

MInference
Million-Tokens Prompt Inference for Long-context LLMs
News
- 🎴 [24/07/03] To got more detail in our project page Project Page (opens in new tab), Paper (opens in new tab), Code (opens in new tab), and HF Demo (opens in new tab).
- 🧩 [24/07/03] We will present MInference 1.0 at the Microsoft Booth and ES-FoMo at ICML’24. See you in Vienna!
TL;DR
MInference 1.0 leverages the dynamic sparse nature of LLMs’ attention, which exhibits some static patterns, to speed up the pre-filling for long-context LLMs. It first determines offline which sparse pattern each head belongs to, then approximates the sparse index online and dynamically computes attention with the optimal custom kernels. This approach achieves up to a 10x speedup for pre-filling on an A100 while maintaining accuracy.
- MInference 1.0: Accelerating Pre-filling for Long-Context LLMs via Dynamic Sparse Attention (opens in new tab) (Under Review, ES-FoMo @ ICML’24)
Huiqiang Jiang†, Yucheng Li†, Chengruidong Zhang†, Qianhui Wu, Xufang Luo, Surin Ahn, Zhenhua Han, Amir H. Abdi, Dongsheng Li, Chin-Yew Lin, Yuqing Yang and Lili Qiu
🎥 Overview

Insights
- Attention, especially in long-context scenarios, is sparse and dynamic, i.e., the sparse patterns are largely different across inputs.
- This dynamic sparsity presents three unique spatial aggregation patterns that persist for all inputs: A-shape, Vertical-Slash, and Block-Sparse.
- These dynamic sparse indices can be approximated with minimal overhead online and speed up attention inference using a custom optimized GPU kernel.
Why MInference?
Long-context LLM inference faces two major challenges: 1) long pre-filling stage attention latency, and 2) high storage and transfer costs for KV cache. Previous efficient methods for long-context LLMs have focused on KV-cache compression, static sparse attention (e.g., model compression, SSM, linear attention), or distributed serving. However, these methods struggle to achieve acceptable latency for million-token level prompts with low cost and a single A100 GPU.

To address these issues, we propose MInference, where the name reflects our ambition to enable million-token inference on a single A100 machine. MInference is a training-free efficient method for the pre-filling stage of long-context LLMs based on dynamic sparse attention. Specifically, we leverage the static spatial aggregation patterns of dynamic sparse attention, as shown in Fig. (3), and classify the dynamic sparse patterns into three types: A-shape, Vertical-Slash, and Block-Sparse. MInference first determines the optimal dynamic sparse pattern for each head offline using the Kernel-Aware Sparse Pattern Search algorithm, as illustrated in Alg. (1). During inference, it dynamically approximates the dynamic sparse indices based on the head’s pattern, as shown in Algs. (2) and (3). Finally, we perform efficient dynamic sparse attention computation using our optimized GPU kernel, significantly reducing the pre-filling stage latency for long-context LLMs.

For example, with the Vertical-Slash pattern, we first use the attention calculation between the last Q and K to estimate the optimal indices of vertical lines and slash lines. Then, we utilize the dynamic sparse compiler PIT and Triton to construct the Vertical-Slash FlashAttention kernel, accelerating the attention computation. For the A-shape, Vertical-Slash, and Block-Sparse patterns, we first use the mean pooling of Q and K in attention calculations. By leveraging the commutative property of mean pooling and MatMul, we estimate the block-sparse indices. Then, we use Triton to construct the Block-Sparse FlashAttention kernel, accelerating the attention computation. For detailed kernel implementation, please refer to Appendix C.4 and the code.
Our main contributions are four-fold:
- We propose a dynamic sparse attention method, MInference, to accelerate the pre-filling stage of long-context LLMs by up to 10x for 1M token prompts while maintaining the capabilities of LLMs, especially their retrieval abilities, as demonstrated in tasks like Needle in a Haystack.
- We classify dynamic sparse attention in LLMs into three patterns and design the Kernel-Aware Sparse Pattern Search algorithm to find the optimal head pattern offline.
- We introduce an online approximate method and optimized GPU kernels to accelerate LLM inference with minimal overhead. We also propose an optimal inference codebase that enables 1M token pre-filling inference on a single A100 using LLaMA-style models.
- We evaluate MInference across four benchmarks: InfiniteBench, RULER, PG-19, and Needle in a Haystack, with token lengths ranging from 128k to 1M, to assess the actual context processing capabilities of LLMs. Experimental results reveal that MInference can maintain or slightly improve actual context processing capabilities, while also outperforming in terms of cost efficiency and system latency.
Experiments Results in Long-context Benchmarks
We tested MInference across a range of scenarios, including QA, coding, retrieval-based tasks, multi-hop QA, summarization, and math tasks. The RULER benchmark includes several complex multi-hop or multi-needle tasks, effectively reflecting the actual context window size of LLMs. As shown in Tab.(1), our method effectively preserves the actual context window processing capability of LLMs and even slightly extends the actual context window size to 32K.

