
Traduction automatique
Qu'est-ce que la traduction automatique?
Les systèmes de traduction automatique sont des applications ou des services en ligne qui utilisent des technologies d'apprentissage automatique pour traduire de grandes quantités de texte depuis et vers l'une ou l'autre de leurs langues prises en charge. Le service traduit un texte «source» d'une langue à une langue «cible» différente.
Bien que les concepts derrière la technologie de traduction automatique et les interfaces à utiliser, il sont relativement simples, la science et les technologies derrière elle sont extrêmement complexes et rassemblent plusieurs technologies de pointe, en particulier, l'apprentissage approfondi ( intelligence artificielle), Big Data, linguistique, Cloud Computing et API Web.
Depuis le début des années 2010, une nouvelle technologie de l'intelligence artificielle, Deep Neural Networks (alias Deep Learning), a permis à la technologie de la reconnaissance vocale pour atteindre un niveau de qualité qui a permis à l'équipe de Microsoft Translator de combiner la reconnaissance vocale avec ses technologie de traduction de texte de base pour lancer une nouvelle technologie de traduction vocale.
Historiquement, la technique principale d'apprentissage par machine utilisée dans l'industrie était la traduction automatique statistique (SMT). SMT utilise une analyse statistique avancée pour estimer les meilleures traductions possibles pour un mot, compte tenu du contexte de quelques mots. SMT a été utilisé depuis le milieu des années 2000 par tous les principaux fournisseurs de services de traduction, y compris Microsoft.
L'avènement de la traduction de la machine neurale (NMT) a provoqué un changement radical dans la technologie de traduction, entraînant des traductions de qualité beaucoup plus élevées. Cette technologie de traduction a commencé à déployer pour les utilisateurs et les développeurs dans le dernière partie de 2016.
Les deux technologies de traduction SMT et NMT ont deux éléments en commun:
- Les deux nécessitent de grandes quantités de contenu traduit pré-humain (jusqu'à des millions de phrases traduites) pour former les systèmes.
- Ils n'agissent pas comme des dictionnaires bilingues, traduisant des mots basés sur une liste de traductions potentielles, mais traduisent en fonction du contexte du mot utilisé dans une phrase.
Qu’est-ce que le traducteur?
Services de traducteur et de parole, qui font partie de la Services cognitifs collection d'API, sont des services de traduction automatique de Microsoft.
Traduction de texte
Translator est utilisé par les groupes Microsoft depuis 2007 et est disponible en tant qu’API pour les clients depuis 2011. Translator est largement utilisé au sein de Microsoft. Il est intégré aux équipes de localisation de produits, de support et de communication en ligne. Ce même service est également accessible, sans frais supplémentaires, à partir de produits Microsoft familiers tels que Bing, Cortana, Microsoft Edge, Bureau, SharePoint, Skype, et Yammer.
Le traducteur peut être utilisé dans des applications Web ou clientes sur n’importe quelle plate-forme matérielle et avec n’importe quel système d’exploitation pour effectuer la traduction linguistique et d’autres opérations liées à la langue telles que la détection de la langue, le texte à la parole ou le dictionnaire.
Tirant parti de la technologie de repos standard de l'industrie, le développeur envoie le texte source (ou audio pour la traduction vocale) au service avec un paramètre indiquant la langue cible, et le service renvoie le texte traduit pour le client ou l'application Web à utiliser.
Le service Translator est un service Azure hébergé dans les centres de données Microsoft et bénéficie de la sécurité, de l’évolutivité, de la fiabilité et de la disponibilité non-stop que les autres services cloud Microsoft reçoivent également.
Traduction vocale
La technologie de traduction vocale des traducteurs a été lancée fin 2014 à partir de Skype Translator, et est disponible en tant qu’API ouverte pour les clients depuis début 2016. Il est intégré dans la fonction Microsoft Translator en direct, Skype, skype réunion diffusée, et les applications Microsoft Translator pour Android et iOS.
La traduction vocale est désormais disponible par le biais de Microsoft Speech, un ensemble de services entièrement personnalisables pour la reconnaissance vocale, la traduction vocale et la synthèse vocale (texte à la parole).
Comment fonctionne la traduction de texte?
