

-
The advances in location-acquisition and mobile computing techniques have generated massive spatial trajectory data, which represent the mobility of a diversity of moving objects, such as people, vehicles and animals. Many techniques have been proposed for processing, managing and mining trajectory data in the past decade, fostering a broad range of applications. In this article, we conduct a systematic survey on the major research into trajectory data mining, providing a panorama of the field as well as the scope of its research topics. Following a roadmap from the derivation of trajectory data, to trajectory data preprocessing, to trajectory data management, and to a variety of mining tasks (such as trajectory pattern mining, outlier detection, and trajectory classification), the survey explores the connections, correlations and differences among these existing techniques. This survey also introduces the methods that transform trajectories into other data formats, such as graphs, matrices, and tensors, to which more data mining and machine learning techniques can be applied. Finally, some public trajectory datasets are presented. This survey can help shape the field of trajectory data mining, providing a quick understanding of this field to the community.
Yu Zheng. Trajectory Data Mining: An Overview. ACM Transactions on Intelligent Systems and Technology (ACM TIST). 2015, vol. 6, issue 3.
-
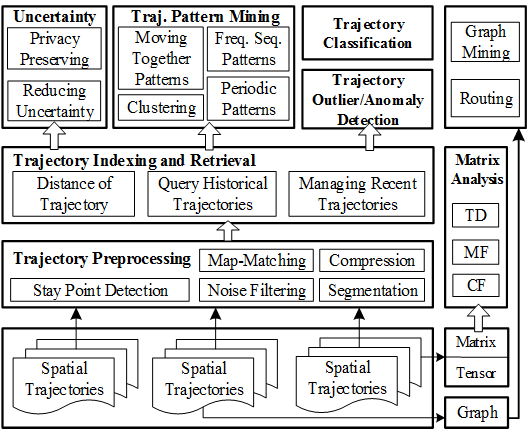
Before using trajectory data, we need to deal with a number of issues, such as noise filtering, segmentation, and map-matching. This stage is called trajectory preprocessing, which is a fundamental step of many trajectory data mining tasks.
- The goal of noise filtering is to remove from a trajectory some noise points that may be caused by the poor signal of location positioning systems (e.g. when traveling in a city canyon).
- A stay point detection algorithm identifies the location where a moving object has stayed for a while within a certain distance threshold. A stay point could stand for a restaurant or a shopping mall that a user has been to, carrying more semantic meanings than other points in a trajectory.
- Trajectory compression is to compress the size of a trajectory (for the purpose of reducing overhead in communication, processing, and data storage) while maintaining the utility of the trajectory.
- Trajectory segmentation divides a trajectory into fragments by time interval, or spatial shape, or semantic meanings, for a further process like clustering and classification.
- Map-Matching aims to project each point of a trajectory onto a corresponding road segment where the point was truly generated.
-
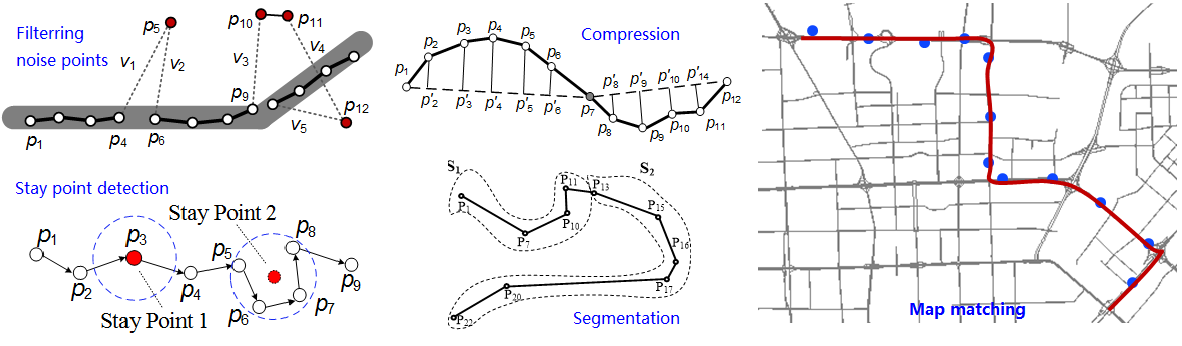
Many online applications require instantly mining of trajectory data (e.g. detecting traffic anomalies), calling for effective data management algorithms that can quickly retrieve particular trajectories satisfying certain criteria (such as spatio-temporal constraints) from a big trajectory corpus. There are usually two major types of queries: the nearest neighbors and range queries. The former is also associated with a distance metric, e.g. the distance between two trajectories. Additionally, there are two types (historical and recent) of trajectories, which need different managing methods.
Here is the outline of this section.
- Spatial Databases: introduce basic indexing and retrieval algorithms for spatial data.
- Queries: Range queries and KNN queries
- Distance metrics for trajectories: point to trajectory, trajectory to trajectory, segment to segment.
