
Bing 的性別翻譯解決了翻譯中的偏見問題

我們很高興地宣布,從今天開始,從英文翻譯成西班牙文、法文或義大利文時,可以使用男性和女性的替代翻譯。您可以在以下兩種語言中試用這項新功能 必應搜索 和 必應翻譯器 縱向。
在過去的幾年裡,機器翻譯 (MT) 領域因為轉換器模型的出現而發生了革命性的變化,使得品質得到了巨大的改善。然而,為了捕捉從真實世界中收集的資料的統計特性而優化的模型,卻會在不經意之間學習甚至擴大該資料中的社會偏見。
我們最新的版本朝著減少其中一項偏差邁進了一步,特別是 MT 系統中普遍存在的性別偏差。Bing Translator 總是為輸入句子產生單一翻譯,即使翻譯可能有其他性別變異,包括女性和男性變異。根據 微軟負責任的 AI 原則我們希望確保我們提供正確的替代翻譯,並對所有性別更具包容性。作為這個過程的一部分,我們的第一步是提供女性和男性的翻譯變體。
性別在不同的語言中有不同的表達方式。例如,在英語中,lawyer(律師)一詞可以指男性或女性個人,但在西班牙語中、 女監護人 指女性律師,而 律師 是指男性。在缺乏來源句子中類似「lawyer」的名詞性別資訊的情況下,MT 模型可能會為目標語言中的名詞選擇任意的性別。通常情況下,這些任意的性別指定與刻板印象一致,使有害的社會偏見持續存在(Stanovsky 等人,2019 年;Ciora 等人,2021 年),並導致翻譯不完全準確。
