
Masjien vertaling
Wat is masjienvertaling?
Masjienvertalingstelsels is toepassings of aanlyndienste wat masjienleertegnologieë gebruik om groot hoeveelhede teks uit en na enige van hul ondersteunde tale te vertaal. Die diens vertaal 'n "bron" teks van een taal na 'n ander "teiken" taal.
Alhoewel die konsepte agter masjienvertalingstegnologie en die koppelvlakke om dit te gebruik relatief eenvoudig is, is die wetenskap en tegnologieë daaragter uiters kompleks en bring verskeie toonaangewende tegnologieë bymekaar, veral diep leer (kunsmatige intelligensie), groot data, taalkunde, wolkrekenaarkunde en web-API's.
Sedert die vroeë 2010's het 'n nuwe kunsmatige intelligensietegnologie, diep neurale netwerke (ook bekend as diep leer), die tegnologie van spraakherkenning in staat gestel om 'n kwaliteitsvlak te bereik wat die Microsoft Translator-span in staat gestel het om spraakherkenning met sy kernteksvertalingstegnologie te kombineer om 'n nuwe spraakvertalingstegnologie bekend te stel.
Histories was die primêre masjienleertegniek wat in die bedryf gebruik is Statistiese Masjienvertaling (SBS). SBS gebruik gevorderde statistiese analise om die beste moontlike vertalings vir 'n woord te skat gegewe die konteks van 'n paar woorde. SBS word sedert die middel van die 2000's deur alle groot vertaaldiensverskaffers, insluitend Microsoft, gebruik.
Die koms van Neural Machine Translation (NMT) het 'n radikale verskuiwing in vertaaltegnologie veroorsaak, wat vertalings van baie hoër gehalte tot gevolg gehad het. Hierdie vertaaltegnologie het begin ontplooi vir gebruikers en ontwikkelaars in die laaste deel van 2016.
Beide SBS- en NMT-vertaaltegnologieë het twee elemente gemeen:
- Albei benodig groot hoeveelhede pre-menslike vertaalde inhoud (tot miljoene vertaalde sinne) om die stelsels op te lei.
- Tree ook nie op as tweetalige woordeboeke nie, vertaal woorde op grond van 'n lys van potensiële vertalings, maar vertaal op grond van die konteks van die woord wat in 'n sin gebruik word.
Wat is vertaler?
Vertaler en Spraakdienste, deel van die Kognitiewe dienste versameling API's, is masjienvertalingsdienste van Microsoft.
Teksvertaling
Translator word sedert 2007 deur Microsoft-groepe gebruik en is sedert 2011 as 'n API vir kliënte beskikbaar. Vertaler word op groot skaal binne Microsoft gebruik. Dit word opgeneem in produklokalisering, ondersteuning en aanlynkommunikasiespanne. Dieselfde diens is ook toeganklik, sonder enige bykomende koste, van binne bekende Microsoft-produkte soos Bing, Cortana, Microsoft rand, Kantoor, SharePoint, SkypeEn Yammer.
Vertaler kan in web- of kliënttoepassings op enige hardewareplatform en met enige bedryfstelsel gebruik word om taalvertaling en ander taalverwante bewerkings soos taalopsporing, teks na spraak of woordeboek uit te voer.
Deur gebruik te maak van industriestandaard REST-tegnologie, stuur die ontwikkelaar bronteks (of klank vir spraakvertaling) na die diens met 'n parameter wat die teikentaal aandui, en die diens stuur die vertaalde teks terug vir die kliënt of webprogram om te gebruik.
Die Translator-diens is 'n Azure-diens wat in Microsoft-datasentrums aangebied word en trek voordeel uit die sekuriteit, skaalbaarheid, betroubaarheid en ononderbroke beskikbaarheid wat ander Microsoft-wolkdienste ook ontvang.
Spraak vertaling
Vertaler-spraakvertalingstegnologie is laat in 2014 bekendgestel, begin met Skype Translator, en is sedert vroeg in 2016 beskikbaar as 'n oop API vir kliënte. Dit is geïntegreer in die Microsoft Translator-regstreekse funksie, Skype, Skype-vergaderinguitsending en die Microsoft Translator-toepassings vir Android en iOS.
Spraakvertaling is nou beskikbaar deur Microsoft Speech, 'n end-to-end stel volledig aanpasbare dienste vir spraakherkenning, spraakvertaling en spraaksintese (teks-na-spraak).
Hoe werk teksvertaling?