- Indexing structures: 3D index, multiple version index, spatial partition + temporal index
- Retrieval algorithms
-
Objects move continuously while their locations can only be updated at discrete times, leaving the location of a moving object between two updates uncertain. To enhance the utility of trajectories, a series of research tried to model and reduce the uncertainty of trajectories. On the contrary, a branch of research aims to protect a user’s privacy when the user discloses her trajectories.
- Constructing possible routes based on uncertain trajectories in free spaces
- Infer the most likely route in a road network based on low sampling rate trajectories
-
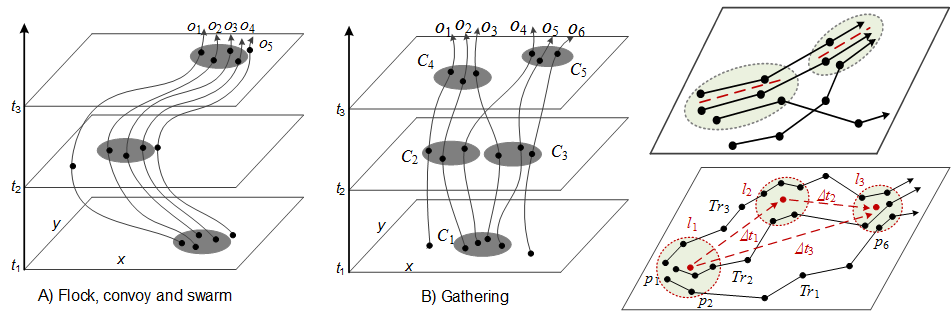
The huge volume of spatial trajectories enables opportunities for analyzing the mobility patterns of moving objects, which can be represented by an individual trajectory containing a certain pattern or a group of trajectories sharing similar patterns. In this section, we survey the literature that is concerned with four categories of patterns: moving together patterns, trajectory clustering, frequent sequential patterns and periodic patterns.
-
-
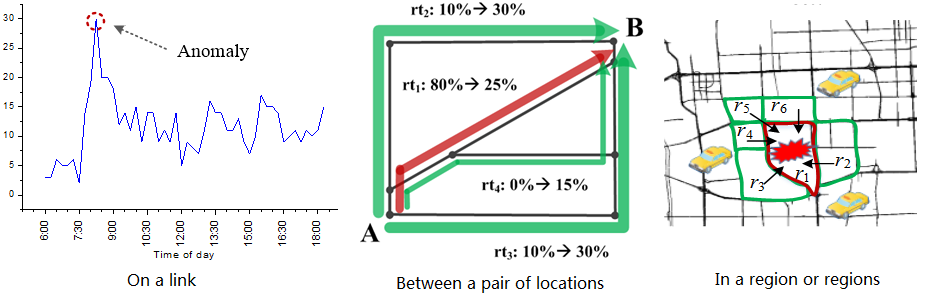
Different from trajectory patterns that frequently occur in trajectory data, trajectory outliers (a.k.a. anomalies) can be items (a trajectory or a segment of trajectory) that is significantly different from other items in terms of some similarity metric. It can also be events or observations (represented by a collection of trajectories) that do not conform to an expected pattern (e.g. a traffic congestion caused by a car accident). Section 8 introduces anomaly detection from trajectory data.
-
(Slides (opens in new tab)) (Paper)
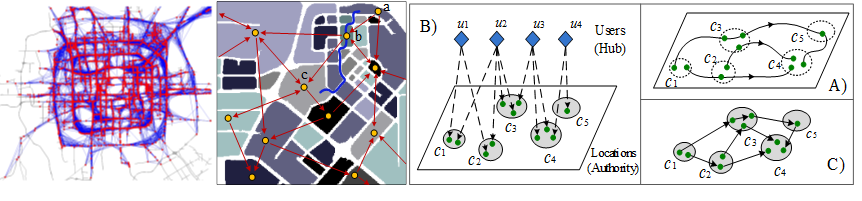
besides studying trajectories in its original form, we can transform trajectories into other formats, such as graph, matrix and tensor. The new representations of trajectories expand and diversify the approaches for trajectory data mining, leveraging existing mining techniques, e.g. graph mining, collaborative filtering (CF), matrix factorization (MF), and tensor decomposition (TD).
-
(Slides (opens in new tab)) (Paper)

- Collaborative Filtering (CF): User-based CF and Item-based CF
- Matrix factorization: SVD and NMF
- Context-aware matrix factorization
Turning Trajectories into Tensors
(Slides (opens in new tab)) (Paper)
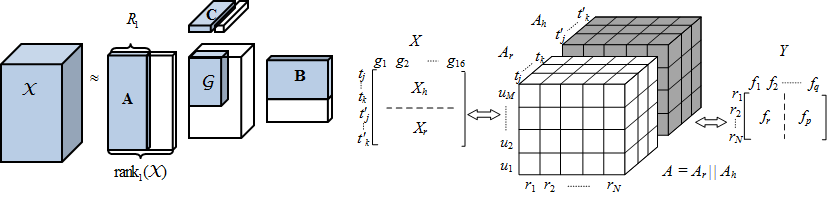
- Tensor decomposition
- Context-aware tensor decomposition
