

VALL-E
A neural codec language model for speech synthesis
We introduce a language modeling approach for text-to-speech synthesis (TTS). Specifically, we train a neural codec language model (called VALL-E) using discrete codes derived from an off-the-shelf neural audio codec model, and regard TTS as a conditional language modeling task rather than continuous signal regression as in previous work. VALL-E emerges in-context learning capabilities and can be used to synthesize high-quality personalized speech with only a 3-second enrolled recording of an unseen speaker as a prompt. VALL-E significantly outperforms the state-of-the-art zero-shot TTS system in terms of speech naturalness and speaker similarity. In addition, VALL-E could preserve the speaker’s emotion and acoustic environment of the acoustic prompt in synthesis. Extending its capabilities, VALL-E X adapts to multi-lingual scenarios, facilitating cross-lingual zero-shot TTS. Meanwhile, VALL-E R introduces a phoneme monotonic alignment strategy, bolstering the robustness of speech generation. With the integration of repetition-aware sampling and grouped code modeling techniques, VALL-E 2 achieves a groundbreaking milestone: human parity in zero-shot TTS performance on LibriSpeech and VCTK datasets. This marks the first instance of such an achievement, setting a new standard for the field. MELLE is a novel continuous-valued tokens based language modeling approach for text to speech synthesis (TTS). MELLE autoregressively generates continuous mel-spectrogram frames directly from text condition, bypassing the need for vector quantization, which are originally designed for audio compression and sacrifice fidelity compared to mel-spectrograms.
Model versions
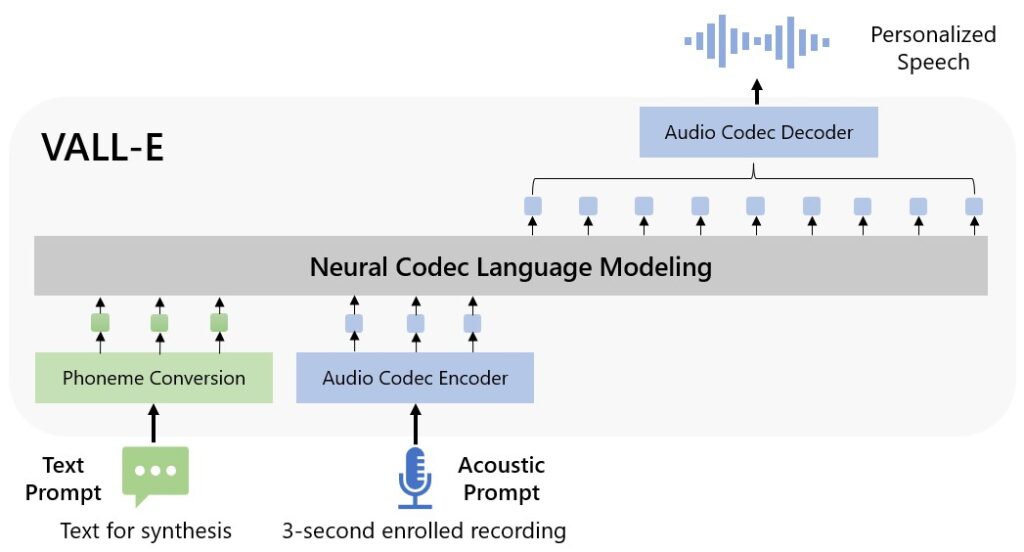 |
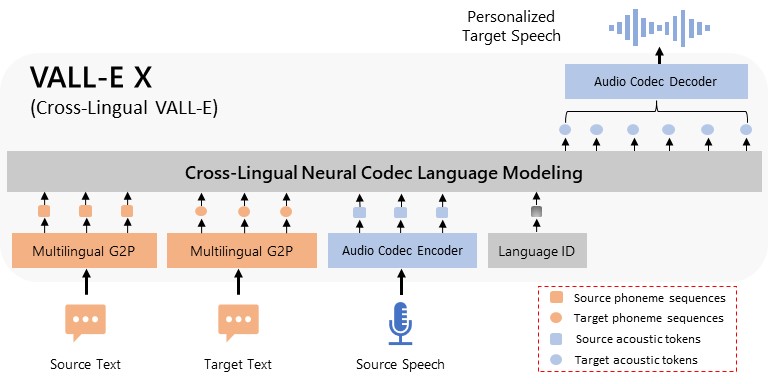 |
 |
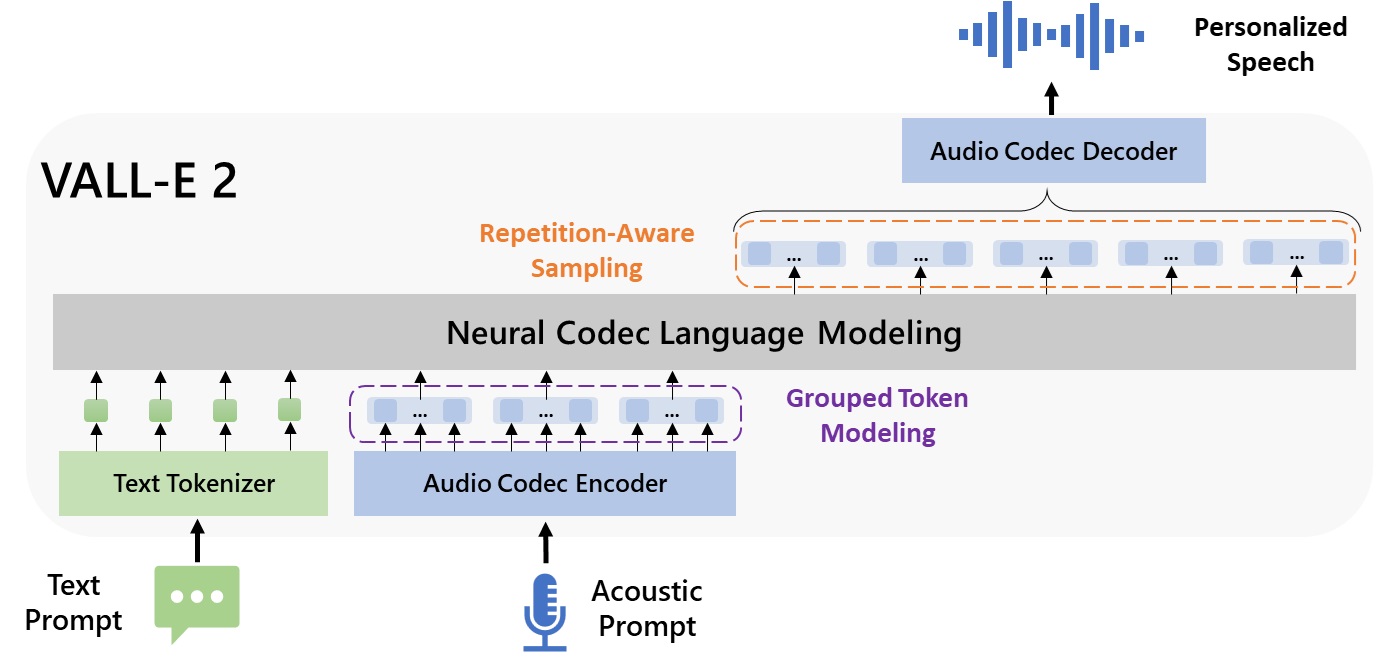 |
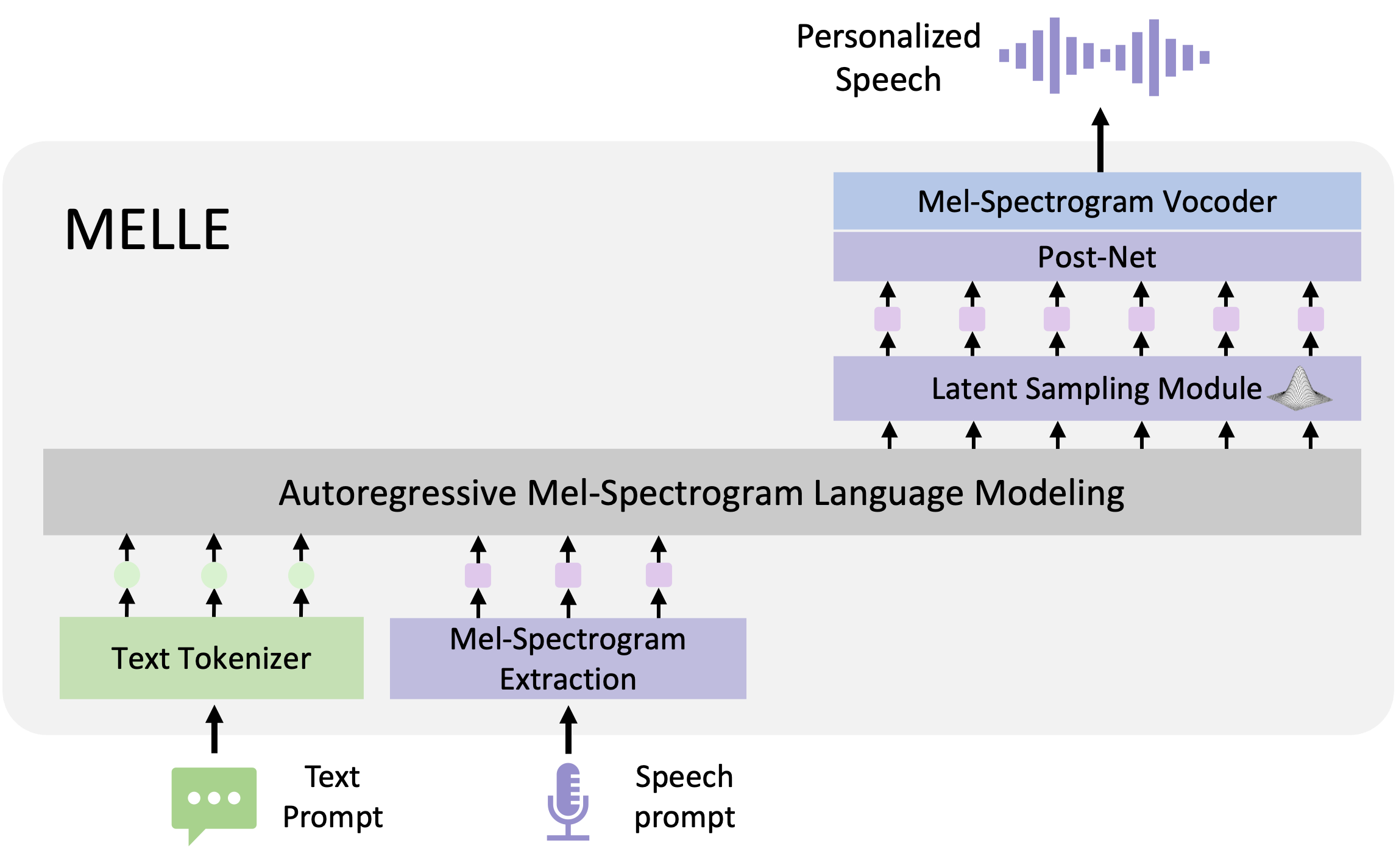 |
|
Ethics statement
VALL-E could synthesize speech that maintains speaker identity and could be used for educational learning, entertainment, journalistic, self-authored content, accessibility features, interactive voice response systems, translation, chatbot, and so on. While VALL-E can speak in a voice like the voice talent, the similarity, and naturalness depend on the length and quality of the speech prompt, the background noise, as well as other factors. It may carry potential risks in the misuse of the model, such as spoofing voice identification or impersonating a specific speaker. We conducted the experiments under the assumption that the user agrees to be the target speaker in speech synthesis. If the model is generalized to unseen speakers in the real world, it should include a protocol to ensure that the speaker approves the use of their voice and a synthesized speech detection model. If you suspect that VALL-E is being used in a manner that is abusive or illegal or infringes on your rights or the rights of other people, you can report it at the Report Abuse Portal.