Il ya deux principales technologies utilisées pour la traduction de texte: l'héritage, la traduction automatique des statistiques (SMT), et la nouvelle génération un, neural machine translation (NMT).
Traduction automatique statistique
La mise en œuvre de la traduction statistique des machines (SMT) par Translator s’appuie sur plus d’une décennie de recherche en langage naturel chez Microsoft. Plutôt que d’écrire des règles artisanales pour traduire entre les langues, les systèmes de traduction modernes abordent la traduction comme un problème d’apprentissage de la transformation du texte entre les langues à partir de traductions humaines existantes et de tirer parti des progrès récents dans les statistiques appliquées et l’apprentissage automatique.
Ce qu’on appelle le « corpora parallèle » agit comme une pierre rosetta moderne dans des proportions massives, fournissant des traductions de mot, de phrase et d’idiomatique dans le contexte pour beaucoup de paires et de domaines de langue. Les techniques de modélisation statistique et les algorithmes efficaces aident l’ordinateur à résoudre le problème du déchiffrement (détection des correspondances entre la source et le langage cible dans les données de formation) et le décodage (trouver la meilleure traduction d’une nouvelle phrase d’entrée). Le traducteur unit le pouvoir des méthodes statistiques à l’information linguistique pour produire des modèles qui généralisent mieux et conduisent à des traductions plus compréhensibles.
En raison de cette approche, qui ne repose pas sur les dictionnaires ou les règles grammaticales, il fournit les meilleures traductions de phrases où il peut utiliser le contexte autour d'un mot donné par rapport à essayer d'effectuer des traductions de mots simples. Pour les traductions en un seul mot, le dictionnaire bilingue a été développé et est accessible par www.Bing.com/Translator.
Traduction de la machine neurale
Des améliorations continues à la traduction sont importantes. Cependant, l’amélioration des performances a plafonné avec la technologie SMT depuis le milieu des années 2010. En tirant parti de l’échelle et de la puissance du supercalculateur IA de Microsoft, en particulier la boîte à outils cognitive Microsoft, Translator offre désormais un réseau neuronal (LSTM) qui permet une nouvelle décennie d'amélioration de la qualité de la traduction.
Ces modèles de réseau neuronal sont disponibles pour toutes les langues de la parole par le biais du service de parole sur Azure et à travers le texte API en utilisant l’ID de catégorie «generalnn».
Les traductions de réseau neural diffèrent fondamentalement dans la façon dont elles sont exécutées comparées aux SMT traditionnels.
L'animation suivante décrit les différentes étapes de la traduction du réseau neuronal pour traduire une phrase. En raison de cette approche, la traduction prendra en contexte la phrase complète, contre seulement quelques mots de fenêtre coulissante que la technologie SMT utilise et produira plus fluides et traduits par l'homme des traductions à la recherche.
Sur la base de la formation de réseau neural, chaque mot est codé le long d'un vecteur de dimensions 500 (a) représentant ses caractéristiques uniques dans une paire de langue particulière (par exemple anglais et chinois). Sur la base des paires de langues utilisées pour la formation, le réseau neuronal définira lui-même ce que ces dimensions devraient être. Ils pouvaient encoder des concepts simples comme le sexe (féminin, masculin, neutre), le niveau de politesse (argot, occasionnel, écrit, formel, etc.), le type de mot (verbe, nom, etc.), mais aussi toute autre caractéristique non évidente telle que dérivée des données de formation.
Les étapes de la traduction des réseaux neuronaux passent par les suivantes:
- Chaque mot, ou plus précisément le vecteur de dimension 500 qui le représente, passe par une première couche de «neurones» qui l'encodera dans un vecteur de dimension 1000 (b) représentant le mot dans le contexte des autres mots de la phrase.
- Une fois que tous les mots ont été codés une fois dans ces vecteurs de dimension 1000, le processus est répété plusieurs fois, chaque couche permettant un meilleur réglage fin de cette représentation de la dimension 1000 du mot dans le contexte de la phrase complète (contrairement à SMT technologie qui ne peut prendre en considération une fenêtre de 3 à 5 mots)
- La matrice de sortie finale est ensuite utilisée par la couche d'attention (c'est-à-dire un algorithme logiciel) qui utilisera à la fois cette matrice de sortie finale et la sortie des mots précédemment traduits pour définir le mot, à partir de la phrase source, qui doit être traduit ensuite. Il utilisera également ces calculs pour supprimer potentiellement des mots inutiles dans la langue cible.