Daar is twee hooftegnologieë wat vir teksvertaling gebruik word: die verouderde een, Statistical Machine Translation (SBS), en die nuwer generasie een, Neural Machine Translation (NMT).
Statistiese masjienvertaling
Vertaler se implementering van Statistiese Masjienvertaling (SBS) is gebou op meer as 'n dekade van natuurliketaalnavorsing by Microsoft. Eerder as om handgemaakte reëls te skryf om tussen tale te vertaal, benader moderne vertaalstelsels vertaling as 'n probleem om die transformasie van teks tussen tale uit bestaande menslike vertalings te leer en onlangse vooruitgang in toegepaste statistiek en masjienleer te benut.
Sogenaamde "parallelle korpora" dien as 'n moderne Rosetta-steen in groot verhoudings en verskaf woord-, frase- en idiomatiese vertalings in konteks vir baie taalpare en domeine. Statistiese modelleringstegnieke en doeltreffende algoritmes help die rekenaar om die probleem van ontsyfering aan te spreek (die opsporing van die ooreenkomste tussen bron- en doeltaal in die opleidingsdata) en dekodering (om die beste vertaling van 'n nuwe invoersin te vind). Vertaler verenig die krag van statistiese metodes met linguistiese inligting om modelle te produseer wat beter veralgemeen en tot meer verstaanbare vertalings lei.
As gevolg van hierdie benadering, wat nie op woordeboeke of grammatikale reëls staatmaak nie, bied dit die beste vertalings van frases waar dit die konteks rondom 'n gegewe woord kan gebruik teenoor om enkelwoordvertalings te probeer uitvoer. Vir enkelwoordvertalings is die tweetalige woordeboek ontwikkel en is toeganklik deur www.bing.com/translator.
Neurale masjien vertaling
Deurlopende verbeterings aan vertaling is belangrik. Prestasieverbeterings het egter sedert die middel van die 2010's met SBS-tegnologie platgeval. Deur gebruik te maak van die skaal en krag van Microsoft se AI-superrekenaar, spesifiek die Microsoft Cognitive Toolkit, bied Translator nou neurale netwerk (LSTM) gebaseerde vertaling wat 'n nuwe dekade van verbetering van vertaalgehalte moontlik maak.
Hierdie neurale netwerkmodelle is beskikbaar vir alle spraaktale deur spraakdiens op Azure en deur die teks-API deur die 'generalnn'-kategorie-ID te gebruik.
Neurale netwerkvertalings verskil fundamenteel in hoe dit uitgevoer word in vergelyking met die tradisionele SBS-vertalings.
Die volgende animasie beeld die verskillende stappe uit wat neurale netwerkvertalings deurgaan om 'n sin te vertaal. As gevolg van hierdie benadering sal die vertaling die volle sin in konteks neem, teenoor slegs 'n paar woorde se skuifvenster wat SBS-tegnologie gebruik en meer vloeibare en mensvertaalde vertalings sal lewer.
Op grond van die neurale netwerkopleiding word elke woord gekodeer langs 'n vektor van 500 dimensies (a) wat sy unieke eienskappe binne 'n bepaalde taalpaar (bv. Op grond van die taalpare wat vir opleiding gebruik word, sal die neurale netwerk self definieer wat hierdie dimensies moet wees. Hulle kan eenvoudige konsepte kodeer soos geslag (vroulik, manlik, neutraal), beleefdheidsvlak (slang, toevallig, geskryf, formeel, ens.), Tipe woord (werkwoord, selfstandige naamwoord, ens.), Maar ook enige ander nie-voor die hand liggende eienskappe soos afgelei uit die opleidingsdata.
Die stappe waardeur neurale netwerkvertalings gaan, is die volgende:
- Elke woord, of meer spesifiek die 500-dimensie vektor wat dit voorstel, gaan deur 'n eerste laag "neurone" wat dit sal kodeer in 'n 1000-dimensie vektor (b) wat die woord voorstel binne die konteks van die ander woorde in die sin.
- Sodra alle woorde een keer in hierdie 1000-dimensie vektore gekodeer is, word die proses verskeie kere herhaal, elke laag wat hierdie 1000-dimensie-voorstelling van die woord beter kan verfyn binne die konteks van die volle sin (in teenstelling met SBS-tegnologie wat slegs 'n venster van 3 tot 5 woorde in ag kan neem)
- Die finale uitsetmatriks word dan gebruik deur die aandaglaag (d.w.s. 'n sagteware-algoritme) wat beide hierdie finale uitsetmatriks en die uitset van voorheen vertaalde woorde sal gebruik om te definieer watter woord, uit die bronsin, volgende vertaal moet word. Dit sal ook hierdie berekeninge gebruik om onnodige woorde in die doeltaal moontlik te laat val.
