
Bringing AI translation to edge devices with Microsoft Translator
In November 2016, Microsoft brought the benefit of AI-powered machine translation, aka Neural Machine Translation (NMT), to developers and end users alike. Last week, Microsoft brought NMT capability to the edge of the cloud by leveraging the NPU, an AI-dedicated processor integrated into the Mate 10, Huawei’s latest flagship phone. The new chip makes AI-powered translations available on the device even in the absence of internet access, enabling the system to produce translations whose quality is on par with the online system.
To achieve this breakthrough, researchers and engineers from Microsoft and Huawei collaborated in adapting neural translation to this new computing environment.
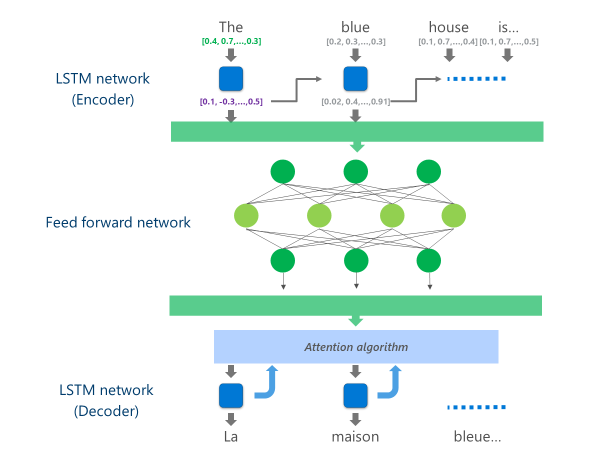
The most advanced NMT systems currently in production (i.e., used at scale in the cloud by businesses and apps) are using a neural network architecture combining multiple layers of LSTM networks, an attention algorithm, and a translation (decoder) layer.
The animation below explains, in a simplified way, how this multi-layer neural network functions. For more details, please refer to the “what is machine translation page” on the Microsoft Translator site.

In this cloud NMT implementation, these middle LSTM layers consume a large part of the computing power. To be able to run full NMT on a mobile device, it was necessary to find a mechanism that could reduce these computational costs while preserving, as much as possible, the translation quality.
This is where Huawei’s Neural Processing Unit (NPU) comes into play. Microsoft researchers and engineers took advantage of the NPU, which is specifically engineered to excel at low-latency AI computations, to offload operations that would have been unacceptably slow to process on the main CPU.
Implementation
The implementation now available on the Microsoft Translator app for the Huawei Mate 10 optimizes translation by offloading the most compute-intensive tasks to the NPU.
Specifically, this implementation replaces these middle LSTM network layers by a deep feed-forward neural network. Deep feed-forward neural networks are powerful but require very large amounts of computation due to the high connectivity among neurons.
Neural networks rely primarily on matrix multiplications, an operation that is not complex from a mathematical standpoint but very expensive when performed at the scale required for such a deep neural network. The Huawei NPU excels in performing these matrix multiplications in a massively parallel fashion. It is also quite efficient from a power utilization standpoint, an important quality on battery powered devices.
At each layer of this feed-forward network, the NPU computes both the raw neuron output and the subsequent ReLu activation function efficiently and with very low latency. By leveraging the ample high-speed memory on the NPU, it performs these computations in parallel without having to pay the cost for data transfer (i.e., slowing down performance) between the CPU and the NPU.
Once the final layer of this deep feed-forward network is computed, the system has a rich representation of the source language sentence. This representation is then fed through a left-to-right LSTM “decoder” to produce each target language word, with the same attention algorithm used in the online version of the NMT.
As Anthony Aue, a Principal Software Development Engineer in the Microsoft Translator team explains: “taking a system that runs on powerful cloud servers in a data center and running it unchanged on a mobile phone is not a viable option. Mobile devices have limitations in computing power, memory, and power usage that cloud solutions do not have. Having access to the NPU, along with some other architectural tweaks, allowed us to work around many of these limitations and to design a system that can run quickly and efficiently on-device without having to compromise translation quality.”

The implementation of these translation models on the innovative NPU chipset allowed Microsoft and Huawei to deliver on-device neural translation at a quality comparable to that of cloud-based systems even when you are off the grid.