- La couche décodeur (translation), traduit le mot sélectionné (ou plus précisément le vecteur de dimension 1000 représentant ce mot dans le contexte de la phrase complète) dans son équivalent de langue cible le plus approprié. La sortie de cette dernière couche (c) est ensuite réinjectée dans la couche d'attention pour calculer le mot suivant de la phrase source qui doit être traduit.

Dans l'exemple illustré dans l'animation, le modèle de dimension 1000 de «la"va coder que le nom (Maison) est un mot féminin en français (la maison). Cela permettra la traduction appropriée pour "la"être"la"et non"le"(singulier, mâle) ou"les"(pluriel) une fois qu'il atteint le décodeur (traduction) couche.
L'algorithme d'attention calculera également, en se fondant sur le (s) mot (s) précédemment traduit (dans ce cas-ci "la"), que le prochain mot à traduire devrait être le sujet ("Maison") et non un adjectif ("Bleu"). Dans peut atteindre ce parce que le système a appris que l'anglais et le français inverser l'ordre de ces mots dans les phrases. Il aurait également calculé que si l'adjectif devait être «Grand"au lieu d'une couleur, qu'il ne doit pas les inverser ("la grande maison"= >"la grande maison").
Grâce à cette approche, le résultat final est, dans la plupart des cas, plus Fluent et plus proche d'une traduction humaine qu'une traduction basée sur SMT n'aurait jamais pu l'être.
Comment fonctionne la traduction vocale?
Le traducteur est également capable de traduire la parole. Cette technologie est exposée dans la fonction live De Traducteur (http://translate.it), les apps de traducteur, le traducteur de Skype et est également initialement rendu disponible seulement par la fonction de traducteur de Skype et dans les apps de Microsoft Translator sur iOS et Android, cette fonctionnalité est maintenant disponible aux développeurs avec la dernière version de l'Open API REST-based disponible sur le portail Azure.
Bien qu'il puisse sembler un processus simple à un premier coup d'oeil pour construire une technologie de traduction vocale de la technologie existante briques, il a fallu beaucoup plus de travail que de simplement brancher une existante «traditionnelle» de reconnaissance vocale de l'homme à la machine moteur à la traduction de texte existante.
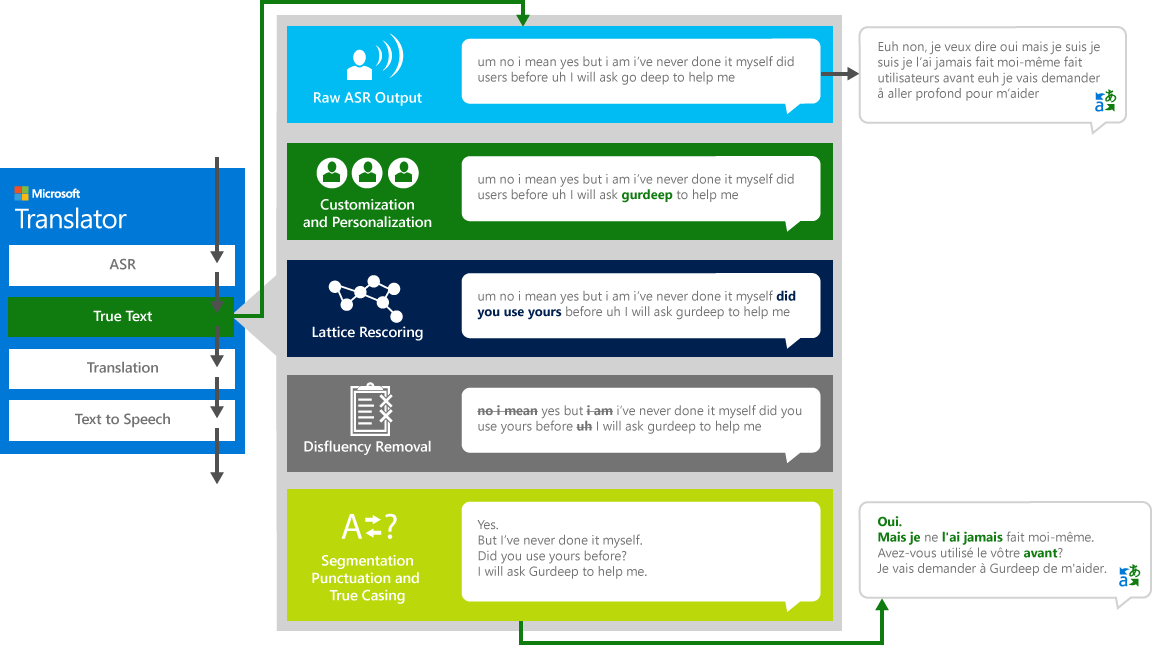
Pour traduire correctement le discours «source» d'une langue à une langue «cible» différente, le système passe par un processus en quatre étapes.
