

How Hotpatching on Windows Server is changing the game for Xbox
Learn how Microsoft has been using Hotpatch with Windows Server 2022 Azure Edition to substantially reduce downtime for SQL Server databases.



This post was authored by Subhasish Bhattacharya, Program Manager, Windows Server.
In the past, in a world of reliable but expensive SANs, an aggressive high-availability strategy designed to fail fast was most optimal. The health of the system would be closely monitored to detect issues and react quickly and swiftly. This minimized downtime when catastrophic failures occurred.
In today’s cloud-scale environments, commonly comprising of commodity hardware, transient failures have become more common than hard failures. These transient compute and storage failures in commodity hardware are triggered by common events such as switch reset, packet loss, latency, and spanning tree convergence. In this new world, reacting aggressively to handle transient failures can cause more downtime than it prevents.
The storage and compute stack in Windows Server 2016 has been designed to optimize both high availability and resiliency. In a Software Defined Datacenter, we must assume infrastructure will break and it is imperative that software is resilient. At the same time, it is not acceptable to have degraded Virtual Machine (VM) availability.
Windows Server 2016 introduces increased VM resiliency features to address both:
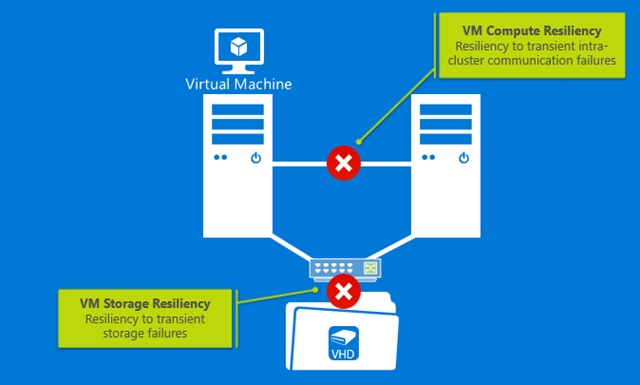
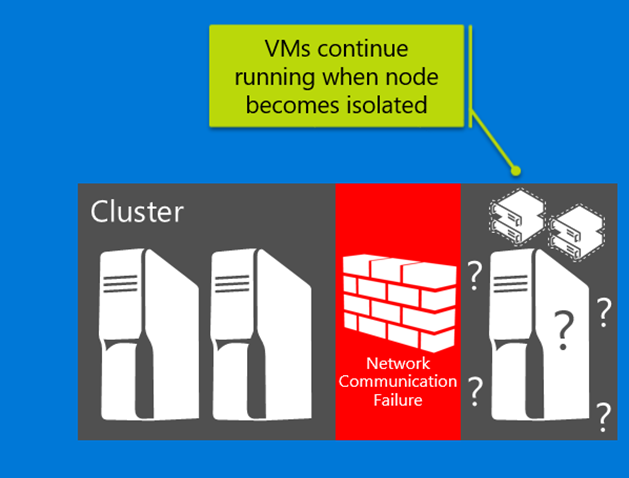
Transient network failures impede intra-cluster communication for your private cloud. This results in cluster nodes being removed from active membership in a cluster. In Windows Server 2016, your cluster is resilient to intra-cluster communication failures. This resiliency is achieved by the following:
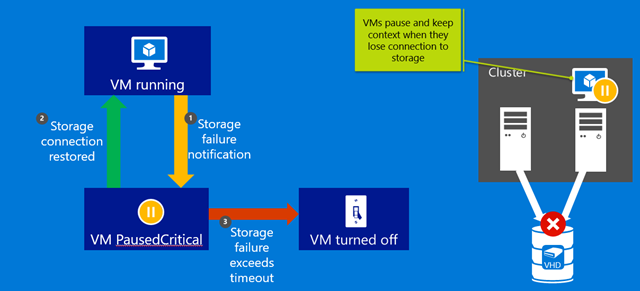
A transient storage failure results in a VM being unable to access its underlying VHDX file since read or write requests to disk fail. In Windows Server 2016, a VM is able to seamlessly detect and be resilient to such transient failures as follows:
To try this new feature in Windows Server 2016, download the Technical Preview. For additional details, see the feature blog posts for compute and storage VM resiliency.
Check out the series:
– #01 Cluster OS Rolling Upgrade
– #02 VM Load Balancing
– #03 Stretched Clusters
– #04 Workgroup and multi-domain clusters
Learn how Microsoft has been using Hotpatch with Windows Server 2022 Azure Edition to substantially reduce downtime for SQL Server databases.

One common theme stood out throughout Microsoft Ignite 2023: the potential of AI is becoming reality, and it's happening right now.

October 10th, 2023 marks the end of support date for Windows Server 2012/R2 and we want to outline options for customers to stay protected and compliant.