- Die dekodeerder (vertaling) laag, vertaal die geselekteerde woord (of meer spesifiek die 1000-dimensie vektor wat hierdie woord binne die konteks van die volle sin voorstel) in sy mees geskikte teikentaalekwivalent. Die uitset van hierdie laaste laag (c) word dan weer in die aandaglaag gevoer om te bereken watter volgende woord uit die bronsin vertaal moet word.

In die voorbeeld wat in die animasie uitgebeeld word, is die konteksbewuste 1000-dimensiemodel van "Die" sal kodeer dat die selfstandige naamwoord (Huis) is 'n vroulike woord in Frans (La Maison). Dit sal die toepaslike vertaling vir "Die" om te wees "La" en nie "Le" (enkelvoud, manlik) of "Les" (meervoud) sodra dit die dekodeerder (vertaling) laag bereik.
Die aandagalgoritme sal ook bereken word, gebaseer op die woord (e) wat voorheen vertaal is (in hierdie geval "Die"), dat die volgende woord wat vertaal moet word, die onderwerp moet wees ("Huis") en nie 'n byvoeglike naamwoord nie ("Blou"). In kan dit bereik omdat die stelsel geleer het dat Engels en Frans die volgorde van hierdie woorde in sinne omkeer. Dit sou ook bereken het dat as die byvoeglike naamwoord "Groot" in plaas van 'n kleur, dat dit hulle nie moet omkeer nie ("Die groot huis" => "La Grande Maison").
Danksy hierdie benadering is die finale uitset in die meeste gevalle vlotter en nader aan 'n menslike vertaling as wat 'n SBS-gebaseerde vertaling ooit sou kon gewees het.
Hoe werk spraakvertaling?
Vertaler is ook in staat om spraak te vertaal. Hierdie tegnologie word blootgestel in die Translator live-funksie (http://translate.it), die Translator-toepassings, Skype Translator en word ook aanvanklik slegs beskikbaar gestel via die Skype Translator-funksie en in die Microsoft Translator-toepassings op iOS en Android, is hierdie funksionaliteit nou beskikbaar vir ontwikkelaars met die nuutste weergawe van die oop REST-gebaseerde API wat op die Azure-portaal beskikbaar is.
Alhoewel dit met die eerste oogopslag na 'n reguit proses kan lyk om 'n spraakvertalingstegnologie uit die bestaande tegnologiese stene te bou, het dit baie meer werk geverg as om bloot 'n bestaande "tradisionele" mens-tot-masjien-spraakherkenningsenjin by die bestaande teksvertaling een in te prop.
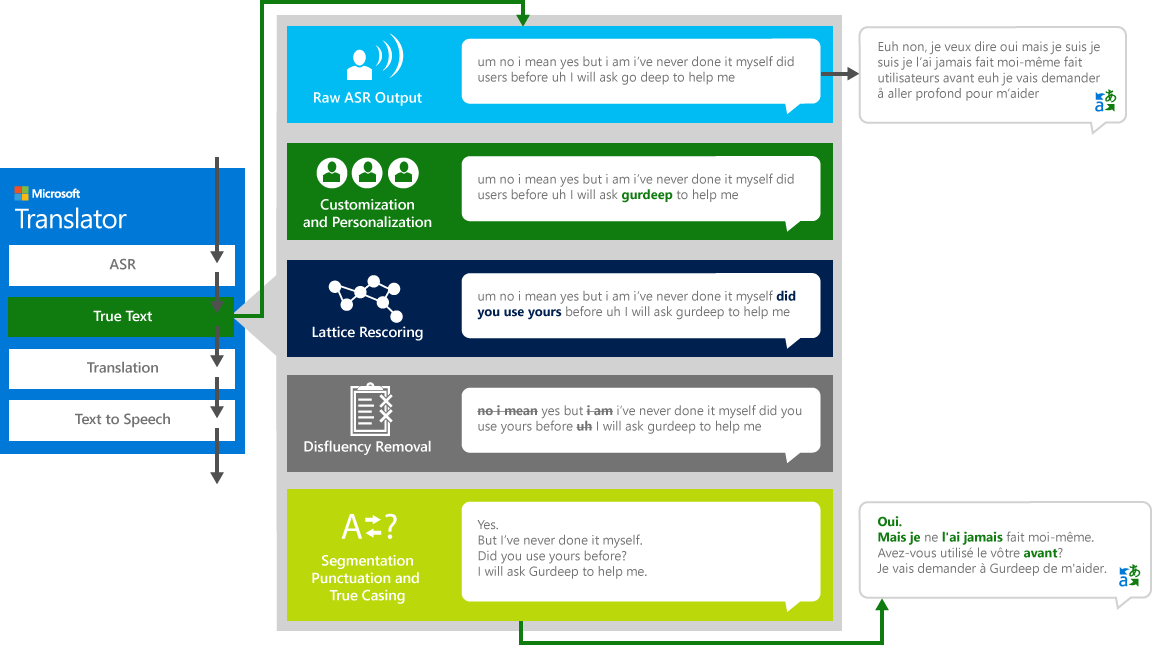
Om die "bron" -toespraak van een taal na 'n ander "teikentaal" behoorlik te vertaal, gaan die stelsel deur 'n vierstapproses.
