

The training of FastSpeech relies on an autoregressive teacher model to provide the duration of each phoneme to train a duration predictor, and also provide the generated mel-spectrograms for knowledge distillation. Although FastSpeech can generate mel-spectrograms with extremely fast speed and improved robustness and controllability, and can achieve comparable voice quality with previous autoregressive models, there are still some disadvantages to it:
1) The two-stage teacher-student distillation pipeline is complicated;
2) The duration extracted from the attention map of the teacher model is not accurate enough, and the target mel-spectrograms distilled from the teacher model suffer from information loss due to data simplification, both of which limit the voice quality and prosody.
To address the issues in FastSpeech, researchers from Microsoft and Zhejiang University proposed FastSpeech 2 (accepted by ICLR 2021):
1) To simplify the two-stage teacher-student training pipeline and avoid information loss due to data simplification, we directly trained the FastSpeech 2 model with a ground-truth target instead of the simplified output from a teacher.
2) To reduce the information gap between the input (text sequence) and target output (mel-spectrograms), we introduced certain variation information of speech including pitch, energy, and more accurate duration to FastSpeech: in training, we extracted the duration, pitch, and energy from the target speech waveform and directly took them as conditional inputs; during inference, we used values predicted by the predictors that were jointly trained with the FastSpeech 2 model.
3) To further simplify the speech synthesis pipeline, we introduced FastSpeech 2s, which abandons mel-spectrograms as an intermediate output completely and directly generates speech waveform from text during inference, enjoying the benefit of full end-to-end joint optimization in training and low latency in inference.
Experiments on the LJSpeech dataset show that 1) FastSpeech 2 outperforms FastSpeech in voice quality and enjoys a much simpler training pipeline (3x training time reduction) while inheriting its advantages of being fast, robust and controllable (even more controllable in pitch and energy) speech synthesis; and 2) both FastSpeech 2 and 2s match the voice quality of autoregressive models and enjoy much faster inference speed.
Further details for FastSpeech 2 can be found in our paper: https://arxiv.org/pdf/2006.04558.pdf (opens in new tab) and the demo: https://speechresearch.github.io/fastspeech2/ (opens in new tab).
Model Overview
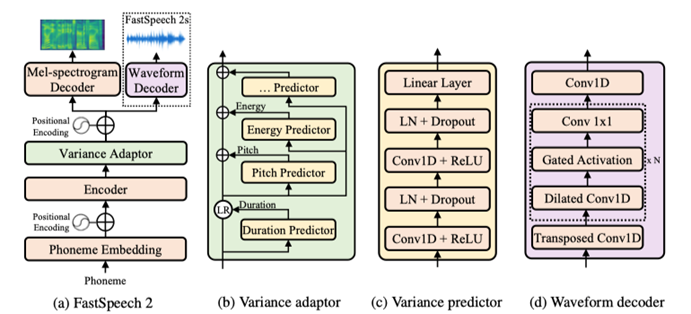
Figure 1: The overall architecture for FastSpeech 2 and 2s. LR in subfigure (b) denotes the length regulator operation proposed in FastSpeech. LN in subfigure (c) denotes layer normalization. Variance predictor represents duration/pitch/energy predictor.
Architecture
The overall model architecture of FastSpeech 2 is shown in Figure 1(a). It follows the Feed-Forward Transformer (FFT) architecture proposed in FastSpeech and introduces a variance adaptor between the phoneme encoder and the mel-spectrogram decoder, which adds different variance information such as duration, pitch, and energy into the hidden sequence to ease the one-to-many mapping problem (FastSpeech alleviates the one-to-many mapping problem by knowledge distillation which leads to information loss. FastSpeech 2 improves the duration accuracy and introduces more variance information to reduce the information gap between input and output to ease the one-to-many mapping problem.)
Variance Adaptor
As shown in Figure 1(b), the variance adaptor consists of 1) duration predictor, 2) pitch predictor, and 3) energy predictor. During training, we took the ground-truth value of the duration, pitch, and energy extracted from the recordings as input into the hidden sequence to predict the target speech. At the same time, we used separate variance predictors for duration, pitch, and energy predictions, which were used during inference to synthesize target speech. Instead of extracting the phoneme duration using a pre-trained autoregressive TTS model in FastSpeech, we extracted the phoneme duration with MFA (an open source text-to-audio alignment toolkit).
As shown in Figure 1(c), the duration/pitch/energy predictor consists of a 2-layer 1D-convolutional network with ReLU activation, each followed by layer normalization and dropout, and an extra linear layer to project the hidden states into the output sequence. For the duration predictor, the output is the length of each phoneme in the logarithmic domain. For the pitch predictor, the output sequence is the frame-level fundamental frequency sequence ($F_0$). For the energy predictor, the output is a sequence of the energy of each mel-spectrogram frame.
FastSpeech 2s
Based on FastSpeech 2, we proposed FastSpeech 2s to fully enable end-to-end training and inference in text-to-waveform generation. As shown in Figure 1(d), FastSpeech 2s introduces a waveform decoder, which takes the hidden sequence of the variance adaptor as input and directly generates waveform. During training, we kept the mel-spectrogram decoder to help with the text feature extraction. In inference, we discarded the mel-spectrogram decoder and only used the waveform decoder to synthesize speech audio.
Experiment Results
We first evaluated the audio quality, training, and inference speedup of FastSpeech 2 and 2s, and then we conducted analyses and ablation studies of our method.
Audio Quality
We evaluated FastSpeech 2 on the LJSpeech dataset, which contains 13,100 English audio clips (about 24 hours) and corresponding text transcripts. We performed a mean opinion score (MOS) evaluation on the test set. We compared the MOS of the audio samples generated by FastSpeech 2 and FastSpeech 2s with other systems, including 1) GT, the ground-truth recordings; 2) GT (Mel + PWG), where we first converted the ground-truth audio into mel-spectrograms, and then converted the mel-spectrograms back to audio using Parallel WaveGAN (PWG); 3) Tacotron 2 (Mel + PWG); 4) Transformer TTS (Mel + PWG). 5) FastSpeech (Mel + PWG). All systems in 3), 4) and 5) used Parallel WaveGAN as the vocoder for fair comparison. The results are shown in Table 1. It can be seen that FastSpeech 2 and 2s can match the voice quality of autoregressive models (Transformer TTS and Tacotron 2). Importantly, FastSpeech 2 and 2s outperform FastSpeech, which demonstrates the effectiveness of providing variance information such as pitch, energy, and more accurate duration and directly taking ground-truth speech as a training target without using a teacher-student distillation pipeline.
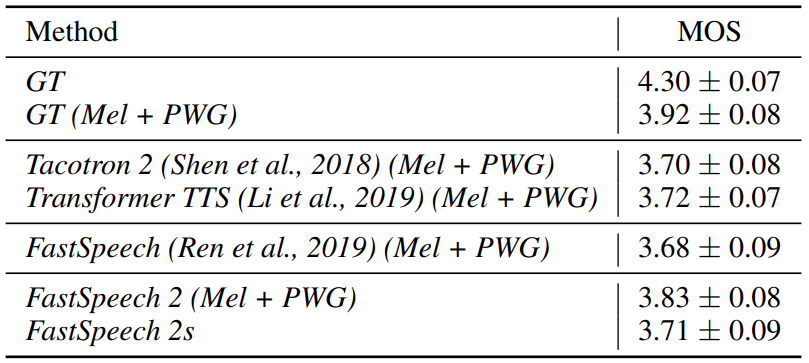
Table 1: The MOS evaluation.
Training and Inference Speedup
We compared the training and inference time between FastSpeech 2/2s and FastSpeech in Table 2. It can be seen that FastSpeech 2 reduces the total training time by 3.12x compared with FastSpeech, and FastSpeech 2 and 2s speeds up the audio generation by 47x and 51x respectively in waveform synthesis compared with Transformer TTS.

