

VALL-E Family
Neural codec language models for speech synthesis
With the help of discrete neural audio codecs, large language models (LLM) have increasingly been recognized as a promising methodology for zero-shot Text-to-Speech (TTS) synthesis. However, sampling based decoding strategies bring astonishing diversity to generation, but also pose robustness issues such as typos, omissions and repetition. In addition, the high sampling rate of audio also brings huge computational overhead to the inference process of autoregression. To address these issues, we propose VALL-E R, a robust and efficient zero-shot TTS system, building upon the foundation of VALL-E. Specifically, we introduce a phoneme monotonic alignment strategy to strengthen the connection between phonemes and acoustic sequence, ensuring a more precise alignment by constraining the acoustic tokens to match their associated phonemes. Furthermore, we employ a merge codec approach to downsample the discrete codes in shallow quantization layer, thereby accelerating the decoding speed while preserving the high quality of speech output. Benefiting from these strategies, VALL-E R obtains controllablity over phonemes and demonstrates its strong robustness by approaching the WER of ground truth in experimental results. In addition, it requires fewer autoregressive steps during inference, resulting in over 60% time savings in inference time. This research has the potential to be applied to meaningful projects, including the creation of speech for those affected by aphasia.
This page is for research demonstration purposes only. Currently, we have no plans to incorporate VALL-E R into a product or expand access to the public.
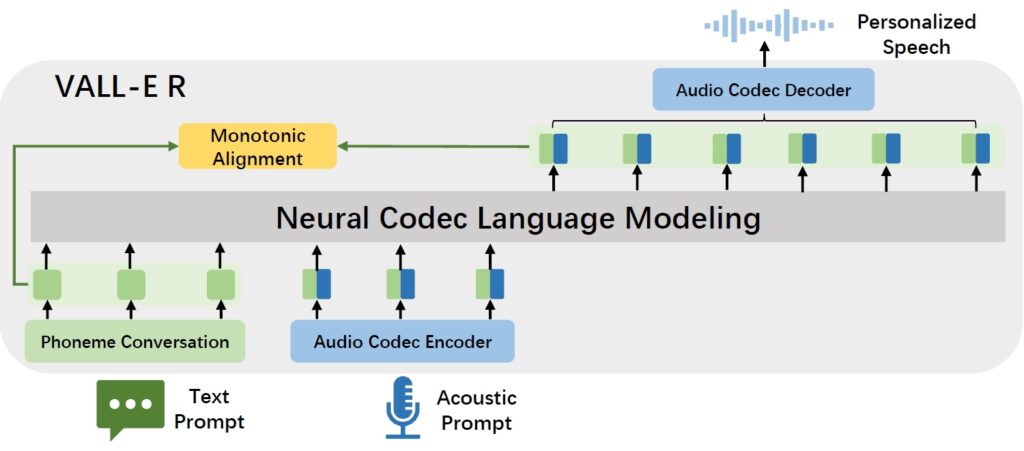
Model Overview
The overview of VALL-E R, a robust and efficient neural codec language model for zero-shot TTS. It incorporates phoneme information (green) when predict audio codec (blue), which can enhance the connection between phoneme and audio to improve the robustness of decoder-only transformer TTS model. Note that VALL-E R achieves faster inference speeds by adopting compact codec codes, derived from the proposed merge codec method, within its autoregressive model.