- Spraakherkenning, om klank in teks om te skakel
- TrueText: 'n Microsoft-tegnologie wat die teks normaliseer om dit meer geskik vir vertaling te maak
- Vertaling deur die teksvertalingsenjin hierbo beskryf, maar op vertaalmodelle wat spesiaal ontwikkel is vir werklike gesproke gesprekke
- Teks-na-spraak, indien nodig, om die vertaalde klank te produseer.

Outomatiese spraakherkenning (ASR)
Outomatiese spraakherkenning (ASR) word uitgevoer met behulp van 'n neurale netwerk (NN) stelsel wat opgelei is om duisende ure se inkomende klankspraak te ontleed. Hierdie model is opgelei in mens-tot-mens-interaksies eerder as mens-tot-masjien-opdragte, wat spraakherkenning lewer wat geoptimaliseer is vir normale gesprekke. Om dit te bereik, is baie meer data nodig, sowel as 'n groter DNN as tradisionele mens-tot-masjien-ASR's.
Kom meer te wete oor Microsoft se toespraak met teksdienste.
TrueText
As mense wat met ander mense gesels, praat ons nie so perfek, duidelik of netjies soos ons dikwels dink ons doen nie. Met die TrueText-tegnologie word die letterlike teks getransformeer om gebruikersvoorneme nader te weerspieël deur spraakverskille (vulwoorde), soos "um"s, "ah"s, "and"s, "like"s, stutters en herhalings, te verwyder. Die teks word ook meer leesbaar en vertaalbaar gemaak deur sinsbreuke, behoorlike leestekens en hoofletters by te voeg. Om hierdie resultate te bereik, het ons die dekades se werk aan taaltegnologieë gebruik, wat ons van Translator ontwikkel het om TrueText te skep. Die volgende diagram beeld deur middel van 'n werklike voorbeeld die verskillende transformasie uit wat TrueText werk om hierdie letterlike teks te normaliseer.
Vertaling
Die teks word dan vertaal in enige van die Tale en dialekte ondersteun deur Vertaler.
Vertalings wat die spraakvertaling-API (as ontwikkelaar) of in 'n spraakvertalingsprogram of -diens gebruik, word aangedryf met die nuutste neurale netwerkgebaseerde vertalings vir al die spraakinvoerondersteunde tale (sien hier vir die volledige lys). Hierdie modelle is ook gebou deur die huidige, meestal geskrewe teks-opgeleide vertaalmodelle uit te brei, met meer gesproke tekskorpora om 'n beter model vir gesproke gesprekstipes vertalings te bou. Hierdie modelle is ook beskikbaar deur die "spraak" standaard kategorie van die tradisionele teksvertaling-API.
Vir enige tale wat nie deur neurale vertaling ondersteun word nie, word tradisionele SBS-vertaling uitgevoer.
Teks na spraak
As die doeltaal een van die 18 ondersteunde teks-na-spraak is Tale, en die gebruiksgeval vereis 'n klankuitset, die teks word dan omgeskakel in spraakuitset met behulp van spraaksintese. Hierdie stadium word weggelaat in spraak-na-teks-vertaalscenario's.
Kom meer te wete oor Microsoft se teks na spraakdienste.
Navorsing
Kyk na die mees onlangse navorsingsartikels van die Microsoft Translator-span.



