
Uncertainty-aware Self-training for Few-shot Text Classification
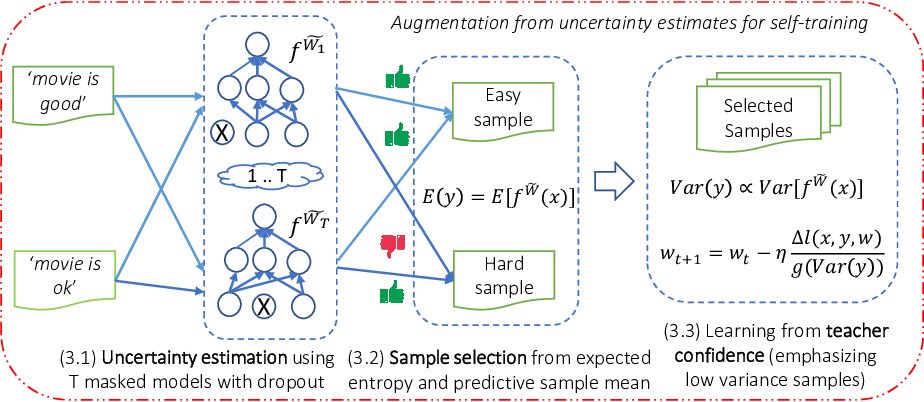
Recent success of large-scale pre-trained language models crucially hinge on fine-tuning them on large amounts of labeled data for the downstream task, that are typically expensive to acquire. In this work, we study self-training as one of the earliest semi-supervised learning approaches to reduce the annotation bottleneck by making use of large-scale unlabeled data for the target task. Standard self-training mechanism randomly samples instances from the unlabeled pool to pseudo-label and augment labeled data. In this work, we propose an approach to improve self-training by incorporating uncertainty estimates of the underlying neural network leveraging recent advances in Bayesian deep learning. Specifically, we propose (i) acquisition functions to select instances from the unlabeled pool leveraging Monte Carlo (MC) Dropout, and (ii) learning mechanism leveraging model confidence for self-training. As an application, we focus on text classification on five benchmark datasets. We show our uncertainty-aware few-shot self-training method leveraging only 20-30 labeled samples per class for each task can perform within 3% of fully supervised pre-trained language models like BERT fine-tuned on thousands of labeled instances with an aggregate accuracy of 91% and improving by up to 12% over baselines.
Related Tools
Uncertainty-aware Self-training for Few-shot Text Classification (code)
November 17, 2020
Uncertainty-aware self-training (UST) for few-shot text classification with pre-trained language models. With only 20-30 labeled samples per class for each task, UST can perform similar to fully supervised pre-trained language models like BERT fine-tuned on thousands of labeled instances.