Audio Samples
-
Text Prompt VALL-E VALL-E R Ground Truth THEN DEAR SAID MISSUS WHITNEY YOU MUST BE KINDER TO HER THAN EVER THINK WHAT IT WOULD BE FOR ONE OF YOU TO BE AWAY FROM HOME EVEN AMONG FRIENDS CRIED ALICE AGAIN FOR THIS TIME THE MOUSE WAS BRISTLING ALL OVER AND SHE FELT CERTAIN IT MUST BE REALLY OFFENDED THE CHAOS IN WHICH HIS ARDOUR EXTINGUISHED ITSELF WAS A COLD INDIFFERENT KNOWLEDGE OF HIMSELF YOU WERE QUITE RIGHT TO SAY NO AMBROSE BEGAN NEVER SMOKE WITH JOHN JAGO HIS CIGARS WILL POISON YOU MOTHER CAREY POURED COFFEE NANCY CHOCOLATE AND THE OTHERS HELPED SERVE THE SANDWICHES AND CAKE DOUGHNUTS AND TARTS -
Text Prompt VALL-E VALL-E R HE SAT DOWN WEAK BEWILDERED AND ONE THOUGHT WAS UPPERMOST ZORA EDISON HELD THAT THE ELECTRICITY SOLD MUST BE MEASURED JUST LIKE GAS OR WATER AND HE PROCEEDED TO DEVELOP A METER THE LODGE IN WHICH UNCAS WAS CONFINED WAS IN THE VERY CENTER OF THE VILLAGE AND IN A SITUATION PERHAPS MORE DIFFICULT THAN ANY OTHER TO APPROACH OR LEAVE WITHOUT OBSERVATION AND THEN HE TOLD ALL ABOUT HIS YOUTH AND THE LITTLE MICE HAD NEVER HEARD THE LIKE BEFORE AND THEY LISTENED AND SAID THE QUESTION IS WHICH OF THE TWO METHODS WILL MOST EFFECTIVELY REACH THE PERSONS WHOSE CONVICTIONS IT IS DESIRED TO AFFECT -
Text Prompt Prosody Reference VALL-E R IF IT ONLY WERE NOT SO DARK HERE AND SO TERRIBLY LONELY I PRAY FOR YOU BUT THAT’S NOT THE SAME AS IF YOU PRAYED YOURSELF ALL MY DANGER AND SUFFERINGS WERE NEEDED TO STRIKE A SPARK OF HUMAN FEELING OUT OF HIM BUT NOW THAT I AM WELL HIS NATURE HAS RESUMED ITS SWAY AND THE WHOLE NIGHT THE TREE STOOD STILL AND IN DEEP THOUGHT AGAINST THESE BOASTING FALSE APOSTLES PAUL BOLDLY DEFENDS HIS APOSTOLIC AUTHORITY AND MINISTRY -
Text Prompt VALL-E VALL-E R As the cosmic cosmic cosmic cosmic cosmic cosmic dance of the stars unfolds in in in in in in silence, revealing the mystical mysteries of the celestial celestial celestial celestial celestial celestial realm Beneath the moonlit night, the solitary wolf’s haunting howl howl howl howl howl echoed through the ancient forest, embodying the primal spirit of the wilderness The relentless relentless relentless relentless relentless relentless pursuit of perfection in in in in in in in in in craftsmanship led the artisan to create an exquisite masterpiece admired for its meticulous meticulous meticulous meticulous meticulous meticulous details As the quantum physicist delved into the quantum realm, the enigmatic entanglement of particles perplexed even the most astute astute astute astute astute astute minds Adventurous ants anxiously ate apples, adventurous adventurous apples -
Text Ground Truth Merge Codec Encodec AND ALL HIS BROTHERS AND SISTERS STOOD ROUND AND LISTENED WITH THEIR MOUTHS OPEN THEN AS IF SATISFIED OF THEIR SAFETY THE SCOUT LEFT HIS POSITION AND SLOWLY ENTERED THE PLACE HOTEL A PLACE WHERE A GUEST OFTEN GIVES UP GOOD DOLLARS FOR POOR QUARTERS THIS WAS WHAT DID THE MISCHIEF SO FAR AS THE RUNNING AWAY WAS CONCERNED IT WAS IN A CORNER THAT HE LAY AMONG WEEDS AND NETTLES
Ethics Statement
VALL-E R could synthesize speech that maintains speaker identity and could be used for educational learning, entertainment, journalistic, self-authored content, accessibility features, interactive voice response systems, translation, chatbot, and so on. While VALL-E R can speak in a voice like the voice talent, the similarity, and naturalness depend on the length and quality of the speech prompt, the background noise, as well as other factors. It may carry potential risks in the misuse of the model, such as spoofing voice identification or impersonating a specific speaker. We conducted the experiments under the assumption that the user agrees to be the target speaker in speech synthesis. If the model is generalized to unseen speakers in the real world, it should include a protocol to ensure that the speaker approves the use of their voice and a synthesized speech detection model. If you suspect that VALL-E R is being used in a manner that is abusive or illegal or infringes on your rights or the rights of other people, you can report it at the Report Abuse Portal.