



Generative AI systems are made up of multiple components that interact to provide a rich user experience between the human and the AI model(s). As part of a responsible AI approach, AI models are protected by layers of defense mechanisms to prevent the production of harmful content or being used to carry out instructions that go against the intended purpose of the AI integrated application. This blog will provide an understanding of what AI jailbreaks are, why generative AI is susceptible to them, and how you can mitigate the risks and harms.
What is AI jailbreak?
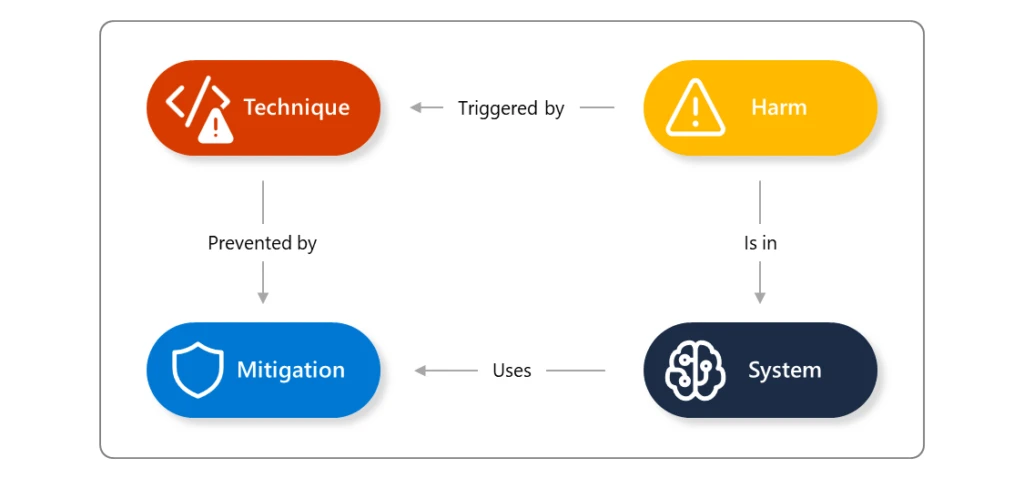
An AI jailbreak is a technique that can cause the failure of guardrails (mitigations). The resulting harm comes from whatever guardrail was circumvented: for example, causing the system to violate its operators’ policies, make decisions unduly influenced by one user, or execute malicious instructions. This technique may be associated with additional attack techniques such as prompt injection, evasion, and model manipulation. You can learn more about AI jailbreak techniques in our AI red team’s Microsoft Build session, How Microsoft Approaches AI Red Teaming.
Here is an example of an attempt to ask an AI assistant to provide information about how to build a Molotov cocktail (firebomb). We know this knowledge is built into most of the generative AI models available today, but is prevented from being provided to the user through filters and other techniques to deny this request. Using a technique like Crescendo, however, the AI assistant can produce the harmful content that should otherwise have been avoided. This particular problem has since been addressed in Microsoft’s safety filters; however, AI models are still susceptible to it. Many variations of these attempts are discovered on a regular basis, then tested and mitigated.
Why is generative AI susceptible to this issue?
When integrating AI into your applications, consider the characteristics of AI and how they might impact the results and decisions made by this technology. Without anthropomorphizing AI, the interactions are very similar to the issues you might find when dealing with people. You can consider the attributes of an AI language model to be similar to an eager but inexperienced employee trying to help your other employees with their productivity:
- Over-confident: They may confidently present ideas or solutions that sound impressive but are not grounded in reality, like an overenthusiastic rookie who hasn’t learned to distinguish between fiction and fact.
- Gullible: They can be easily influenced by how tasks are assigned or how questions are asked, much like a naïve employee who takes instructions too literally or is swayed by the suggestions of others.
- Wants to impress: While they generally follow company policies, they can be persuaded to bend the rules or bypass safeguards when pressured or manipulated, like an employee who may cut corners when tempted.
- Lack of real-world application: Despite their extensive knowledge, they may struggle to apply it effectively in real-world situations, like a new hire who has studied the theory but may lack practical experience and common sense.
In essence, AI language models can be likened to employees who are enthusiastic and knowledgeable but lack the judgment, context understanding, and adherence to boundaries that come with experience and maturity in a business setting.
So we can say that generative AI models and system have the following characteristics:
- Imaginative but sometimes unreliable
- Suggestible and literal-minded, without appropriate guidance
- Persuadable and potentially exploitable
- Knowledgeable yet impractical for some scenarios
Without the proper protections in place, these systems can not only produce harmful content, but could also carry out unwanted actions and leak sensitive information.
Due to the nature of working with human language, generative capabilities, and the data used in training the models, AI models are non-deterministic, i.e., the same input will not always produce the same outputs. These results can be improved in the training phases, as we saw with the results of increased resilience in Phi-3 based on direct feedback from our AI Red Team. As all generative AI systems are subject to these issues, Microsoft recommends taking a zero-trust approach towards the implementation of AI; assume that any generative AI model could be susceptible to jailbreaking and limit the potential damage that can be done if it is achieved. This requires a layered approach to mitigate, detect, and respond to jailbreaks. Learn more about our AI Red Team approach.
