
How to develop and submit Spark jobs to SQL Server Big Data Clusters in IntelliJ
We’re delighted to release the Azure Toolkit for IntelliJ support for SQL Server Big Data Cluster Spark job development and submission. For first-time Spark developers, it can often be hard to get started and build their first application, with long and tedious development cycles in the integrated development environment (IDE). This toolkit empowers new users to get started with Spark in just a few minutes. Experienced Spark developers also find it faster and easier to iterate their development cycle.
The toolkit extends IntelliJ support for the Spark job life cycle starting from creation, authoring, and debugging, through submission of jobs to SQL Server Big Data Clusters. It enables you to enjoy a native Scala and Java Spark application development experience and quickly start a project using built-in templates and sample code. The integration with SQL Server Big Data Cluster empowers you to quickly submit a job to the big data cluster as well as monitor its progress. The Spark console allows you to check schemas, preview data, and validate your code logic in a shell-like environment while you can develop Spark batch jobs within the same toolkit.
The Azure Toolkit for IntelliJ offers the following capabilities:
- Connect to SQL Server Big Data Clusters and submit Spark jobs for execution.
- Create a Spark project using built-in templates, sample code, intelligent auto-creation of artifacts, and help locating assemblies.
- Integrate with Maven and SBT to automatically download library dependencies.
- Develop Spark applications with native authoring support (e.g. IntelliSense, auto format, and error checking) from IntelliJ.
- Locally run and debug Spark applications.
- Stop a running Spark application before its completion.
- Test and validate the Spark application locally or against a big data cluster.
- Integrate with Spark History Server to view job history, debug, and diagnose Spark jobs.
Highlights of Key Features
Integration with SQL Server
This toolkit enables you to connect and submit Spark jobs to Azure SQL Server Big Data Cluster, and navigate your SQL Server data and files.
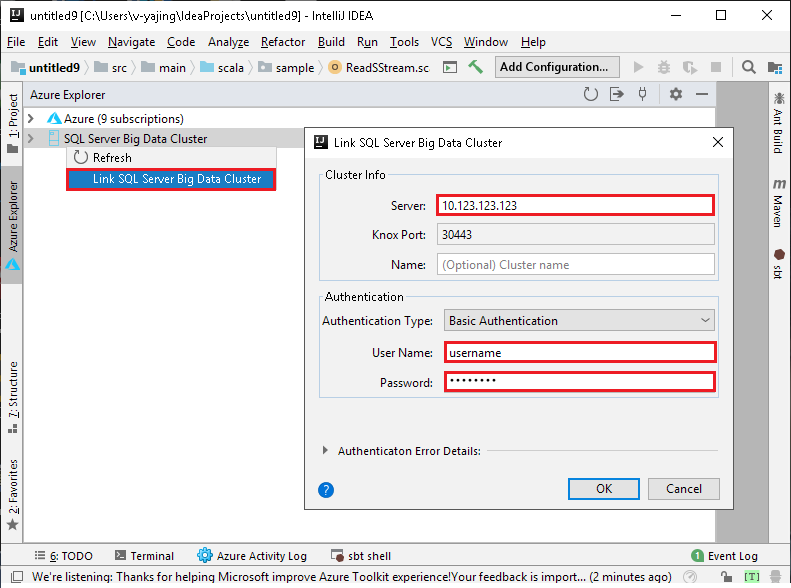
Create, author, submit, and stop a Spark application
To create a new Spark application using Azure toolkit for IntelliJ, you can leverage the template to create and author a Spark job with sample code and built-in integrations with Maven and SBT.

Next you can submit a Spark application and identify the job submission target cluster, job parameters, and add references in the configuration dialog.