- Reconnaissance vocale, pour convertir l'audio en texte
- TexteVrai: une technologie Microsoft qui normalise le texte pour le rendre plus approprié à la traduction
- Traduction par le moteur de traduction de texte décrit ci-dessus mais sur des modèles de traduction spécialement développés pour les conversations parlées de la vie réelle
- Texte à la parole, si nécessaire, pour produire l'audio traduit.

Reconnaissance vocale automatique (ASR)
La reconnaissance vocale automatique (ASR) est effectuée à l'aide d'un système de réseau neural (NN) formé à l'analyse des milliers d'heures de la parole audio entrante. Ce modèle est formé sur des interactions homme-à-homme plutôt que des commandes d'homme à machine, produisant la reconnaissance vocale qui est optimisée pour des conversations normales. Pour ce faire, beaucoup plus de données sont nécessaires ainsi que d'une plus grande DNN que les ASR traditionnels de l'homme à la machine.
En savoir plus sur Le discours de Microsoft aux services de texte.
TexteVrai
En tant qu'humains conversant avec d'autres humains, nous ne parlons pas aussi parfaitement, clairement ou bien que nous pensons souvent que nous faisons. Avec la technologie TexteVrai, le texte littéral est transformé pour refléter plus étroitement l'intention des utilisateurs en supprimant la disfluencies vocale (mots de remplissage), tels que "um" s, "Ah" s, "et" s ", comme" s, bégaie, et les répétitions. Le texte est également rendu plus lisible et traduisable en ajoutant des coupures de phrase, la ponctuation appropriée, et la capitalisation. Pour atteindre ces résultats, nous avons utilisé les décennies de travail sur les technologies langagières, nous avons développé à partir de traducteur pour créer TexteVrai. Le diagramme suivant montre, à travers un exemple concret, que les diverses TexteVrai de transformation opèrent pour normaliser ce texte littéral.
Translation
Le texte est ensuite traduit dans l'une des langues et dialectes soutenu par Translator.
Les traductions à l'aide de l'API de traduction vocale (en tant que développeur) ou d'une application ou d'un service de traduction vocale sont alimentées par les plus récentes traductions de réseaux neuronaux pour toutes les langues prises en charge par l'entrée vocale (voir ici pour la liste complète). Ces modèles ont également été construits en élargissant le courant, la plupart du temps écrit des modèles de traduction formés, avec plus de corpus de texte parlé de construire un meilleur modèle pour les types de conversation parlée de traductions. Ces modèles sont également disponibles catégorie standard "Speech" de l'API de traduction de texte traditionnelle.
Pour toutes les langues non supportées par la traduction neurale, la traduction SMT traditionnelle est effectuée.
Texte à la parole
Si la langue cible est l'un des 18 texte-parole pris en charge Traduction, et le cas d'utilisation nécessite une sortie audio, le texte est ensuite converti en sortie vocale à l'aide de synthèse vocale. Cette étape est omise dans les scénarios de traduction vocale-texte.
En savoir plus sur Le texte de Microsoft aux services de la parole.
Recherche
Consulter les documents de recherche les plus récents de l'équipe Microsoft Translator.
- Traduction de la machine neurale universelle pour les langues de ressources extrêmement basses
- Atteindre la parité humaine sur le chinois automatique à la traduction de nouvelles en anglais
- Traduction de la langue parlée par les femmes appliquée à l'anglais-arabe
- Données synthétiques pour la traduction de la machine neurale des dialectes parlés