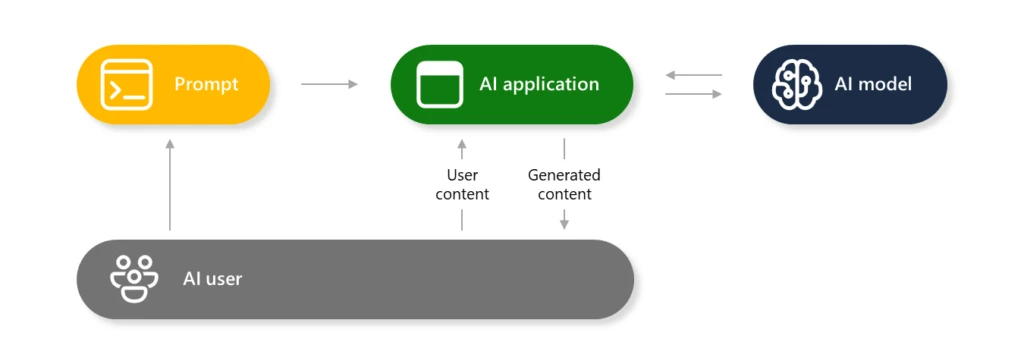
What is the scope of the problem?
When an AI jailbreak occurs, the severity of the impact is determined by the guardrail that it circumvented. Your response to the issue will depend on the specific situation and if the jailbreak can lead to unauthorized access to content or trigger automated actions. For example, if the harmful content is generated and presented back to a single user, this is an isolated incident that, while harmful, is limited. However, if the jailbreak could result in the system carrying out automated actions, or producing content that could be visible to more than the individual user, then this becomes a more severe incident. As a technique, jailbreaks should not have an incident severity of their own; rather, severities should depend on the consequence of the overall event (you can read about Microsoft’s approach in the AI bug bounty program).
Here are some examples of the types of risks that could occur from an AI jailbreak:
- AI safety and security risks:
- Unauthorized data access
- Sensitive data exfiltration
- Model evasion
- Generating ransomware
- Circumventing individual policies or compliance systems
- Responsible AI risks:
- Producing content that violates policies (e.g., harmful, offensive, or violent content)
- Access to dangerous capabilities of the model (e.g., producing actionable instructions for dangerous or criminal activity)
- Subversion of decision-making systems (e.g., making a loan application or hiring system produce attacker-controlled decisions)
- Causing the system to misbehave in a newsworthy and screenshot-able way
- IP infringement
How do AI jailbreaks occur?
The two basic families of jailbreak depend on who is doing them:
- A “classic” jailbreak happens when an authorized operator of the system crafts jailbreak inputs in order to extend their own powers over the system.
- Indirect prompt injection happens when a system processes data controlled by a third party (e.g., analyzing incoming emails or documents editable by someone other than the operator) who inserts a malicious payload into that data, which then leads to a jailbreak of the system.
You can learn more about both of these types of jailbreaks here.
There is a wide range of known jailbreak-like attacks. Some of them (like DAN) work by adding instructions to a single user input, while others (like Crescendo) act over several turns, gradually shifting the conversation to a particular end. Jailbreaks may use very “human” techniques such as social psychology, effectively sweet-talking the system into bypassing safeguards, or very “artificial” techniques that inject strings with no obvious human meaning, but which nonetheless could confuse AI systems. Jailbreaks should not, therefore, be regarded as a single technique, but as a group of methodologies in which a guardrail can be talked around by an appropriately crafted input.