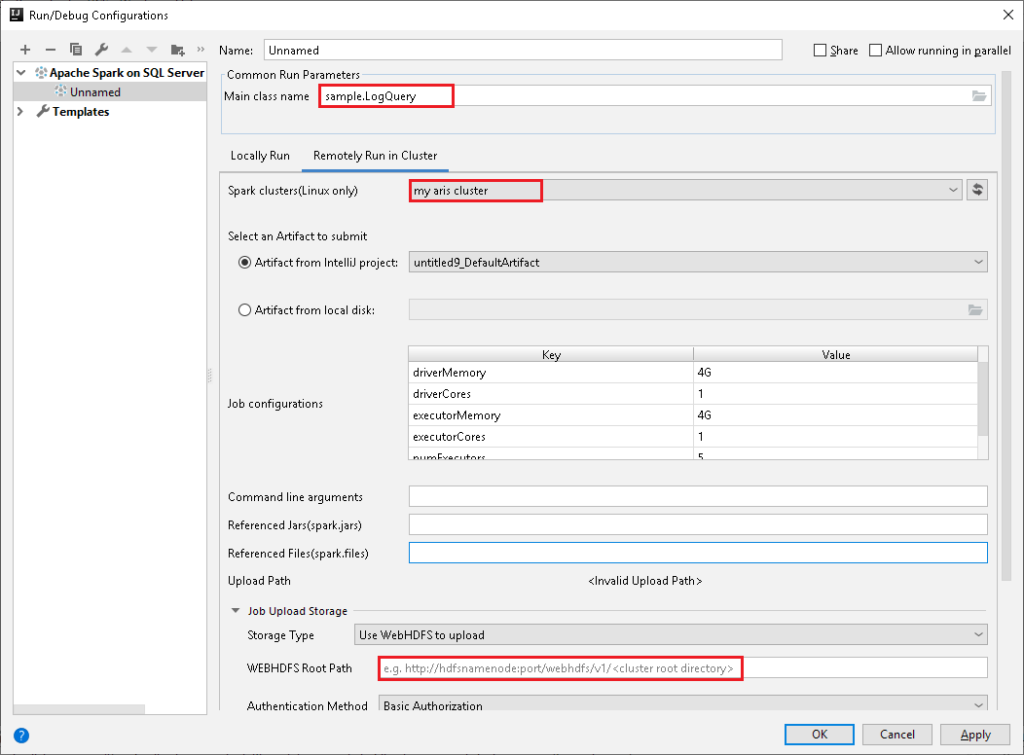
Stop Spark applications from IntelliJ UI: After your Spark job submission, you can stop running a Spark application in IntelliJ before its completion.
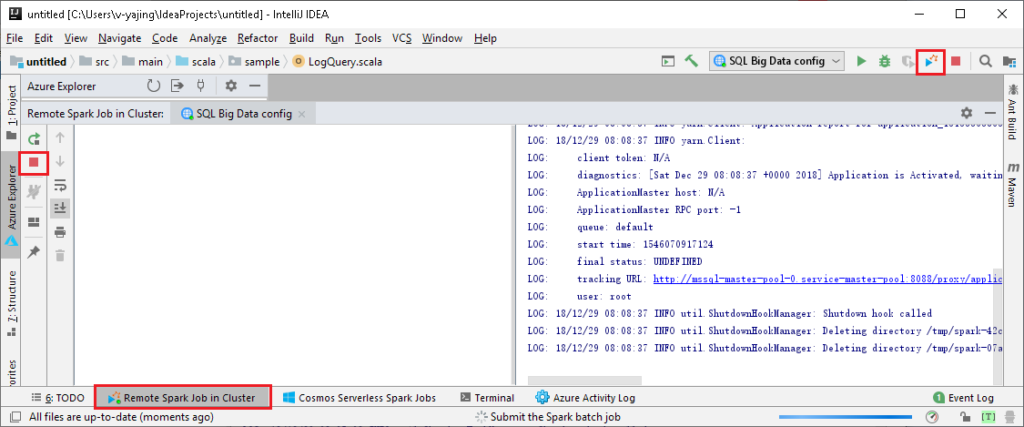
Spark Console
This component facilitates Spark job authoring and enables you to run code interactively in a shell-like environment including Spark Local Console and Spark Livy Interactive Sessions.
The Spark local console allows you to run your code interactively and validate your code logic locally. You can also check your programming variables and perform other scripting operations locally before submitting to the cluster. The Spark Livy interactive session establishes an interactive communication channel with your cluster so you can check on file schemas, preview data, and run ad-hoc queries while you’re programming your Spark job.
The Spark console has a Language Service built-in for Scala programming. You can leverage the language service features such as IntelliSense and autocomplete, to look up a Spark object (i.e., Spark context and Spark session) properties, query hive metadata, and check on function signatures. The Send Selection to Spark Console (Ctrl + Shift + S) feature simplifies the user experience for accessing the Spark console. You can send a highlighted single line of code or a block of code to the console from your main Scala project. This feature enables you to switch smoothly between contexts from coding and validation or testing code in the Spark console.