在下面的例子中,您注意到在將性別中立的句子從英文翻譯成西班牙文時,翻譯的文字遵循了刻板的性別角色,即律師被翻譯成是男性。
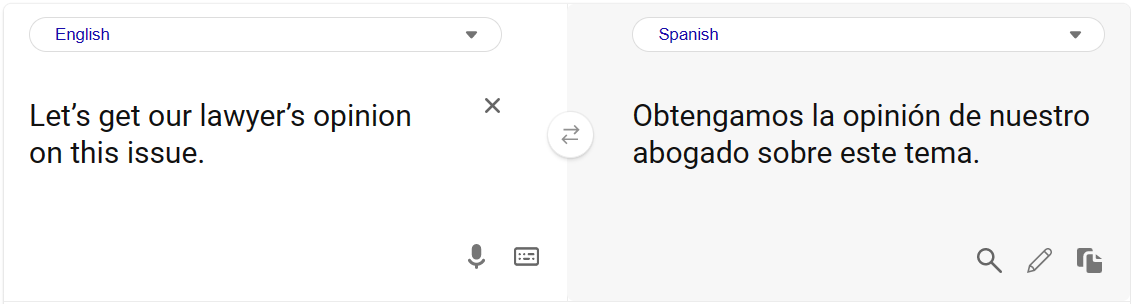
由於源句中沒有暗示律師性別的上下文,因此假設是男性或女性律師的翻譯都是有效的。現在,Bing Translator 可提供女性和男性形式的翻譯。
系統設計
我們的目標是設計我們的系統,以符合下列提供有性別選擇的主要標準:
- 除了傳達性別所需的差異外,女性和男性變體應有最小的差異。
- 我們希望涵蓋範圍廣泛的句子,在這些句子中可能有多種性別選擇。
- 我們希望確保翻譯能保留原始原始句子的意義。
偵測性別歧義
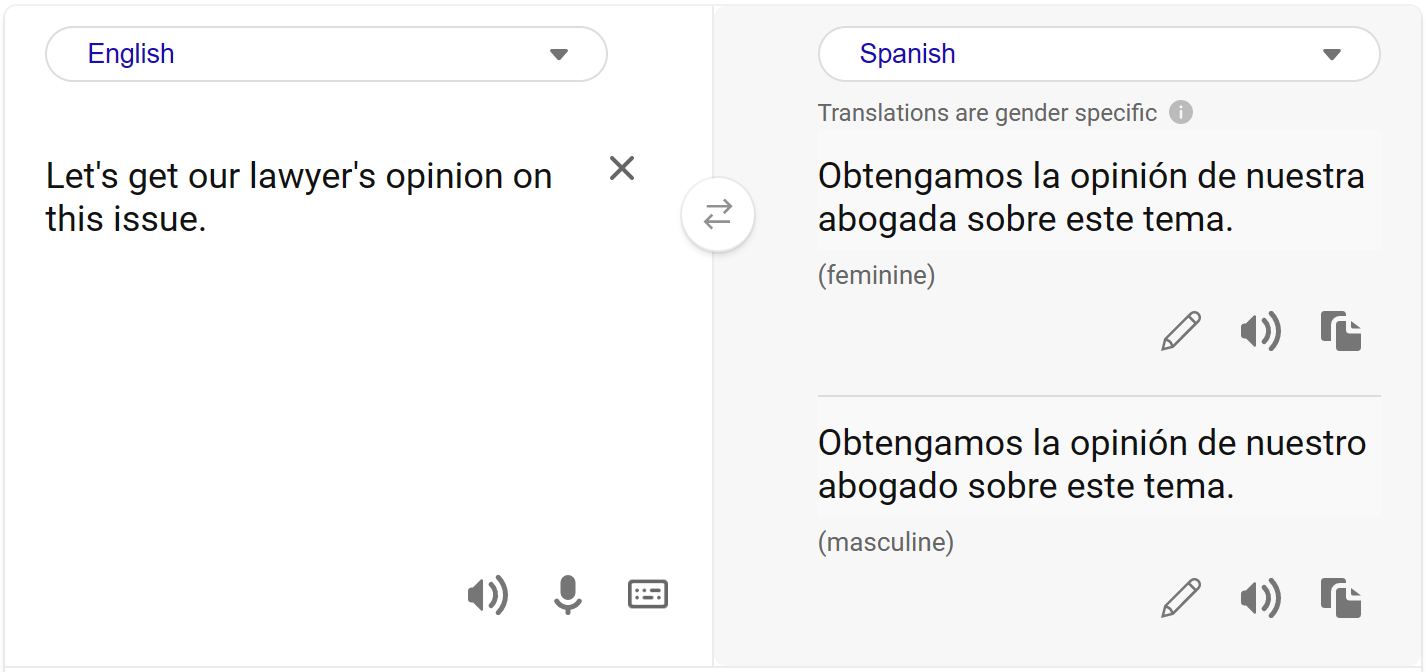
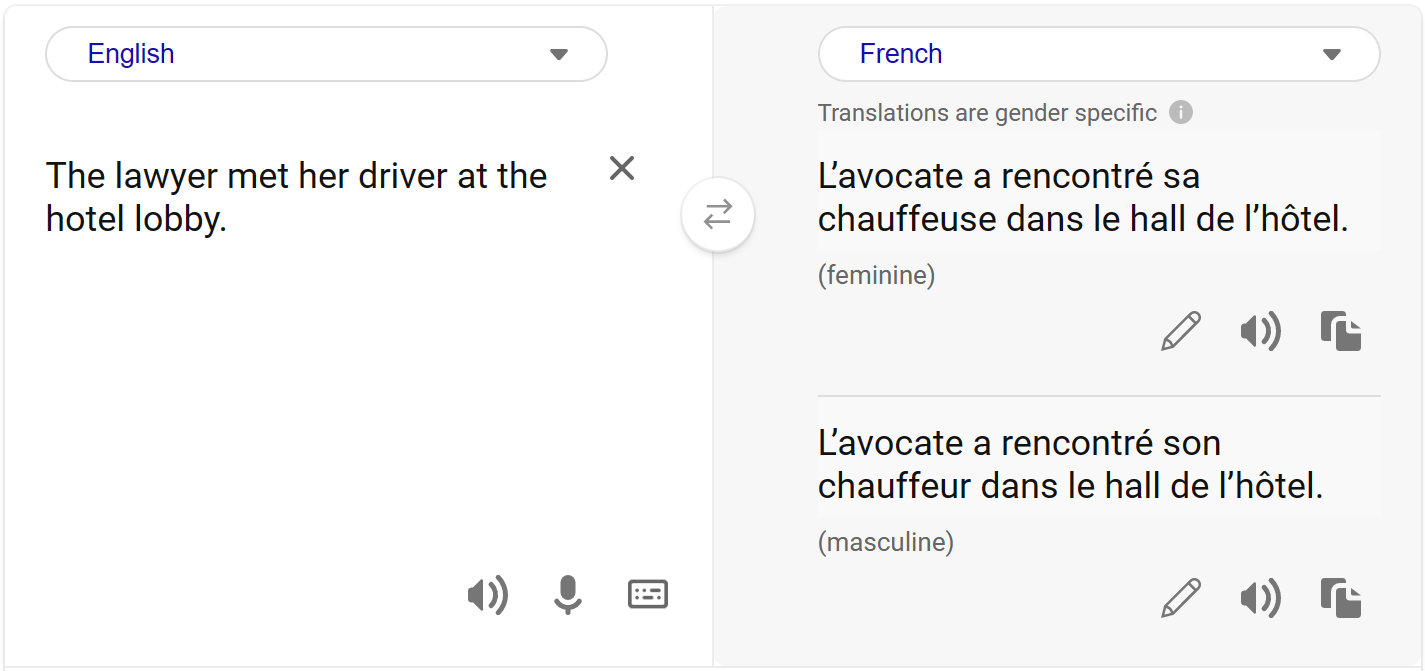
為了準確偵測來源文字中的性別歧義,我們利用核心推理模型來分析含有動態名詞的輸入文字。舉例來說,如果給定的輸入文字包含性別中性的專業字詞,我們只會在句子中的其他資訊無法判定其性別時,才提供有性別的替代字詞。舉例來說:將英文句子「The lawyer met her driver at the hotel lobby.」翻譯成法文時,我們可以判定律師是女性,而駕駛員的性別不明。
