Research Focus: Week of November 7, 2022
Welcome to Research Focus, a new series of blog posts that highlights notable publications, events, code/datasets, new hires and other milestones from across the research community at Microsoft. Barun Patra, Saksham Singhal, Shaohan Huang, Zewen Chi, Li Dong, Furu Wei,…
DeepSpeed Compression: A composable library for extreme compression and zero-cost quantization
| DeepSpeed Team and Andrey Proskurin
Large-scale models are revolutionizing deep learning and AI research, driving major improvements in language understanding, generating creative texts, multi-lingual translation and many more. But despite their remarkable capabilities, the models’ large size creates latency and cost constraints that hinder the…
In the news | ZDNet
Microsoft improves Translator and Azure AI services with new AI ‘Z-code’ models
Microsoft is updating its Translator and other Azure AI services with a set of AI models called Z-code, officials announced on March 22. These updates will improve the quality of machine translations, as well as help these services support more…
DeepSpeed: Advancing MoE inference and training to power next-generation AI scale
| DeepSpeed Team and Andrey Proskurin
In the last three years, the largest trained dense models have increased in size by over 1,000 times, from a few hundred million parameters to over 500 billion parameters in Megatron-Turing NLG 530B (MT-NLG). Improvements in model quality with size…
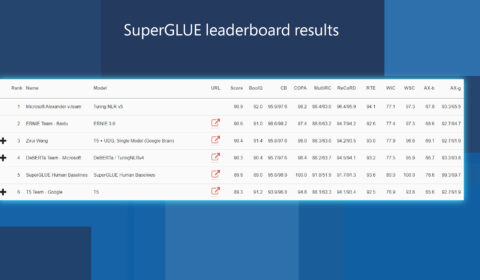
Efficiently and effectively scaling up language model pretraining for best language representation model on GLUE and SuperGLUE
| Jianfeng Gao and Saurabh Tiwary
As part of Microsoft AI at Scale (opens in new tab), the Turing family of NLP models are being used at scale across Microsoft to enable the next generation of AI experiences. Today, we are happy to announce that the…
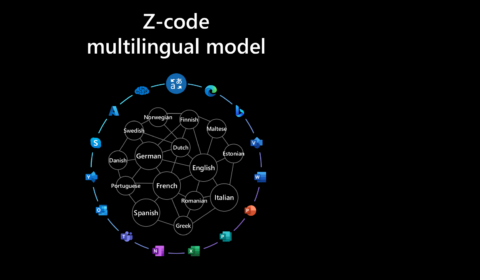
In the news | Microsoft Translator Blog
Multilingual translation at scale: 10000 language pairs and beyond
Microsoft is on a quest for AI at Scale with high ambition to enable the next generation of AI experiences. The Microsoft Translator ZCode team is working together with Microsoft Project Turing and Microsoft Research Asia to advance language and…
Turing Bletchley: A Universal Image Language Representation model by Microsoft
| Saurabh Tiwary
Today, the Microsoft Turing team (opens in new tab) is thrilled to introduce Turing Bletchley, a 2.5-billion parameter Universal Image Language Representation model (T-UILR) that can perform image-language tasks in 94 languages. T-Bletchley has an image encoder and a universal language encoder that vectorize…
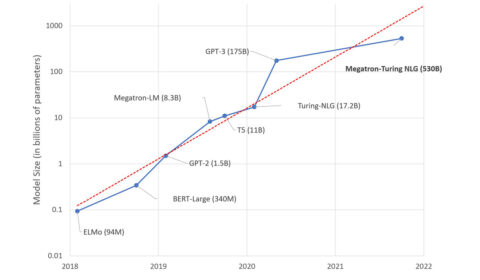
Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, the World’s Largest and Most Powerful Generative Language Model
| Ali Alvi and Paresh Kharya
We are excited to introduce the DeepSpeed- and Megatron-powered Megatron-Turing Natural Language Generation model (MT-NLG), the largest and the most powerful monolithic transformer language model trained to date, with 530 billion parameters. It is the result of a research collaboration…
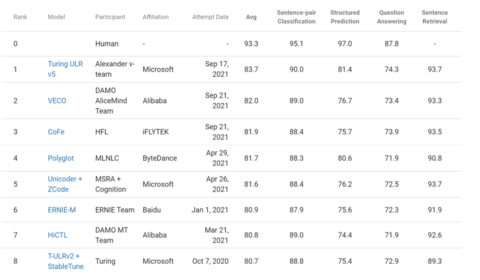
Microsoft Turing Universal Language Representation model, T-ULRv5, tops XTREME leaderboard and trains 100x faster
| Saurabh Tiwary and Lidong Zhou
Today, we are excited to announce that with our latest Turing universal language representation model (T-ULRv5), a Microsoft-created model is once again the state of the art and at the top of the Google XTREME public leaderboard (opens in new…