We also tested MInference on a broader range of tasks using the InfiniteBench, which has an average token length of 214K, as shown in Tab.(2). Compared to the SoTA baselines, MInference consistently maintains performance across all tasks. Notably, in the more challenging retrieval tasks like KV retrieval task, all baselines fail to make accurate predictions, with accuracy rates below 1.2%. However, MInference successfully retains the ability to handle dynamic KV pair retrieval.

To further evaluate performance across different context lengths and positions of key information within prompts, we tested various models and methods using the Needle in a Haystack task. As shown in Fig.(1), MInference performs well across different models, context windows, and positions within the prompt, maintaining or even slightly improving performance compared to the original models. In the case of LLaMA-3-8B and GLM-4-9B-1M, MInference achieves full green performance for context windows up to 1M. In comparison, StreamingLLM and InfLLM experience a performance drop to below 20% in the middle segments of prompts even in the 70K context windows.

We also tested MInference on the language model tasks using PG-19, which includes tokens up to 100k. As shown in Fig.(2), MInference effectively maintains the perplexity of LLaMA-3-8B and Yi-9B-200K, while all baselines experience varying degrees of perplexity drop. Additionally, it can be observed that StreamingLLM with dilated and strided configurations better maintain perplexity performance compared to the standard StreamingLLM.

Latency Breakdown and Sparsity Pattern in the Kernel
Fig.(3) shows the micro-benchmark results of the three attention patterns proposed in this paper, as well as FlashAttention. It can be seen that Vertical-Slash is the slowest among the three patterns, but it still achieves a 13x speedup compared to FlashAttention under 1M context windows.

