that these proposed pre-training strategies can significantly improve the performance of downstream tasks, including detection and segmentation.

SimMIM: A Simple Framework for Masked Image Modeling

Paper link: https://arxiv.org/abs/2111.09886 (opens in new tab)
Code link: https://github.com/microsoft/SimMIM (opens in new tab)
Masked Signal Modeling is a pre-training method that predicts invisible information by using partially visible information. Its application in the field of Natural language Processing (NLP), Masked Language Modeling (MLM), has become the most representative and widely used pre-training method in the field of NLP.
In computer vision, a series of attempts to use Masked Image Modeling (MIM) for vision model pre-training have also emerged, but previous approaches have often required additional designs.
In this paper, the researchers proposed a simple pre-training framework, SimMIM, that uses only a simple random masking strategy and a single-layer linear decoder to reconstruct the original image content. Figure 7 illustrates the algorithm. The researchers demonstrated that this simple approach can learn high-quality image representations.
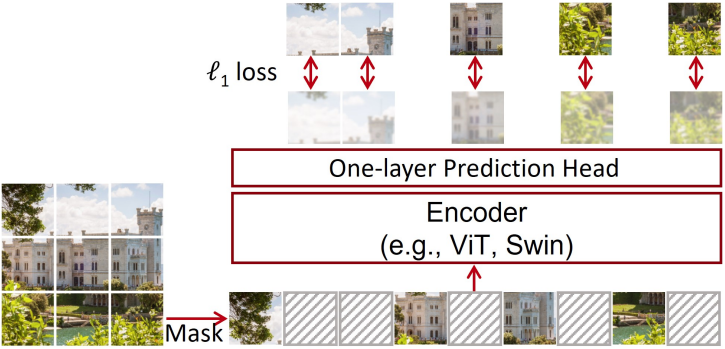
SimMIM can be used in different network architectures, including ViT, Swin and ConvNets, and has achieved better fine-tuning performance on ViT-B than other pre-training methods and with lower cost. Results are shown in Figure 8 (Left).
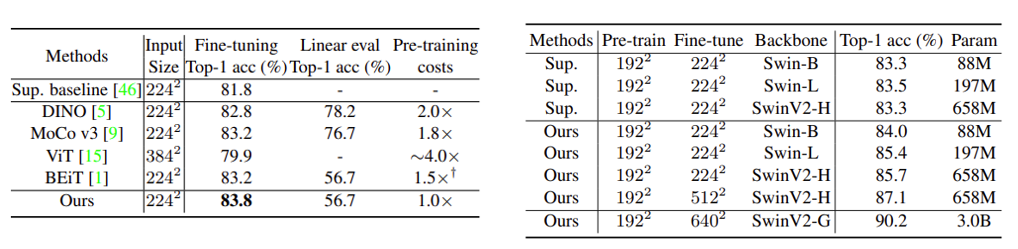
Figure 8 (Right) shows that this method achieves better performance than supervised pre-training on Swin Transformer. In addition, this method has larger advantages on larger models, indicating that the method is a model scalable learner. By using SimMIM, Swin-G with 3B parameters achieved Top-1 Acc with 90.2% on the ImageNet-1K image classification task.
SimMIM is not only applicable to transformer networks but is also effective for ConvNets. On ResNet-50×4, SimMIM achieved Top-1 Acc with 81.6%, which is higher than 80.7% obtained by supervised pre-training. These experiments demonstrate the broad applicability of SimMIM.
Learning Trajectory-Aware Transformer for Video Super-Resolution

Paper link : https://arxiv.org/abs/2204.04216 (opens in new tab)
Paper link: https://github.com/researchmm/TTVSR (opens in new tab)
Video super-resolution (VSR) aims to restore a sequence of high-resolution (HR) frames from their low-resolution (LR) counterparts. Although some progress has been made in this area, there are still great challenges to effectively utilize temporal dependency in entire video sequences. Existing approaches usually align and aggregate video frames from limited adjacent frames (e.g., 5 or 7 frames), which prevents these approaches from achieving satisfactory results.
This paper proposes a novel Trajectory-Aware Transformer for Video Super-Resolution (TTVSR), which takes effective spatio-temporal learning in videos one step further by introducing motion trajectories. Specifically, TTVSR assigns video frames to several pre-aligned trajectories that consist of continuous visual tokens. For a query token, self-attention is only learned on relevant visual tokens along spatio-temporal trajectories. To implement the trajectory modeling, the researchers proposed a location map mechanism, which models the trajectory of the visual features by performing a motion transformation on the predefined coordinate location maps. Compared with vanilla vision Transformers, which performs self-attention in the whole space-time, such a design significantly reduces computational cost and enables Transformers to model long-range features.
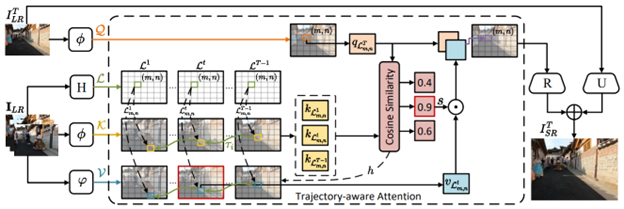
This paper further proposes a cross-scale feature tokenization module to overcome scale-changing problems that often occur in long-range videos. Experimental results demonstrate the superiority of the proposed TTVSR over state-of-the-art models through extensive quantitative and qualitative evaluations on four widely used video super-resolution benchmarks. Both the codes and the pre-trained models can be downloaded at: researchmm/TTVSR: [CVPR’22 Oral] TTVSR: Learning Trajectory-Aware Transformer for Video Super-Resolution (github.com) (opens in new tab)