Table 2: The comparison of training time and inference latency in waveform synthesis. RTF denotes the real-time factor, that is the time (in seconds) required for the system to synthesize a one second waveform. The training and inference latency test is conducted on a server with 36 Intel Xeon CPU, 256GB memory, 1 NVIDIA V100 GPU and a batch size of 48 for training and 1 for inference.
Variance Control
FastSpeech 2 and 2s introduce several pieces of variance information to ease the one-to-many mapping problem in TTS. As a byproduct, they also make the synthesized speech more controllable. As a demonstration, we manipulated pitch input to control the pitch in synthesized speech in this subsubsection. We show the mel-spectrograms from before and after the pitch manipulation in Figure 2. From the samples, we can see that FastSpeech 2 generates high-quality mel-spectrograms after adjusting F0.

Figure 2: The mel-spectrograms of the voice with different F0. The red curves denote F0 contours. The input text is “they discarded this for a more completely Roman and far less beautiful letter.”
Ablation Study
We conducted ablation studies to demonstrate the effectiveness of several pieces of variance information from FastSpeech 2 and 2s, including pitch, energy, and more accurate duration. We conducted a CMOS evaluation for these ablation studies. The results are shown in Table 4 and 5. We can see that our proposed variance information can help improve the performance of FastSpeech 2 and 2s.

Table 3: Comparison of duration from the teacher model and MFA.

Table 4: CMOS comparison from the ablation studies
Future Work
In the future, we will consider more variance information to further improve voice quality and will further speed up the inference with a more light-weight model (e.g., LightSpeech (opens in new tab)).
Researchers from Machine Learning Group at Microsoft Research Asia are focusing on speech related research, including text to speech, automatic speech recognition, speech translation, singing voice synthesis, and music understanding and generation. Thank you for your attention on the research work: https://speechresearch.github.io/ (opens in new tab).
Paper link:
[1] FastSpeech: Fast, Robust and Controllable Text to Speech, NeurIPS 2019
Paper: https://arxiv.org/pdf/1905.09263.pdf (opens in new tab)
Demo: https://speechresearch.github.io/fastspeech/ (opens in new tab)
[2] FastSpeech 2: Fast and High-Quality End-to-End Text to Speech, ICLR 2021
Paper: https://arxiv.org/pdf/2006.04558.pdf (opens in new tab)
Demo: https://speechresearch.github.io/fastspeech2/ (opens in new tab)