
Research Focus: Week of October 28, 2024
New Research | FLASH: Workflow automation agent for diagnosing recurring incidents; METAREFLECTION: Learning instructions for language agents using past reflections; Boosting LLM training efficiency through faster communication between GPUs; and more.

Research at Microsoft 2023: A year of groundbreaking AI advances and discoveries
AI saw unparalleled growth in 2023, reaching millions daily. This progress owes much to the extensive work of Microsoft researchers and collaborators. In this review, learn about the advances in 2023, which set the stage for further progress in 2024.
In the news | Metaverse Post
Microsoft’s DeepSpeed4Science Advances AI in Scientific Research
Microsoft recently launched DeepSpeed4Science initiative to apply deep learning in natural sciences, including drug development and renewable energy. DeepSpeed, an open-source AI framework, aims to accelerate and scale up deep learning processes.
In the news | WinBuzzer
Microsoft Announces DeepSpeed4Science Initiative for AI Based Scientific Research
Microsoft has introduced the DeepSpeed4Science initiative through its DeepSpeed team. The initiative focuses on the application of deep learning in the natural sciences, targeting areas such as drug development and renewable energy. The DeepSpeed system, an open-source AI framework from…

Announcing the DeepSpeed4Science Initiative: Enabling large-scale scientific discovery through sophisticated AI system technologies
| Shuaiwen Leon Song, Bonnie Kruft, Minjia Zhang, Conglong Li, Martin Cai, and Yuxiong He
Editor’s note, Sept. 28, 2023 – The founding collaborators list was updated to correct omissions and the scientific foundation model graph was updated to correct information. In the next decade, deep learning may revolutionize the natural sciences, enhancing our capacity to…
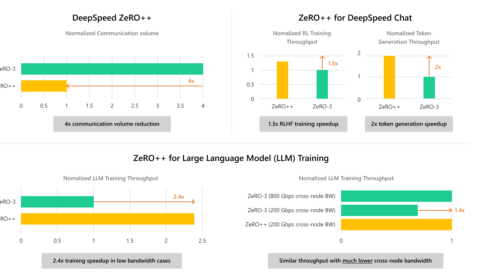
DeepSpeed ZeRO++: A leap in speed for LLM and chat model training with 4X less communication
| DeepSpeed Team and Andrey Proskurin
Large AI models are transforming the digital world. Generative language models like Turing-NLG, ChatGPT, and GPT-4, powered by large language models (LLMs), are incredibly versatile, capable of performing tasks like summarization, coding, and translation. Similarly, large multimodal generative models like…
Research Focus: Week of November 7, 2022
Welcome to Research Focus, a new series of blog posts that highlights notable publications, events, code/datasets, new hires and other milestones from across the research community at Microsoft. Barun Patra, Saksham Singhal, Shaohan Huang, Zewen Chi, Li Dong, Furu Wei,…
DeepSpeed Compression: A composable library for extreme compression and zero-cost quantization
| DeepSpeed Team and Andrey Proskurin
Large-scale models are revolutionizing deep learning and AI research, driving major improvements in language understanding, generating creative texts, multi-lingual translation and many more. But despite their remarkable capabilities, the models’ large size creates latency and cost constraints that hinder the…
DeepSpeed: Advancing MoE inference and training to power next-generation AI scale
| DeepSpeed Team and Andrey Proskurin
In the last three years, the largest trained dense models have increased in size by over 1,000 times, from a few hundred million parameters to over 500 billion parameters in Megatron-Turing NLG 530B (MT-NLG). Improvements in model quality with size…