產生替代翻譯
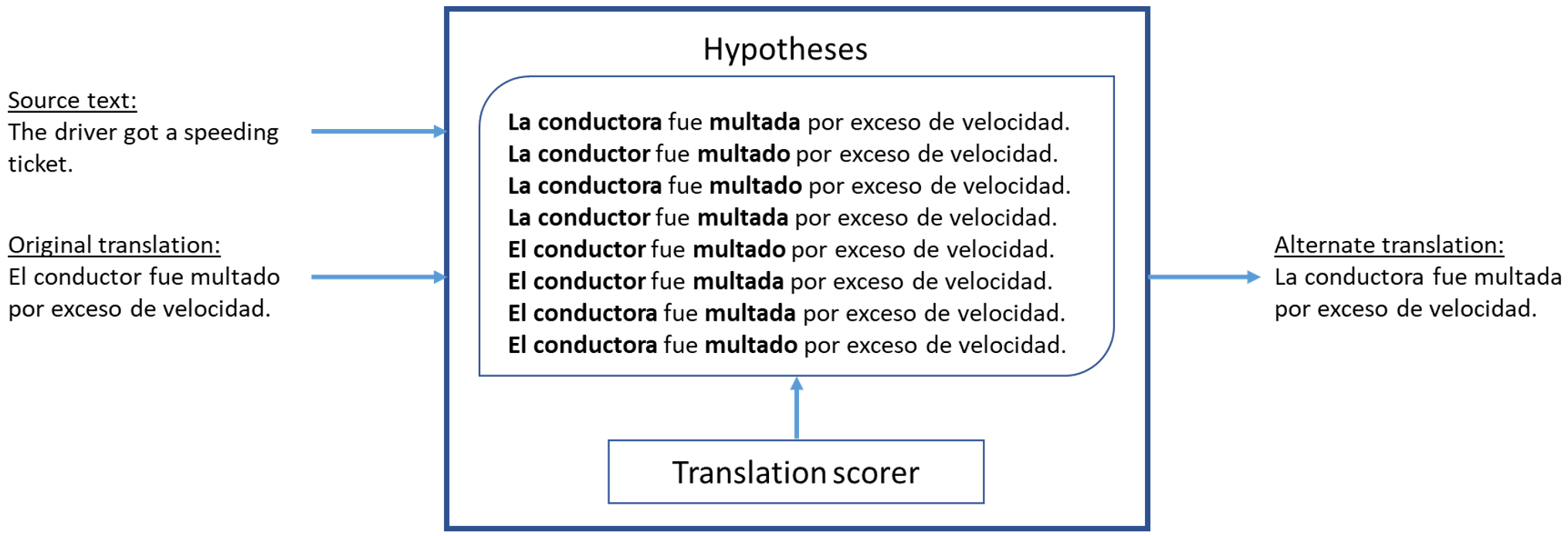
當原始句子的性別含糊不清時,我們會檢查翻譯系統的輸出,以決定是否可能有其他性別解釋。如果是的話,我們就開始決定修改翻譯的最佳方式。我們首先透過重寫原始譯文來建構一組候選目標譯文。我們應用基於依存關係的語言約束,以確保建議替代方案的一致性,並刪除錯誤的候選方案。
然而,在許多情況下,即使運用了我們的限制條件,我們仍有多個候選的有性別替代翻譯的重寫方案。為了決定最佳方案,我們會使用翻譯模型為每個候選方案評分。由於良好的性別重寫也是源句的精確翻譯,因此我們能夠確保最終輸出的高準確性。
在 Azure Machine Learning 中利用受管理的線上端點
Bing 中的性別替代功能託管於 管理的線上端點 中的 Azure Machine Learning。受管理的線上端點提供了統一的介面,讓我們可以在 Microsoft 管理的運算上,以交鑰匙的方式調用和管理模型部署。它們讓我們能夠利用可擴充和可靠的端點,而無需擔心基礎架構管理。這種推論環境也能以低延遲處理大量的請求。透過使用 Azure Machine Learning 中受管理的推論功能,我們使用最新框架和技術建立和部署性別 debias 服務的能力大幅提升。透過利用這些功能,我們得以維持低 COGS(銷售成本),並確保直接符合安全性與隱私權規範。
您可以如何做出貢獻?
為了促進 MT 在減少性別偏見方面的進展,我們將發布一個測試語料庫,其中包含從英文翻譯成西班牙文、法文和義大利文的性別明確翻譯範例。每個英文原始句子都附有多個翻譯,涵蓋每個可能的性別變化。
我們的測試集具有挑戰性、字形豐富且語言多元。這個語料庫在我們的開發過程中扮演了重要的角色。它是在具有豐富翻譯經驗的雙語語言學家的協助下開發的。我們還發表了一篇技術論文,詳細討論了測試語料以及評估的方法和工具。
未來路徑
透過這項工作,我們的目標是在來源性別含糊不清的情況下,改善 MT 輸出的品質,並促進更好、更包容的自然語言處理 (NLP) 工具的整體發展。我們最初的版本著重於從英文翻譯成西班牙文、法文和義大利文。展望未來,我們計畫擴展到新的語言對,以及涵蓋更多的情境和偏差類型。
功勞:
Ranjita Naik、Spencer Rarrick、Sundar Poudel、Varun Mathur、Jeshwanth Kumar Chandrala、Charan Mohan、Lee Schwartz、Steven Nguyen、Amit Bhagwat、Vishal Chowdhary。