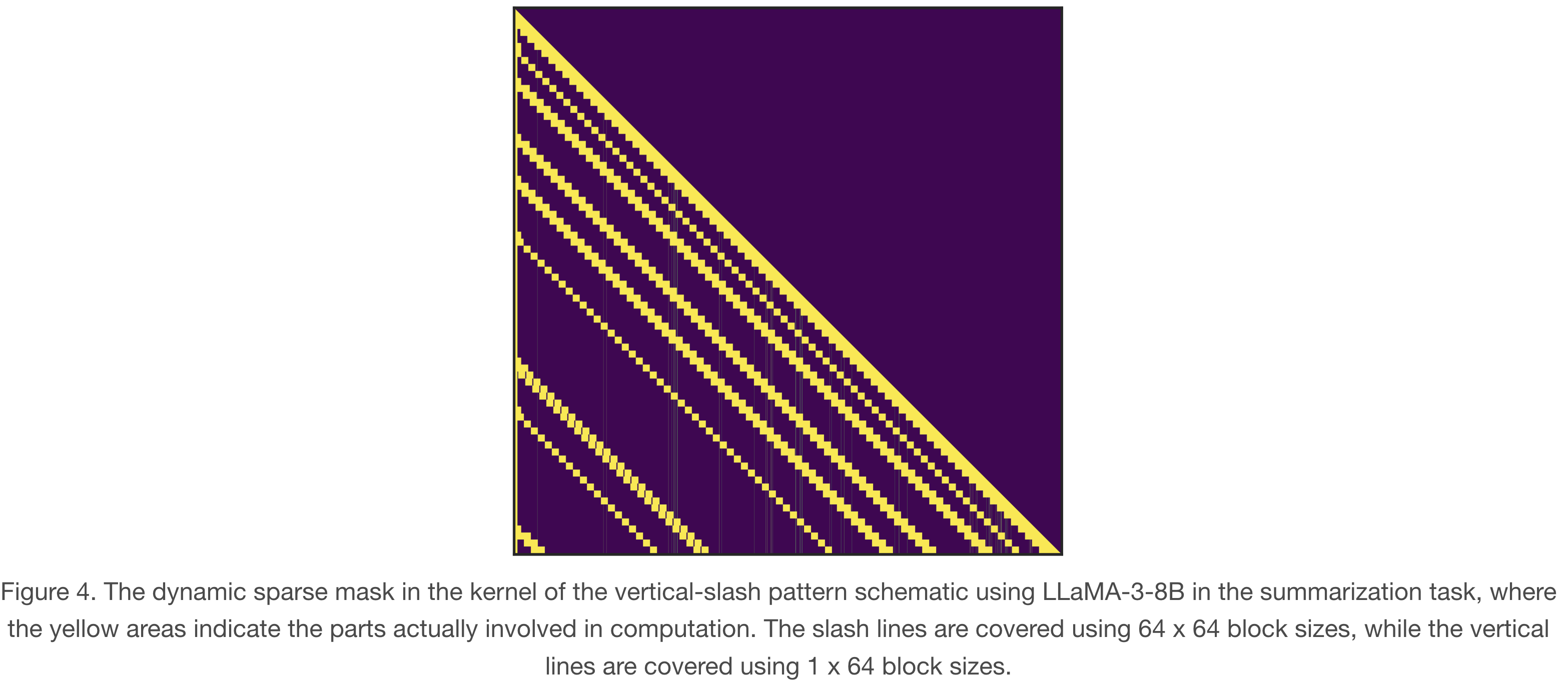
Fig.(4) shows the sparse indices in the kernel of the Vertical-Slash head. The vertical lines are computed using 1×64 blocks through PIT FlashAttention, while the slash lines are computed using 64×64 blocks through Block-level FlashAttention.
FAQ
Q1: How to effectively evaluate the impact of dynamic sparse attention on the capabilities of long-context LLMs?
To evaluate long-context LLM capabilities using models like LLaMA-3-8B-Instruct-1M and GLM-4-9B-1M, we tested: 1) context window with RULER, 2) general tasks with InfiniteBench, 3) retrieval tasks with Needle in a Haystack, and 4) language model prediction with PG-19.
We found traditional methods perform poorly in retrieval tasks, with difficulty levels as follows: KV retrieval > Needle in a Haystack > Retrieval.Number > Retrieval PassKey. The main challenge is the semantic difference between needles and the haystack. Traditional methods excel when this difference is larger, as in passkey tasks. KV retrieval requires higher retrieval capabilities since any key can be a target, and multi-needle tasks are even more complex.
We will continue to update our results with more models and datasets in future versions.
Q2: Does this dynamic sparse attention pattern only exist in long-context LLMs that are not fully trained?
Firstly, attention is dynamically sparse, a characteristic inherent to the mechanism. We selected state-of-the-art long-context LLMs, GLM-4-9B-1M and LLaMA-3-8B-Instruct-1M, with effective context windows of 64K and 16K. With MInference, these can be extended to 64K and 32K, respectively. We will continue to adapt our method to other advanced long-context LLMs and update our results, as well as explore the theoretical basis for this dynamic sparse attention pattern.
Q3: Does this dynamic sparse attention pattern only exist in Auto-regressive LMs or RoPE based LLMs?
Similar vertical and slash line sparse patterns have been discovered in BERT[1] and multi-modal LLMs[2]. Our analysis of T5’s attention patterns, shown in the figure, reveals these patterns persist across different heads, even in bidirectional attention.
[1] SparseBERT: Rethinking the Importance Analysis in Self-Attention, ICML 2021.
[2] LOOK-M: Look-Once Optimization in KV Cache for Efficient Multimodal Long-Context Inference, 2024.

Q4: What is the relationship between MInference, SSM, Linear Attention, and Sparse Attention?
All four approaches (MInference, SSM, Linear Attention, and Sparse Attention) efficiently optimize attention complexity in Transformers, each introducing inductive bias differently. The latter three require training from scratch. Recent works like Mamba-2 and Unified Implicit Attention Representation unify SSM and Linear Attention as static sparse attention, with Mamba-2 itself being a block-wise sparse method. While these approaches show potential due to sparse redundancy in attention, static sparse attention may struggle with dynamic semantic associations in complex tasks. In contrast, dynamic sparse attention is better suited for managing these relationships.
BibTeX
If you find this project helpful, please cite the following papers:
@article{jiang2024minference,
title={MInference 1.0: Accelerating Pre-filling for Long-Context LLMs via Dynamic Sparse Attention},
author={Jiang, Huiqiang and Li, Yucheng and Zhang, Chengruidong and Wu, Qianhui and Luo, Xufang and Ahn, Surin and Han, Zhenhua and Abdi, Amir H and Li, Dongsheng and Lin, Chin-Yew and Yang, Yuqing and Qiu, Lili},
journal={arXiv preprint arXiv:2407.02490},
year={2024}
}