Mitigation and protection guidance
To mitigate the potential of AI jailbreaks, Microsoft takes defense in depth approach when protecting our AI systems, from models hosted on Azure AI to each Copilot solution we offer. When building your own AI solutions within Azure, the following are some of the key enabling technologies that you can use to implement jailbreak mitigations:
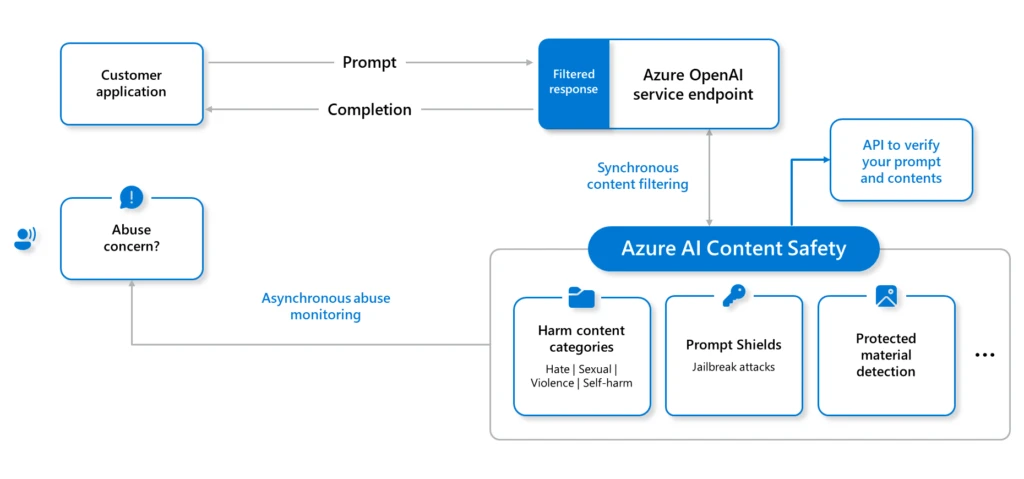
- Prompt filtering: Prompt Shields in Azure AI Content Safety
- Identity management: Managed identities for Azure resources
- Data access controls: Microsoft Purview data security for generative AI apps
- System metaprompt: System message framework and template recommendations for large language models (LLMs)
- Content filtering: Azure OpenAI Service content filtering
- Abuse monitoring: Azure OpenAI Service abuse monitoring
- Model alignment during training: Microsoft Azure AI Fundamentals: Generative AI – Training
- Threat protection: Microsoft Defender for Cloud threat protection for AI workloads
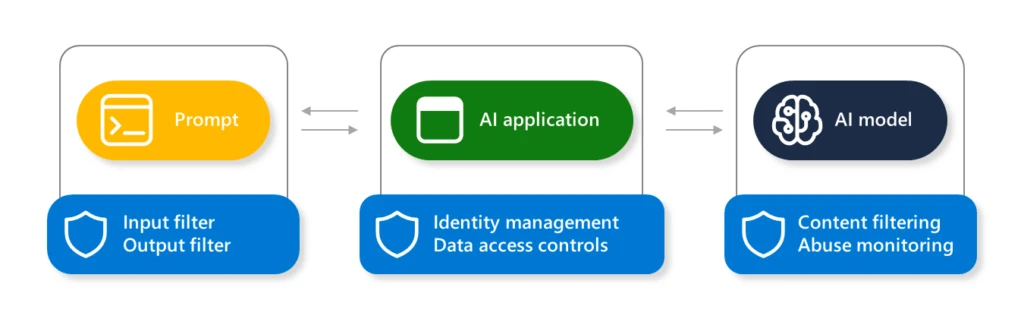
With layered defenses, there are increased chances to mitigate, detect, and appropriately respond to any potential jailbreaks.
To empower security professionals and machine learning engineers to proactively find risks in their own generative AI systems, Microsoft has released an open automation framework, Python Risk Identification Toolkit for generative AI (PyRIT). Read more about the release of PyRIT for generative AI Red teaming, and access the PyRIT toolkit on GitHub.
When building solutions on Azure AI, use the Azure AI Studio capabilities to build benchmarks, create metrics, and implement continuous monitoring and evaluation for potential jailbreak issues.
If you discover new vulnerabilities in any AI platform, we encourage you to follow responsible disclosure practices for the platform owner. Microsoft’s procedure is explained here: Microsoft AI Bounty Program.
Detection guidance
Microsoft builds multiple layers of detections into each of our AI hosting and Copilot solutions.
To detect attempts of jailbreak in your own AI systems, you should ensure you have enabled logging and are monitoring interactions in each component, especially the conversation transcripts, system metaprompt, and the prompt completions generated by the AI model.
Microsoft recommends setting the Azure AI Content Safety filter severity threshold to the most restrictive options, suitable for your application. You can also use Azure AI Studio to begin the evaluation of your AI application safety with the following guidance: Evaluation of generative AI applications with Azure AI Studio.
Summary
This article provides the foundational guidance and understanding of AI jailbreaks. In future blogs, we will explain the specifics of any newly discovered jailbreak techniques. Each one will articulate the following key points:
- We will describe the jailbreak technique discovered and how it works, with evidential testing results.
- We will have followed responsible disclosure practices to provide insights to the affected AI providers, ensuring they have suitable time to implement mitigations.
- We will explain how Microsoft’s own AI systems have been updated to implement mitigations to the jailbreak.
- We will provide detection and mitigation information to assist others to implement their own further defenses in their AI systems.
Richard Diver
Microsoft Security
Learn more
For the latest security research from the Microsoft Threat Intelligence community, check out the Microsoft Threat Intelligence Blog: https://aka.ms/threatintelblog.
To get notified about new publications and to join discussions on social media, follow us on LinkedIn at https://www.linkedin.com/showcase/microsoft-threat-intelligence, and on X (formerly Twitter) at https://twitter.com/MsftSecIntel.
To hear stories and insights from the Microsoft Threat Intelligence community about the ever-evolving threat landscape, listen to the Microsoft Threat Intelligence podcast: https://thecyberwire.com/podcasts/microsoft-threat-intelligence.




