
הבאת תרגום AI להתקני קצה עם מתרגם של Microsoft
בנובמבר 2016, מיקרוסופט הביאה את היתרון של תרגום מכונה AI, aka מכונת עצבית תרגום (NMT), למפתחים ומשתמשי קצה כאחד. בשבוע שעבר מיקרוסופט הביאה יכולת NMT לקצה הענן על ידי מינוף npu, מעבד AI ייעודי משולב לתוך ה מחבר 10, טלפון הדגל האחרון של Huawei. השבב החדש הופך את AI מופעל תרגומים זמין על המכשיר גם בהעדר גישה לאינטרנט, המאפשר למערכת לייצר תרגומים אשר איכותם היא שוה עם המערכת המקוונת.
כדי להשיג פריצת דרך, חוקרים ומהנדסים מ-Microsoft ו Huawei שיתפו פעולה בהתאמת התרגום העצבי לסביבת מיחשוב חדשה זו.
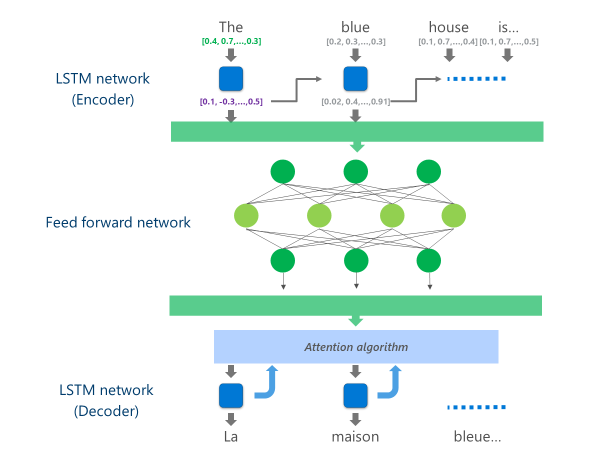
מערכות NMT המתקדמים ביותר כיום בייצור (כלומר, בשימוש בקנה מידה בענן על ידי עסקים ואפליקציות) משתמשים בארכיטקטורת רשת עצבית המשלבת שכבות מרובות של רשתות LSTM, אלגוריתם תשומת לב ושכבת תרגום (מפענח).
ההנפשה שלהלן מסבירה, באופן פשוט, כיצד הפונקציות האלה של רשת עצבית מרובת שכבות. לפרטים נוספים, עיין במהו דף תרגום מכונה"באתר של מתרגם מיקרוסופט.

ביישום NMT זה ענן, שכבות LSTM באמצע אלה צורכים חלק גדול של כוח המחשוב. כדי להיות מסוגל להפעיל NMT מלא במכשיר נייד, היה צורך למצוא מנגנון שיכול להפחית את עלויות החישוב הללו תוך שמירה, ככל האפשר, את איכות התרגום.
זה המקום שבו יחידת העיבוד העצבית של Huawei (NPU) נכנס למשחק. החוקרים והמהנדסים של מיקרוסופט ניצלו את ה-NPU, שתוכנן במיוחד להצטיין בחישובי AI בעלי השהיה נמוכה, לצורך העברת פעולות שהיו בלתי-מקדימות לתהליך על המעבד הראשי.
יישום
היישום זמין כעת ביישום מתרגם של Microsoft עבור Huawei Mate 10 מיטוב תרגום על-ידי טעינת משימות אינטנסיבית ביותר לחישוב NPU.
באופן ספציפי, יישום זה מחליף את שכבות הרשת LSTM האמצעיות באמצעות מערכת הפעלה עמוקהרשת עצבית מלאה. הרשתות העצביות עמוק הזנה-קדימה הם חזקים אך דורשים כמויות גדולות מאוד של חישוב בשל קישוריות גבוהה בין הנוירונים.
רשתות עצביות מסתמכות בעיקר על כפילויות מטריקס, פעולה שאינה מורכבת מבחינה מתמטית, אך יקרה מאוד כאשר מבוצעת בקנה מידה הנדרש עבור רשת עצבית עמוקה כזו. Huawei NPU מצטיין בביצוע אלה מטריקס מכפילי כפילויות בצורה בנפט מקביל. הוא גם יעיל למדי מבחינת ניצול כוח, איכות חשובה על התקנים מופעל על ידי סוללות.
בכל שכבה של רשת זו הזנה-קדימה, ה-NPU מחשב הן את פלט תא העצב הגולמי והן את הפעולות הבאות פונקציית ההפעלה ReLu ביעילות ובהשהיה מאוד נמוכה. על-ידי מינוף הזיכרון במהירות גבוהה ביותר ב-NPU, הוא מבצע חישובים אלה במקביל מבלי לשלם את העלות עבור העברת נתונים (כלומר, האטת הביצועים) בין ה-CPU ל-NPU.
לאחר שהשכבה הסופית של רשת ההזנה העמוקה הזאת מחושבת, למערכת יש ייצוג עשיר של משפט שפת המקור. ייצוג זה לאחר מכן הוזן באמצעות LSTM משמאל לימין "מפענח" כדי לייצר כל מילה שפת היעד, עם אלגוריתם תשומת לב זהה בשימוש בגירסה המקוונת של NMT.
כמו אנתוני אואה, מהנדס פיתוח תוכנה מנהל בצוות מתרגם Microsoft מסביר: "לקיחת מערכת הפועלת על שרתי ענן רבי-עוצמה במרכז נתונים והפעלת אותו ללא שינוי בטלפון נייד אינה אפשרות ממשית. למכשירים ניידים יש מגבלות של כוח מיחשוב, זיכרון ושימוש בצריכת חשמל שאין לפתרונות הענן. לאחר גישה ל-NPU, יחד עם מנופך אדריכלי אחר, אפשרה לנו לעבוד סביב רבים ממגבלות אלה ולעצב מערכת שיכולה לפעול במהירות וביעילות על המכשיר מבלי להתפשר על איכות התרגום."

היישום של מודלים אלה תרגום על שבבים NPU חדשני אפשרה ל-Microsoft ו Huawei לספק תרגום עצבי המכשיר באיכות הדומה לזה של מערכות מבוססות ענן גם כאשר אתה מחוץ לרשת.