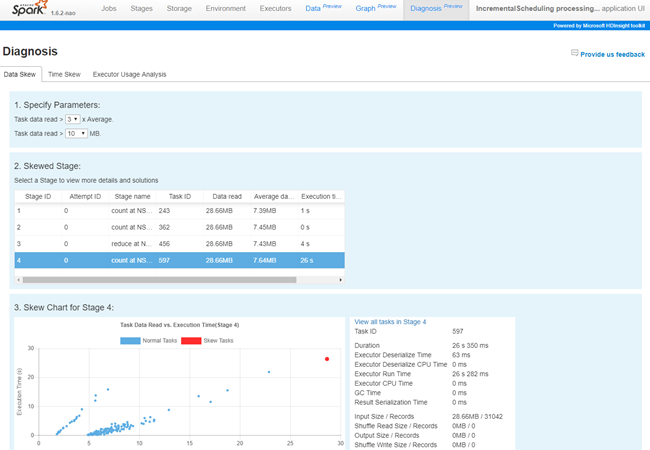
Spark job debug & diagnosis
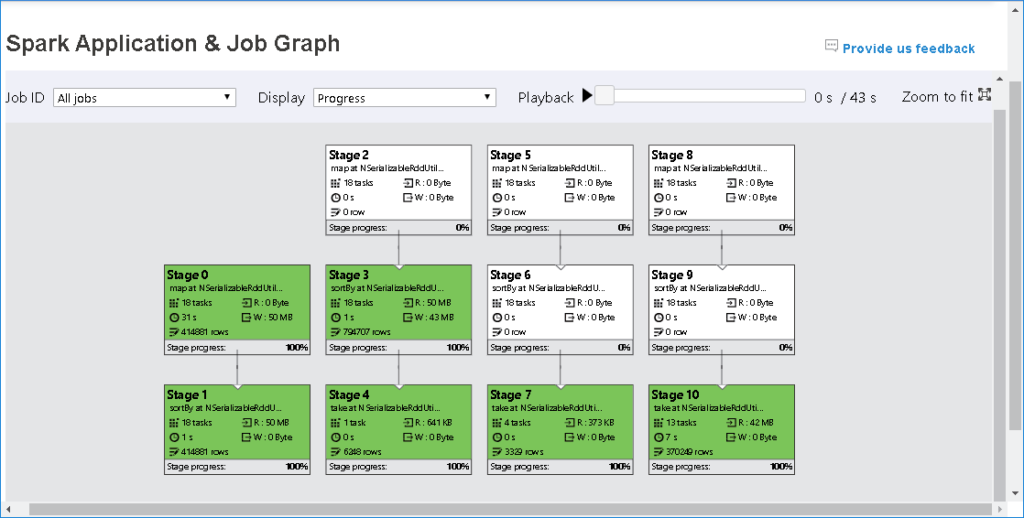
In this release, Microsoft brings many of its learnings from running and debugging millions of its own big data jobs to the open source world of Apache SparkTM. Azure Toolkit integrates with the enhanced SQL Server Big Data Cluster Spark history server with interactive visualization of job graphs, data flows, and job diagnosis. The new features assist SQL Server Big Data Spark developers to:
- View and play back Spark application/job graph pivoting on execution progress, or data read and written.
- Identify the Spark application execution dependencies among stages and jobs for performance tuning.
- Simplify performance diagnosis through data read/write heatmaps, and identify performance outliers as well as bottleneck stages and jobs.
- View Spark jobs and stage data input/output size and time duration for performance optimization.
- Detect and view data or time skew for stage tasks.
- View executor allocation and utilization.
- Preview and download Spark job input and output data, as well as view Spark job table operations.
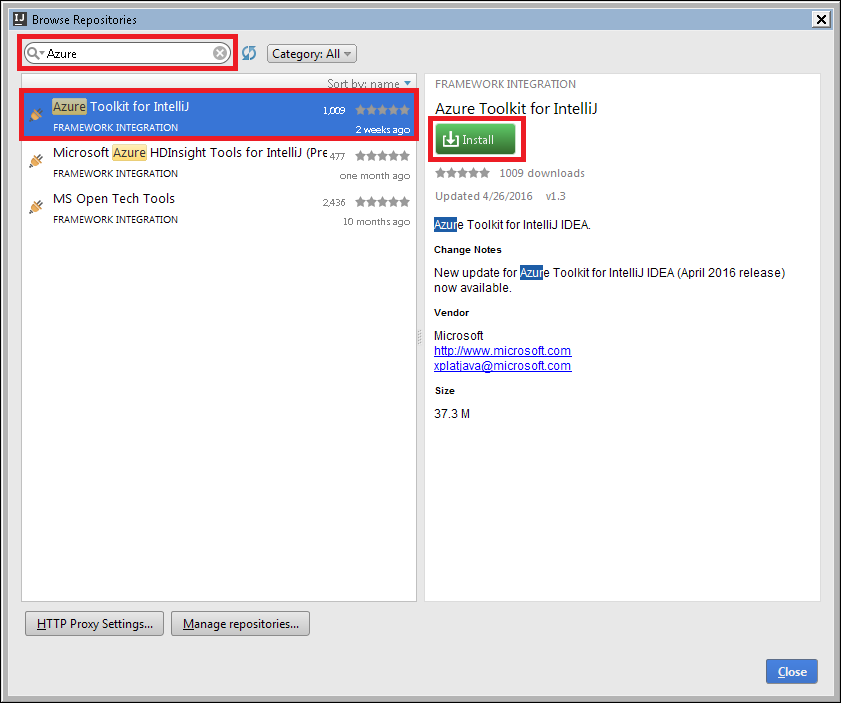
How to install
Please install IntelliJ 2018.3 version. You can get the latest details by going to the IntelliJ repository and searching Spark or Azure Toolkit for IntelliJ.
Read more:
