Research at Microsoft 2021: Collaborating for real-world change
Over the past 30 years, Microsoft Research has undergone a shift in how it approaches innovation, broadening its mission to include not only advancing the state of computing but also using technology to tackle some of the world’s most pressing…

Tutel: An efficient mixture-of-experts implementation for large DNN model training
| Wei Cui, Yifan Xiong, Peng Cheng, and Rafael Salas
Mixture of experts (MoE) is a deep learning model architecture in which computational cost is sublinear to the number of parameters, making scaling easier. Nowadays, MoE is the only approach demonstrated to scale deep learning models to trillion-plus parameters, paving…
In the news | Microsoft Translator Blog
Multilingual translation at scale: 10000 language pairs and beyond
Microsoft is on a quest for AI at Scale with high ambition to enable the next generation of AI experiences. The Microsoft Translator ZCode team is working together with Microsoft Project Turing and Microsoft Research Asia to advance language and…
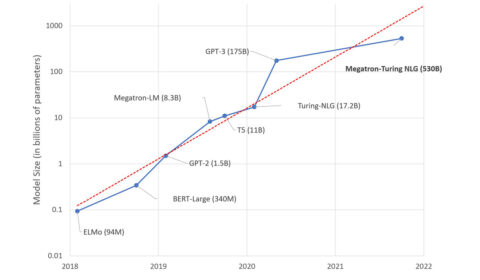
Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, the World’s Largest and Most Powerful Generative Language Model
| Ali Alvi and Paresh Kharya
We are excited to introduce the DeepSpeed- and Megatron-powered Megatron-Turing Natural Language Generation model (MT-NLG), the largest and the most powerful monolithic transformer language model trained to date, with 530 billion parameters. It is the result of a research collaboration…
In the news | VentureBeat
Microsoft taps AI techniques to bring Translator to 100 languages
Today, Microsoft announced that Microsoft Translator, its AI-powered text translation service, now supports more than 100 different languages and dialects. With the addition of 12 new languages including Georgian, Macedonian, Tibetan, and Uyghur, Microsoft claims that Translator can now make…
DeepSpeed powers 8x larger MoE model training with high performance
| DeepSpeed Team and Z-code Team
Today, we are proud to announce DeepSpeed MoE, a high-performance system that supports massive scale mixture of experts (MoE) models as part of the DeepSpeed (opens in new tab) optimization library. MoE models are an emerging class of sparsely activated…
DeepSpeed: Accelerating large-scale model inference and training via system optimizations and compression
| DeepSpeed Team, Rangan Majumder, and Andrey Proskurin
Last month, the DeepSpeed Team announced ZeRO-Infinity, a step forward in training models with tens of trillions of parameters. In addition to creating optimizations for scale, our team strives to introduce features that also improve speed, cost, and usability. As…
In the news | The Batch
Toward 1 Trillion Parameters
An open source library could spawn trillion-parameter neural networks and help small-time developers build big-league models. What’s new: Microsoft upgraded DeepSpeed, a library that accelerates the PyTorch deep learning framework. The revision makes it possible to train models five times…
In the news | Analytics India Magazine
Microsoft Releases Latest Version Of DeepSpeed, Its Python Library For Deep Learning Optimisation
Recently, Microsoft announced the new advancements in the popular deep learning optimisation library known as DeepSpeed. This library is an important part of Microsoft’s new AI at Scale initiative to enable next-generation AI capabilities at scale.