
Trazendo a tradução com IA para dispositivos de ponta com o Microsoft Translator
Em novembro de 2016, a Microsoft trouxe o benefício da tradução automática alimentada por IA, também conhecida como Neural Machine Translation (NMT), para desenvolvedores e usuários finais. Semana passada, A Microsoft trouxe o recurso NMT para a borda da nuvem aproveitando a NPU, um processador dedicado à IA integrado ao Mate 10O novo chip da Huawei é o mais recente telefone carro-chefe da Huawei. O novo chip torna as traduções baseadas em IA disponíveis no dispositivo mesmo na ausência de acesso à Internet, permitindo que o sistema produza traduções com qualidade equivalente à do sistema on-line.
Para alcançar esse avanço, pesquisadores e engenheiros da Microsoft e da Huawei colaboraram na adaptação da tradução neural a esse novo ambiente de computação.
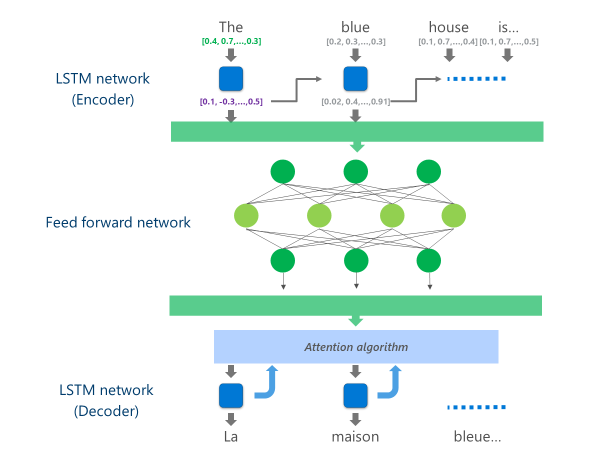
Os sistemas NMT mais avançados atualmente em produção (ou seja, usados em escala na nuvem por empresas e aplicativos) estão usando uma arquitetura de rede neural que combina várias camadas de Redes LSTMum algoritmo de atenção e uma camada de tradução (decodificador).
A animação abaixo explica, de forma simplificada, como funciona essa rede neural multicamadas. Para obter mais detalhes, consulte a seção "o que é a página de tradução automática" no site do Microsoft Translator.

Nessa implementação de NMT na nuvem, essas camadas LSTM intermediárias consomem grande parte do poder de computação. Para poder executar o NMT completo em um dispositivo móvel, foi necessário encontrar um mecanismo que pudesse reduzir esses custos de computação e, ao mesmo tempo, preservar, tanto quanto possível, a qualidade da tradução.
É aqui que a Unidade de Processamento Neural (NPU) da Huawei entra em ação. Os pesquisadores e engenheiros da Microsoft aproveitaram a NPU, que foi projetada especificamente para se destacar em cálculos de IA de baixa latência, para descarregar operações que teriam sido inaceitavelmente lentas para processar na CPU principal.
Implementação
A implementação agora disponível no aplicativo Microsoft Translator para o Huawei Mate 10 otimiza a tradução, transferindo as tarefas mais intensas de computação para a NPU.
Especificamente, essa implementação substitui essas camadas intermediárias da rede LSTM por uma camada profunda de fRede neural de avanço gradual. As redes neurais profundas feed-forward são poderosas, mas exigem quantidades muito grandes de computação devido à alta conectividade entre os neurônios.
As redes neurais dependem principalmente de multiplicações de matrizes, uma operação que não é complexa do ponto de vista matemático, mas muito cara quando realizada na escala necessária para uma rede neural profunda. A NPU da Huawei se destaca na execução dessas multiplicações de matrizes de forma maciçamente paralela. Ela também é bastante eficiente do ponto de vista da utilização de energia, uma qualidade importante em dispositivos alimentados por bateria.
Em cada camada dessa rede feed-forward, a NPU calcula a saída bruta do neurônio e a saída subsequente do neurônio. Função de ativação ReLu de forma eficiente e com latência muito baixa. Ao aproveitar a ampla memória de alta velocidade na NPU, ele executa esses cálculos em paralelo sem precisar pagar o custo da transferência de dados (ou seja, diminuindo o desempenho) entre a CPU e a NPU.
Quando a camada final dessa rede de alimentação profunda é calculada, o sistema tem uma representação rica da frase do idioma de origem. Essa representação é então alimentada por um "decodificador" LSTM da esquerda para a direita para produzir cada palavra do idioma de destino, com o mesmo algoritmo de atenção usado na versão on-line do NMT.
Como Anthony Aue, engenheiro principal de desenvolvimento de software da equipe do Microsoft Translator, explica: "Pegar um sistema que é executado em poderosos servidores de nuvem em um data center e executá-lo inalterado em um telefone celular não é uma opção viável. Os dispositivos móveis têm limitações de capacidade de computação, memória e uso de energia que as soluções em nuvem não têm. Ter acesso à NPU, juntamente com alguns outros ajustes de arquitetura, nos permitiu contornar muitas dessas limitações e projetar um sistema que pode ser executado de forma rápida e eficiente no dispositivo sem comprometer a qualidade da tradução."

A implementação desses modelos de tradução no inovador chipset NPU permitiu que a Microsoft e a Huawei fornecessem tradução neural no dispositivo com uma qualidade comparável à dos sistemas baseados em nuvem, mesmo quando você está fora da rede.



