
Goals of Quickr
A desirable system for approximating big data queries has three aspects. First, it should offer turnkey support for approximations. That is, given a query, decide whether or not it can be sampled and output the appropriate sampled query plan. Input samples or knowledge of future queries may not be available. Second, the system should support complex queries, i.e., support the large portion of U-SQL. Finally, offer strong guarantees on the accuracy of the answer; for example, with high probability (whp), none of the groups in the answer will be missed and the output value of aggregations is within a bounded ratio of the true answer.
Inline sampling: gains without overhead
Quickr samples inline in the query plan as shown in the figure on the right. In contrast to prior work that maintains input samples and matches queries to preexisting samples, it is easy to see that inline sampling has little apriori overhead. A key observation in Quickr is that big-data queries perform multiple passes over data in part due to the complexity of the queries and in part due to the nature of parallel plans; the median query in Cosmos has 2.4 effective passes over data (90th percentile value is 6.5). Hence, inline sampling also has the potential for sizable gains.
Cover more queries
Many queries that appear un-approximable for input samples can be sped up by inline sampling. Consider a query that touches many columns; stratifying on many columns leads to an input sample that is as large as the input and hence such queries would not benefit from input samples. However, Quickr can place a sampler after the selections or joins whose (complex) predicates contributed many of these columns. If the selects are pushed down to the first parallel pass on data (as they often are), samplers will reduce data written by the first pass speeding up all downstream operations.
Sampling multiple inputs of a join
Another novel aspect that lets Quickr cover many more queries than prior methods is a universe sampler that samples multiple join inputs. It is well known that joining a p probability sample of inputs is akin to a p^2 probability sample of the join output. Hence, sampling the join inputs improves performance at the cost of substantial degradation in answer quality. On the other hand, when queries join large inputs, sampling the join output offers limited speed-up.
With the universe sampler, joining a p probability sample of inputs is statistically equivalent to a p probability universe sample of the join output. The key idea is to consistently sample the join inputs without any coordination (such as exchanging histograms of join keys). We will show that the universe sampler is applicable broadly, i.e., it supports multiple equijoins and only requires the group-by columns and the value of aggregates to be uncorrelated with the sampled column set.
Sampling + QO
Quickr offers turn-key support for approximations by picking for every newly arriving query an execution plan with samplers. There are at least two choices as to how we can obtain a good plan that contains samplers: (a) Insert samplers a posteriori into a plan that is output by a traditional relational query optimizer or (b) Incorporate samplers as first-class operators along with the other database operators and explore the larger combined space of possible plans within a query optimizer. Notice that option (b) can yield plans that cannot be obtained from using option (a). For example, when a sampler reduces cardinality, downstream join operations can be implemented differently and more efficiently as a cross join instead of a hash-join. As another example, for queries with many joins and selects, option (a) may offer a plan on which all simple edits to insert samplers appear infeasible (inaccurate). Yet, a different ordering of the joins or selects may allow samplers to be inserted. Hence, we chose option (b); we offer a new algorithm that incorporates samplers as native operators into a Cascades-style cost-based query optimizer.
Reasoning about the accuracy of sampled expressions
Our method transforms a query expression with arbitrarily many samplers to an expression with one sampler at the root. In particular, we generalize prior work that only considered SUM-like aggregates to the case where answers can have groups and multiple aggregations of various kinds. We also generalize the method to a broader class of samplers that are not uniformly random.
Furthermore, we compute unbiased estimators of the aggregations and various error measures (such as variance, confidence interval etc.) in one effective pass over data whereas in general error bounds require a self-join over samples or bootstrap which involves hundreds or thousands of trials on the sample.
Sampling dominance
We introduce a novel notion of dominance: given two query expressions E1 and E2 whose output is identical when samplers are removed, E1 is said to dominate E2, iff the accuracy of E1 is no worse than that of E2. We use three ideas to establish dominance for a rich class of samplers. First, any uniformly random sampler convolves with all database operations in the sense that there exists a corresponding sampled expression which has exactly the same accuracy (variance and expectation). Second, any sampler that is strictly more likely to pass a row relative to some uniformly random sampler is analyzable in that its accuracy can be bounded from below. Finally, we show a special-case set of samplers that are not uniformly random but do convolve with all database operators. The first idea is borrowed from prior work but the other two are new to the best of our knowledge.

An example script that is otherwise unapproximable. Input sampling would choose to stratify each of the fact tables (store sales etc.) on {item_sk, date_sk, customer_sk} so as to not miss groups in the answer but the triple has almost as many distinct items as the original dataset. Quickr would place our new universe sampler on all three fact tables.

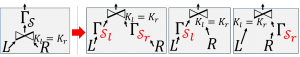
Pushing samplers past a join operation.

A transformation rule that generates alternative plans with the sampler moved to before a selection.
People
Surajit Chaudhuri
Technical Fellow, Data Platforms and Analytics
Srikanth Kandula
Partner Researcher
Kukjin Lee
Principal Research Software Design Engineer